Four years ago I wrote a blog about using DuckDB with Power BI in DirectQuery. It got a fair number of likes on LinkedIn 🙂 along with the one comment I didn’t want to hear: how does this work in production? (Craig, if you’re reading this, you were right.)
Back then I thought the technology was the hard part and the rest would sort itself out. It didn’t.
The ODBC driver never really worked in any non-trivial setup. Filters didn’t push down, decimal precision was buggy. It has gotten better since, but two show stoppers remained:
DuckDB is in-process, so the driver is the database. There’s no warm, long-running session. Every query starts from scratch.
I don’t think those drivers can realistically be certified (personal opinion). And Power BI Service, or any hosted BI service for that matter, is not going to host an in-process engine for free. An on-prem data gateway is not really a good option either.
In 2026 things are way better. MotherDuck (DuckDB’s SaaS) shipped a PostgreSQL endpoint. Problem solved: Power BI speaks Postgres, and it works out of the box.
Then last week DuckDB released Quack. For my own sanity I’ll just call it “DuckDB Server.” It is just an extension; a single function call and you have a server !!
My first reaction was annoyance. Four years of waiting, and they shipped a proprietary wire protocol. I was hoping for pg wire. I want my driver to work. I don’t really care about a 2x improvement if nothing interoperates.
Luckily I was partially wrong. Within two days there was an ADBC driver from gizmodata/adbc-driver-quack, and, to my surprise, a Power BI custom connector from Curt Hagenlocher (think of him as the Linus of Power Query). my understanding it is a side project, not official Microsoft.
And somehow, the whole thing worked. It was beautiful.
But lesson learned from last time: this is experimental, with no guarantee the connector will ever be certified.
The main change from the 2022 post is that instead of pointing at parquet files, I’m pointing at a catalog and getting tables back, like an actual database instead of a pile of files and duckdb got way better.
High level architecture
OneLake Iceberg Catalog — OneLake exposes data as tables. You need three things:
Path to the Lakehouse/Warehouse: workspace_name/Lakehouse_name.Lakehouse
DuckDB + iceberg extension — reads the catalog and the underlying parquet over HTTPS.
Entra ID — az account get-access-token --resource https://storage.azure.com/ mints a short-lived bearer token. No service principal, no app registration. I have a script that grabs the token, and I opened duckdb-azure#170 hoping to make this much simpler.
DuckDB Endpoint — turns the engine into a TCP server on 127.0.0.1:9494, speaking DuckDB’s native wire protocol (whatever that means).
The ADBC Driver — Python client and Power BI share the same DLL, you need to manually install it from curt github page
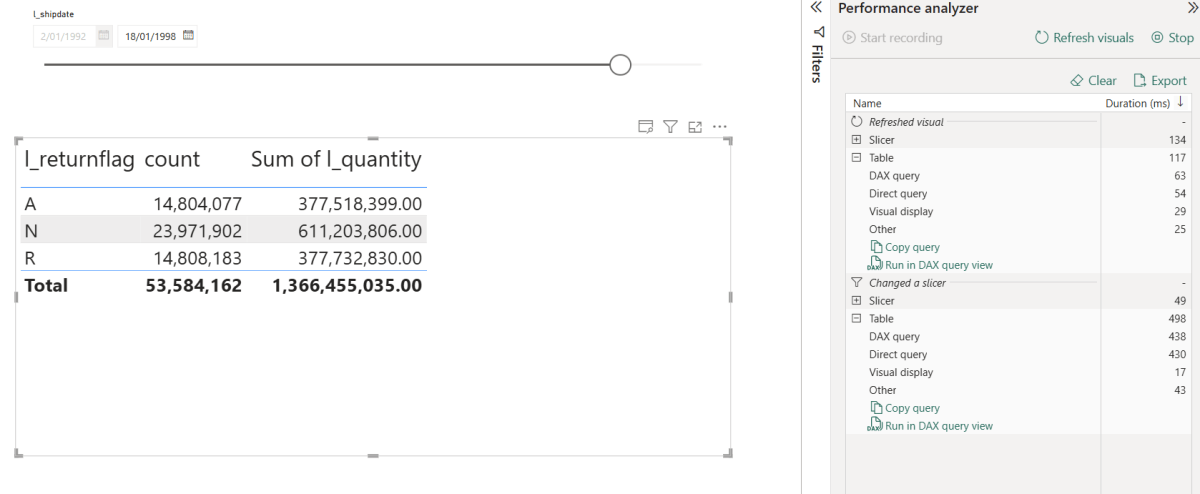
Let’s just share a video. Yes, 600M rows, warm run in my laptop
Python Notebook
TPC-H SF=10 (10 GB), 22 queries, run twice in the same session via client.ipynb. Numbers are seconds, copied straight from the notebook output.
Cold
Warm
Total
~5 min 29 s
~30 s
Cold time is dominated by parquet I/O over HTTPS from OneLake. Bandwidth and seek count, not CPU. Warm runs hit DuckDB’s in-process buffer cache, Onelake endpoint is in another continent and my internet provider is horrible 🙂
Optimization on this stack should target bytes read and seeks (codec, row-group size, predicate pushdown, range prefetch), not query plans.
This is exactly why server mode make sense, as the warm cache is shared by all client (notebook, Power BI, AI Agent)
Not production ready
The Entra token has a ~1h TTL. As far as I can tell, DuckDB has no way to auto-refresh tokens.
The driver is not certified, so it can’t be used in the service, if you want it added to PowerBI, create an idea in Fabric forum and vote
DuckDB Server is new. Don’t expect SQL Server maturity yet 🙂
DuckDB’s remote file cache is RAM only. When you restart DuckDB, you lose it and have to deal with the cold-run pain again and egress fees 😦
The DuckDB Azure extension is still pretty rough in places. To be fair, they’ve openly said they don’t have the bandwidth.
Hopefully it won’t take another four years to make this production ready.
Still, seeing DuckDB as a single binary serving a 600M row table to Power BI was genuinely fun. and The Iceberg catalog is awesome !!!
Microsoft Fabric lets you dynamically configure the number of vCores for a Python notebook session at runtime — but only when the notebook is triggered from a pipeline. If you run it interactively, the parameter is simply ignored and the default kicks in.
This is genuinely useful: you can right-size compute on a job-by-job basis without maintaining separate notebooks. A heavy backfill pipeline can request 32 cores; a lightweight daily refresh can get by with 2.
How It Works
Place a %%configure magic cell at the very top of your notebook (before any other code runs):
%%configure
{
"vCores":
{
"parameterName": "pipelinecore",
"defaultValue": 2
}
}
The parameterName field ("pipelinecore" here) is the name of the parameter you’ll pass in from the pipeline’s Notebook activity. The defaultValue is the fallback used when no parameter is provided — or when you run the notebook interactively.
Fabric supports vCore counts of 4, 8, 16, 32, and 64. Memory is allocated automatically to match.
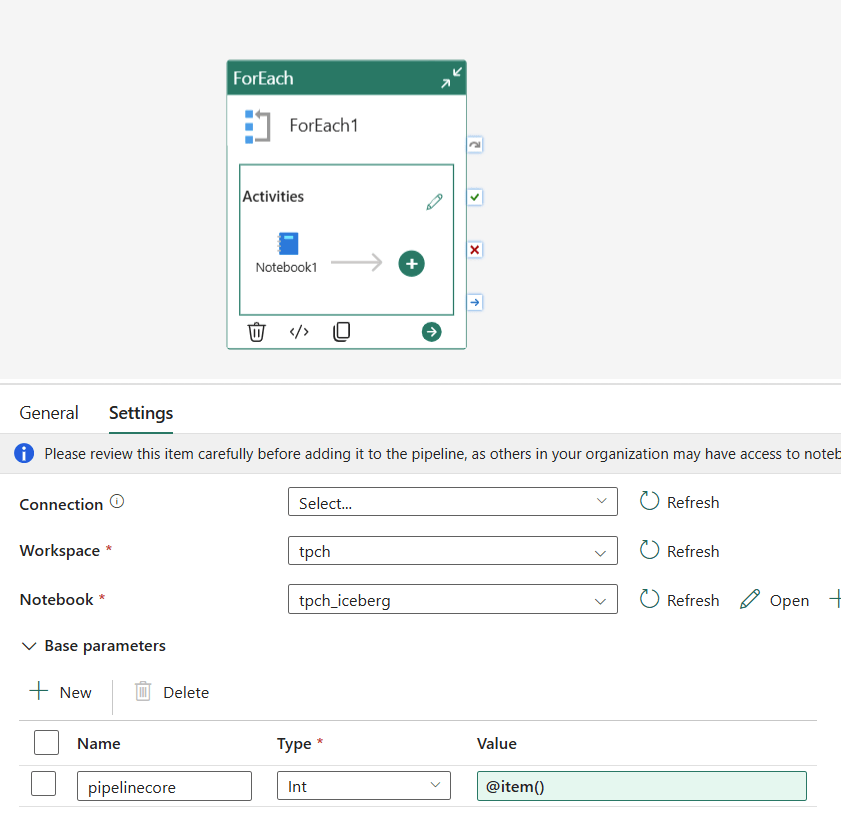
Wiring It Up in the Pipeline
In your pipeline, add a Notebook activity and open the Base parameters tab. Create a parameter named pipelinecore of type Int and set the value to @item().
When the pipeline runs, Fabric injects the value into %%configure before the session starts.
A Neat Trick: Finding the Right Compute Size
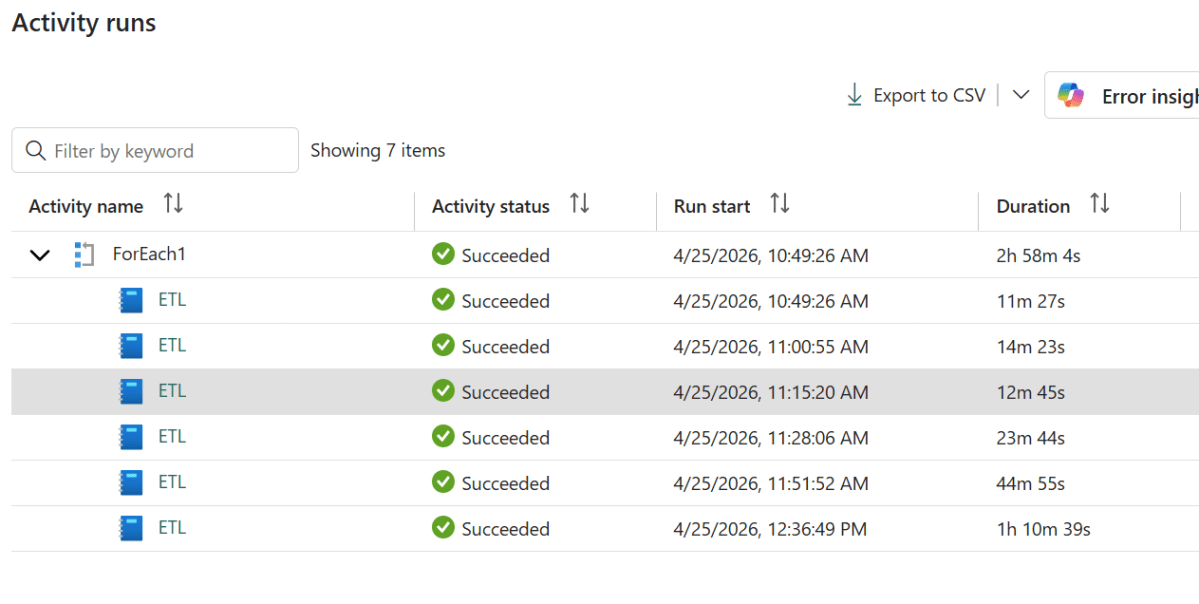
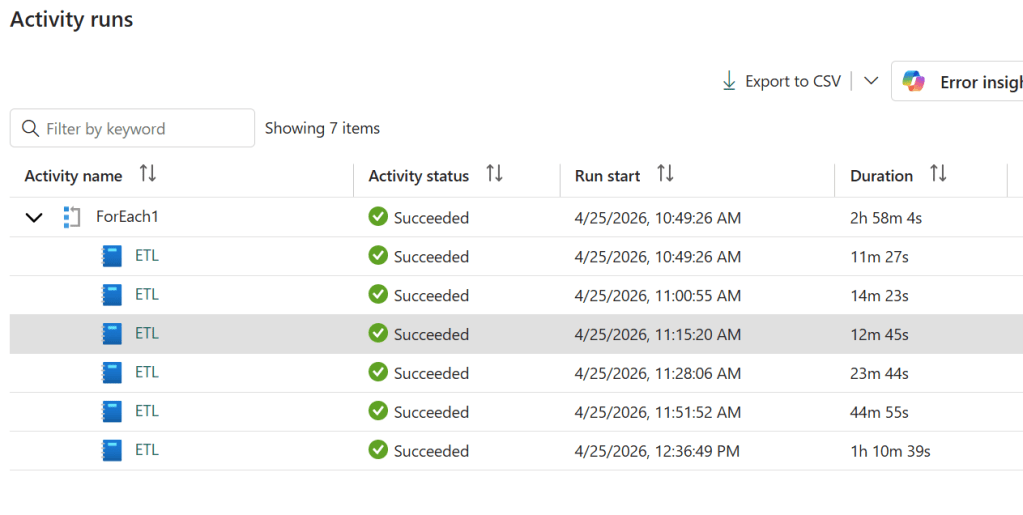
Because the vCore value is just a pipeline parameter, you can use a ForEach activity to run the same notebook across multiple core counts in sequence — great for benchmarking or profiling how your workload scales.
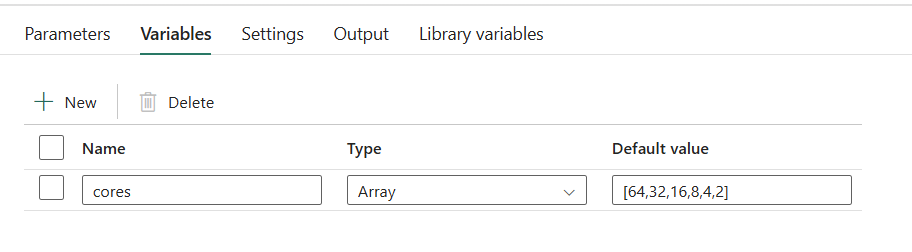
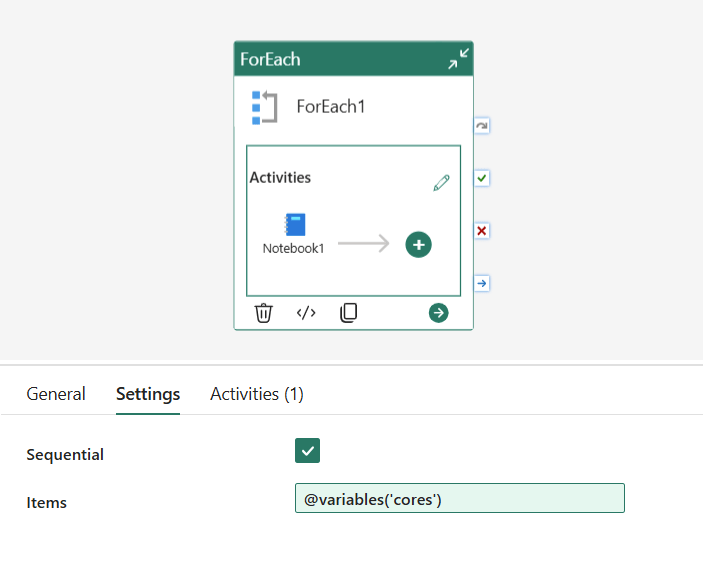
Set up a pipeline variable cores of type Array with a default value of [64,32,16,8,4,2]:
Then configure the ForEach activity with:
Items: @variables('cores')
Sequential: ✅ checked (so runs don’t overlap)
Concurrency: 1
Inside the ForEach, add a Notebook activity and set the pipelinecore base parameter to @item(). Each iteration picks the next value from the array and passes it to the notebook, so you get a clean sequential run at 64, 32, 16, 8, 4, and 2 cores.
and of course the time, always change it to a more sensible value
What the Numbers Say
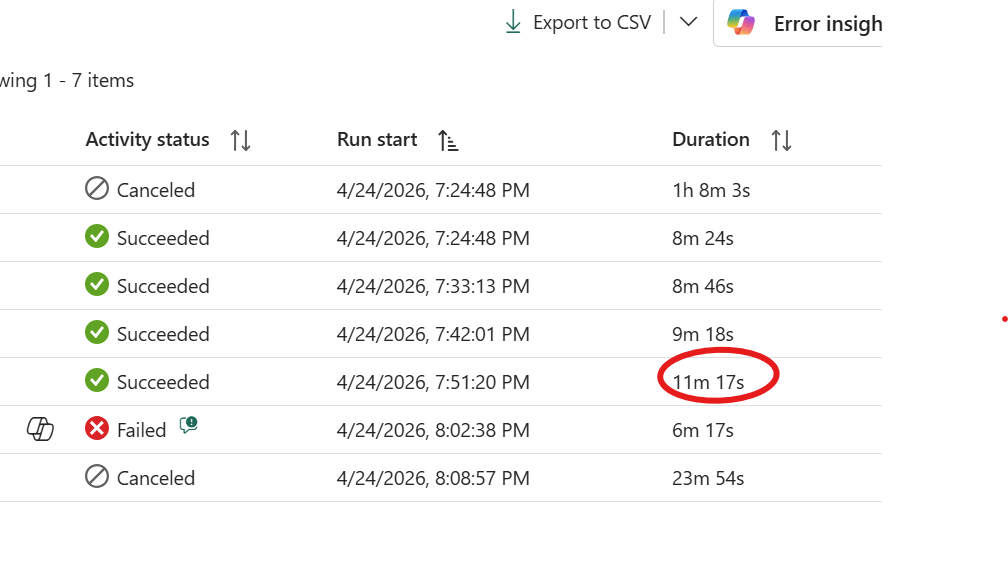
Running the previous workload across all supported core counts produced these results:
Cores
Duration
64
8m 24s
32
8m 46s
16
9m 18s
8
11m 17s
4
Failed
2
Canceled
The answer here is 8 cores. Yes, it’s about 2 minutes slower than 16 , but it’s half the compute. Going from 64 down to 8 cores costs you less than 3 minutes of runtime, which is a reasonable trade. Below 8 the workload simply falls apart. The sweet spot is not always the fastest run; it’s the point where adding more cores stops meaningfully improving the result.
btw for the CU consumption, the formula is very simple
nb of cores X 0.5 X active duration
Notice you will not be charged for startup duration.
Another Workload: 158 GB of CSV with DuckDB
To make this concrete, here’s a second run — an ETL notebook processing 158 GB of CSV files using DuckDB 1.4.4, the default version available in the Fabric Python runtime.
I’d pick 16 cores here. The jump from 16 to 64 saves you barely a minute and a half — well within the noise, as 16 actually outran 32 in this test. Below 8 cores the runtime climbs steeply, roughly doubling at each step. The reason is that 158 GB of CSV is largely an I/O-bound workload: DuckDB parallelises reads aggressively, but at some point you’re just waiting on storage, not on CPU. More cores stop helping.
Two things worth noting. First, 2 cores completed the job — which is remarkable given that 2 cores comes with only 16 GB of RAM for a 158 GB dataset. DuckDB’s out-of-core execution handled it, but at 1h 10m it pushed close to the limit. And that brings up the second point: OneLake storage tokens have a lifetime of around one hour. A run that creeps past that boundary risks losing access mid-execution. For a workload this size, anything below 8 cores is probably not worth the gamble.
A Word of Caution: Startup Overhead
Before you start bumping up core counts, there’s an important trade-off to keep in mind: anything above 2 cores adds several minutes of python runtime just to provision the session — and that startup time is included in your total duration. For large, long-running workloads it barely registers. For small ones it can easily dominate the total run time.
And most real-world workloads are small. A daily incremental load, a lookup refresh, a small aggregation — these often complete in under a minute of actual computation. If the session startup costs you 3 minutes and the work itself costs 30 seconds, more cores aren’t helping.
The default of 2 cores starts fast and is the right choice for the majority of jobs. Reach for more only when you’ve measured that the workload actually benefits from it.
Beyond Benchmarking: Dynamic Resource Allocation
The benchmarking pattern is useful, but the more powerful idea is using this in production. Because the vCore count is just a number passed through the pipeline, nothing stops a first stage of your pipeline from deciding what that number should be.
Imagine a pipeline that starts by scanning a data lake to count the number of files or estimate the volume of data to process. Based on that output, it computes an appropriate core count and passes it to the notebook that does the actual work — 4 cores for a small daily increment, 32 for a full month’s backfill, 64 for a one-off historical load. The notebook itself doesn’t change; the compute scales to the workload automatically.
This kind of adaptive orchestration is normally something you’d build a lot of custom logic around. Here it’s just a parameter.
The Catch: Interactive Runs Use the Default
This only works end-to-end when triggered from a pipeline. Running the notebook manually in the Fabric UI will silently use the defaultValue — there’s no error, the parameter just won’t be overridden. Keep that in mind when testing.
TL;DR : The high-end version of this problem is mostly solved. GPT-4 or Claude Opus paired with a mature proprietary semantic layer like Microsoft Power BI’s will handle natural language queries reliably in production, This blog is a much narrower use case: how do small language models (4B parameters, 4GB VRAM) perform when paired with open-source semantic layers? not great, not terrible as of April 2026 😦
Running a 4B model through an immature open-source semantic layer on a laptop GPU is not a production architecture — but it turns out to be a surprisingly useful lens for measuring fundamental SLM progress. How much reasoning capability fits in 4GB? How well do small models follow explicit constraints? Where do they break down under complexity?
Curiosity is a valid reason to run a benchmark. even for fun
The hardware constraint is real. An NVIDIA RTX A2000 Laptop has 4GB VRAM. Models above ~4GB Q4_K_M overflow into Windows virtual memory and run painfully slow. The practical ceiling is a 4B parameter model at Q4_K_M quantization.
The bet: give a small model a semantic model as its system prompt, and it should close the gap. Encode the domain knowledge — measure definitions, join rules, anti-patterns — so the model doesn’t have to infer them from a raw schema. Reduce the cognitive load, reduce the capability requirements, get closer to fast and correct.
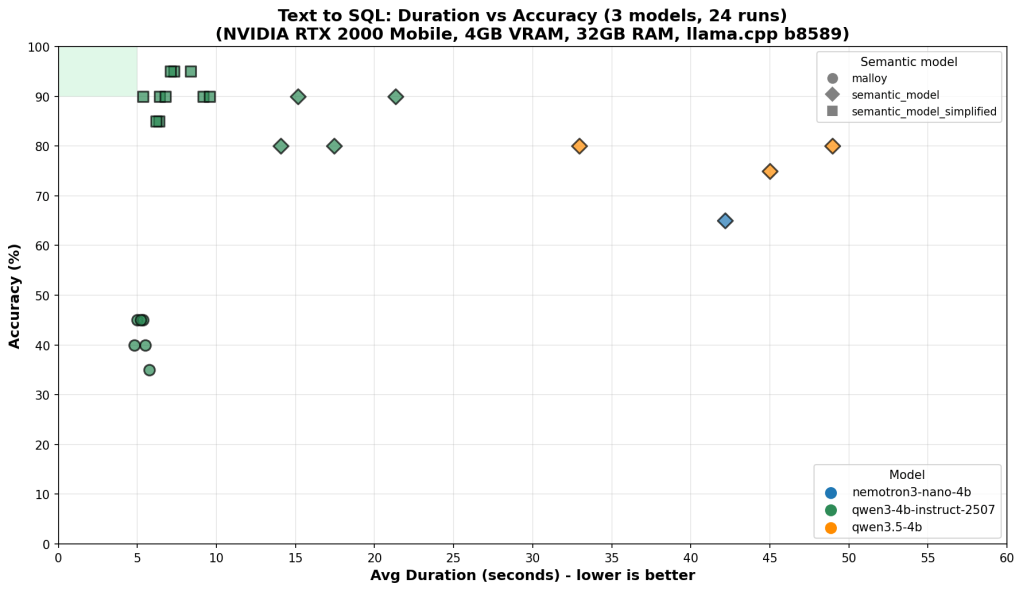
On the benchmark chart, that target lives in a small green rectangle in the top-left corner: high accuracy, low latency. This post is about what it takes to reach it — and why we’re still not reliably there.
What the Tests Measure
20 questions, graded from trivial to genuinely hard. Every answer is judged by exact result matching: every row must be correct, column order ignored, 0.5% numeric tolerance for floating point aggregations. Partial credit doesn’t exist.
The easy end (Q1–Q5): total revenue, total quantity sold, list of store names. Any model that can read a schema gets these right.
The hard end (Q18–Q20):
Return rate broken down by customer age group × weekend/weekday flag, joined through two fact tables
Brand-level year-over-year return rate change filtered by store state
Average net sales per transaction by item class and customer preferred flag
These require correctly combining multiple joins, conditional aggregations, and derived measures — and producing results that exactly match the reference answer.
Each run is plotted as accuracy vs. average duration per question. Speed matters because on 4GB VRAM, model size and inference cost are real constraints, not theoretical ones.
Results
One experiment: strip the full YAML semantic model (31KB, two explicit fact tables, extensive field metadata) down to a simplified version (23KB, single logical model, reduced noise). Less token budget spent on metadata, more focus on the patterns that matter.
Results across 3 models × 3 semantic model variants, 24 total runs:
Accuracy Speed Consistency
qwen3-4b + full model ~90% ~10s scattered
qwen3-4b + simplified ~90–95% ~5–8s tight → green box
nemotron + either 40–85% ~5–12s high variance regardless
qwen3.5-4b ~75–80% ~45–55s slow regardless
A capable LLM writing raw SQL can score well on individual runs — 90%+ accuracy on the best models. That sounds promising until you look at the consistency column. The same question, asked twice, can produce correct SQL one run and wrong SQL the next. That variance doesn’t go away with better prompting — it’s a fundamental property of using a probabilistic model for a deterministic task.
Simplifying the semantic model helped the strongest model converge into the green box — higher accuracy, faster, more consistent. For weaker models, variance stayed high regardless of which semantic model they received. The bottleneck had shifted from context quality to model capability.
You cannot simplify your way past a capability ceiling.
Why Raw LLM Breaks
The failure patterns are specific and instructive.
The CTE + FULL OUTER JOIN pattern. The semantic model is explicit: never join the two fact tables (store_sales and store_returns) directly. Always aggregate each separately in a CTE, then combine with FULL OUTER JOIN. Direct joins cause row multiplication. When a model gets this wrong, the result looks plausible — same columns, similar numbers — but every figure is wrong. Models violate this more than you’d expect, especially when the question doesn’t obviously signal that two fact tables are involved.
-- Wrong: direct join multiplies rows
SELECT s.s_store_name, SUM(ss_sales_price * ss_quantity) as total_sales,
SUM(sr_return_amt) as total_returns
FROM store_sales ss
JOIN store_returns sr ON ss.ss_item_sk = sr.sr_item_sk
JOIN store s ON ss.ss_store_sk = s.s_store_sk
GROUP BY s.s_store_name;
-- Right: aggregate each fact separately, then join the summaries
WITH sales AS (
SELECT ss_store_sk, SUM(ss_sales_price * ss_quantity) as total_sales
FROM store_sales GROUP BY ss_store_sk
),
returns AS (
SELECT sr_store_sk, SUM(sr_return_amt) as total_returns
FROM store_returns GROUP BY sr_store_sk
)
SELECT s.s_store_name,
COALESCE(sales.total_sales, 0),
COALESCE(returns.total_returns, 0)
FROM store s
LEFT JOIN sales ON s.s_store_sk = sales.ss_store_sk
LEFT JOIN returns ON s.s_store_sk = returns.sr_store_sk;
Literal instructions ignored. Q9 requires the raw flag values as group labels: 'Y' and 'N', not 'Preferred' and 'Non-Preferred'. The semantic model says this explicitly. LLMs substitute human-readable labels anyway — not because they misread the instruction, but because “Preferred / Non-Preferred” is the more natural output. The model understood what you wrote. It decided it knew better.
These failures share a structure: the semantic model content is correct, but LLM use of it is unreliable. The context is a hint, not a guarantee. You cannot build a production analytics system on a component whose failure modes are unpredictable. Reliability requires a deterministic layer — a compiler that enforces the patterns, not a model that may or may not follow them.
The Right Architecture: LLM Intent + Deterministic Compilation
The right split between LLM and algorithm is this: use the LLM for what only an LLM can do, and use deterministic code for everything else.
Natural language understanding is irreducibly fuzzy — only the LLM can map “show me underperforming stores last quarter” to the right intent. But once that intent is expressed as a structured query, everything downstream is deterministic. The join logic, the measure definitions, the SQL generation — these are mechanical translations that a compiler does perfectly, every time, for free. Running them through an LLM instead wastes token budget on a task that doesn’t need intelligence, while leaving less capacity for the task that does.
The ideal split: the LLM translates natural language into a compact domain-specific query expression. The compiler translates that into SQL. The LLM never touches raw schema column names; the compiler never sees ambiguous natural language.
A query compiler is the right architecture for this problem. It’s deterministic: the same query gives the same answer every time. It enforces join logic and measure definitions by construction, not by suggestion. You can build systems around deterministic limitations. You cannot build systems around random failures.
The DSL the LLM targets doesn’t need to be as simple as SELECT measure FROM model GROUP BY dimension. Users ask for year-over-year comparisons, cohort breakdowns, conditional aggregations — the DSL has to be expressive enough to capture these. But “expressive enough for analytics” is still a far smaller language than SQL. The LLM has a much easier job expressing intent in a constrained, familiar DSL than generating arbitrarily complex raw SQL correctly every time.
Why Open-Source Compilers Aren’t There Yet
The current open-source implementations just aren’t there yet.
Fact-first structural limitations. Most open-source semantic layers are fact-first by design: all queries anchor to the fact table. “List all stores” should return 8 stores. Running through boring-semantic-layer, it returns 6 — stores with no sales are excluded because they have no fact rows. This is not an edge case; it breaks a whole category of queries that any real analytics system must handle. (see example here: boring-semantic-layer #224) Dimension-first routing — queries that go directly to dimension tables when no fact aggregation is needed — is a fundamental capability gap.
Niche query languages. Malloy compiles high-level queries to SQL — the LLM writes Malloy, the compiler handles join logic. In theory this is exactly right: offload SQL generation to a trusted compiler, let the LLM express what to compute. In practice, LLMs have seen enormous amounts of SQL during training and almost no Malloy. Syntax errors were common, measure references wrong. The compiler generated correct SQL from correct Malloy — but getting correct Malloy out of the LLM was harder than getting correct SQL directly.
The proprietary proof that this architecture is buildable: Microsoft Power BI’s query planner handles multi-fact joins, period-over-period comparisons, and dimension-first routing reliably, backed by years of engineering investment. The open-source ecosystem isn’t there yet — and there’s no guarantee it gets there. The commercial incentive that drove Power BI and Looker to solve these problems doesn’t exist for open-source projects in the same way.
The Ceiling Is Implementation Quality
The semantic model doesn’t need to pre-declare every possible query pattern — that’s the point of having an LLM in the loop. “Sales performance in 2020 vs 2021” should be composable: the SLM reads the base measures (total_sales, date_dim keys, grain definitions) and constructs the year-over-year logic itself. Multi-period comparisons, cohort filters, conditional aggregations — these should emerge from creative composition of well-defined primitives, not from an ever-growing library of pre-baked templates. The semantic model’s job is to define what things mean; the SLM’s job is to figure out how to combine them. When that division holds, the system is genuinely expressive. When it breaks down — when the SLM can’t compose reliably from primitives.
Query planner quality degrades fast once you move beyond simple aggregations. The moment you introduce measures that ignore filter context — MAX(date) computed across the full table regardless of what the user filtered — the planner has to reason about predicate pushdown, materialization order, and query cost. A naive planner gets this wrong silently: it scans everything, computes the max, then filters afterward. A recent semi-proprietary semantic layer ( which should remain nameless), supposedly mature, did exactly this on a simple max date ignore filter measure , a sub-second query became a 30-second full table scan.
Where This Goes
There are two truths that can coexist here.
On one side, models are clearly improving. Techniques like aggressive quantization are delivering more reasoning capability within tight resource constraints, making smaller deployments increasingly viable. At the same time, the architectural pattern of separating LLM intent from deterministic compilation is sound. It reflects how the most reliable production systems are built today. In that sense, the open source ecosystem is moving in the right direction, even if current implementations are still maturing.
On the other side, there is a meaningful gap between something being buildable and being built correctly. That gap is easy to underestimate. What looks like a working system often breaks down under real-world conditions: edge cases, ambiguous semantics, inconsistent schemas, and the need for cost-aware execution planning.
Bridging that gap is not just a matter of better ideas. It requires depth. Years of iteration, careful handling of corner cases, and continuous refinement of query planning and semantic layers. Systems like Power BI or Looker did not arrive there by accident. They reflect sustained, focused investment in exactly these problems.
Whether the open source ecosystem will reach that same level of depth remains an open question. It is not a question of capability or intent, but of coordination, time, and sustained effort across a fragmented landscape.
So the current state is this: the architecture is directionally correct, but the hardest parts are still unresolved, and progress on those parts is inherently slow.
Edit: There is also a credible alternative trajectory. If smaller language models continue to improve, direct SQL generation may become reliable enough for a large class of use cases. In that world, the need for a semantic query compiler does not disappear, but it becomes less central, reserved for cases where correctness, governance, or performance guarantees truly matter.
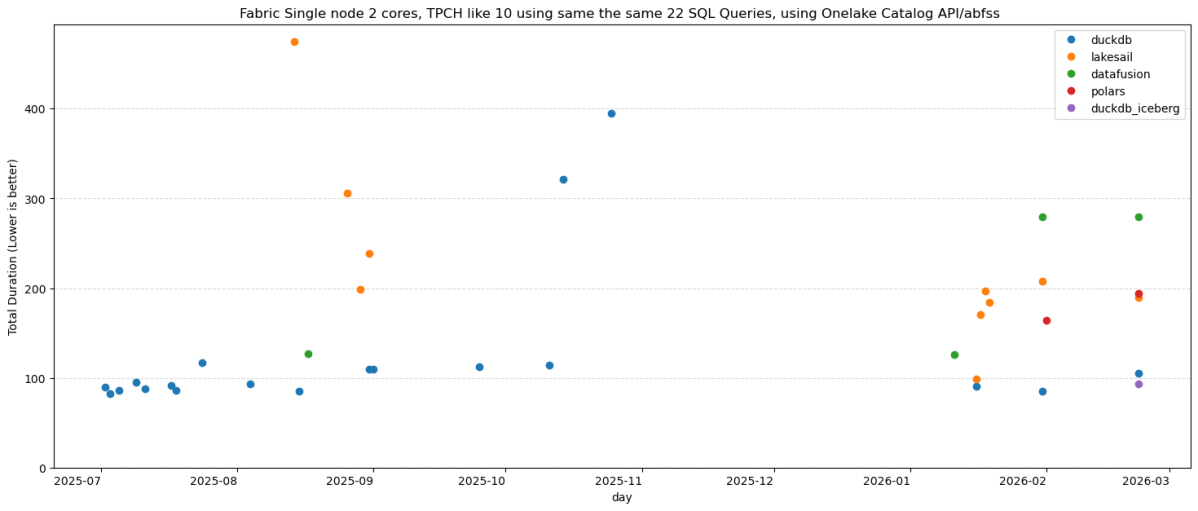
Same 22 TPC-H queries. Same Delta Lake data on OneLake (SF10). Same single Fabric node. Five Python SQL engines: DuckDB (Delta Classic), DuckDB (Iceberg REST), LakeSail, Polars, DataFusion , you can download the notebook here
unfortunately both daft and chdb did not support reading from Onelake abfss
DuckDB iceberg read support is not new, but it is very slow, but the next version 1.5 made a massive improvements and now it is slightly faster than Delta
They all run the same SQL now
All five engines executed the exact same SQL. No dialect tweaks, no rewrites. The one exception: Polars failed on Query 11 with
`SQLSyntaxError: subquery comparisons with '>' are not supported`
Everything else just worked,SQL compatibility across Python engines is basically solved in 2026. The differentiators are elsewhere.
Freshness vs. performance is a trade-off you should be making
importduckdb
conn=duckdb.connect()
conn.sql(f""" install delta_classic FROM community ;
Your dashboard doesn’t need sub-second freshness. Your reporting query doesn’t care about the last 30 seconds of ingestion. Declaring a staleness budget upfront – predictable, explicit – is not a compromise. It’s the right default for analytics.
Object store calls are the real bottleneck
Every engine reads from OneLake over ABFSS. Every Parquet file is a network call. It doesn’t matter how fast your engine scans columnar data in memory if it makes hundreds of HTTP calls to list files and read metadata before it starts.
– DuckDB Delta Classic (PIN_SNAPSHOT): caches the Delta log and file list at attach time. Subsequent queries skip the metadata round-trips.
– DuckDB Iceberg (MAX_TABLE_STALENESS): caches the Iceberg snapshot from the catalog API. Within the staleness window, no catalog calls.
– LakeSail: has native OneLake catalog integration (SAIL_CATALOG__LIST). You point it at the lakehouse, it discovers tables and schemas through the catalog. Metadata resolution is handled by the catalog layer, not by scanning storage paths, but it has no concept of cache, every query will call Onelake Catalog API
– Polars, DataFusion: resolve the Delta log on every query. Every query pays the metadata tax.
An engine that caches metadata will beat a “faster” engine that doesn’t. Every time, especially at scale.
How about writes?
You can write to OneLake today using Python deltalake or pyiceberg – that works fine. But native SQL writes (CREATE TABLE AS INSERT INTO ) through the engine catalog integration itself? That’s still the gap, lakesail can write delta just fine but using a path.
– LakeSail and DuckDB Iceberg both depend on OneLake’s catalog adding write support. The read path works through the catalog API, but there’s no write path yet. When it lands, both engines get writes for free.
– DuckDB Delta Classic has a different bottleneck: DuckDB’s Delta extension itself. Write support exists but is experimental and not usable for production workloads yet.
The bottom line
Raw execution speed will converge. These are all open source projects, developers read each other’s code, there’s no magical trick one has that others can’t adopt. The gap narrows with every release.
Catalog Integration and cache are the real differentiator. And I’d argue that even *reading* from OneLake is nearly solved now.
—
Full disclosure: I authored the DuckDB Delta Classic extension and the LakeSail OneLake integration (both with the help of AI), so take my enthusiasm for catalog integration with a grain of bias