TL;DR
Tableau Hyper manage to finish TPCH-SF110 using the free colab notebook, second is DuckDB using TPCH-SF20
Introduction
Saw a linkedin post where someone used my previous test for TPCH-SF10 and added Tableau Hyper Engine to the mix, the number were too good, that’s something that make me suspicious, I do like average results, extremes may just means a glitch or just a random good run, I had to see it for myself, and what a wonderful discovery, yes Hyper is extremely fast.
What is Hyper
Hyper is a DB originally developed in a german university and bought by Tableau in 2016 to replace their calculation engine, it is a full feature relational Database that support SQL, and not a specialized DB like PowerBI Vertipaq or Qlik Engine.
To be honest, I knew about Hyper before, The API was released in 2020 but I was very annoyed by a weird functionality where you need to double quote tables name and columns name, I was not too excited by the idea of apply this to a 900 LOC of SQL, luckily Romain was very kind and shared the modified SQ.
Edit : turn out double quote is not needed, probably the documentation was confusing, or I got the wrong impression.
To be clear Hyper Engine Package for Python is totally standalone and does not require Tableau, just PIP install tableauhyperapi , it is free to use but with proprietary license.

The Free Colab Test
I like using the free colab notebook to test Execution Engine (DuckDB,Data fusion, Polars etc) how an Engine behave in a constrained environment will give you a lot of useful intuition, and if it does not work well with limited resources, you will end up paying more in hardware cost because of software inefficiency, Design decisions matter.
TPCH-SF10
I started with the easy test, SF10, that’s 60 Million rows, Hyper performed nealy 2X faster than DuckDB, you can explained that Hyper had more time to mature compared to DuckDB, which is I think is only 3 years Old.

TPCH-SF30
It may sounds weird, but I really wanted to see an Engine finish the SF30 (180 Million rows)using the free colab notebook, it became like a personal obsession, DuckDB and Data fusion could not finish it as they got Out of memory error, and Hyper just run, it was not even trying hard.

TPCH-SF110
For no rational reason, I thought, let’s push the maximum and see what happen, the main table is 660 Million rows, in a free colab, and yes it was very slow, but did not crash and completed the test, that’s awesome !!

In-Memory vs SSD Disk
First let’s have a look at the file size, I had to delete the Parquet files to after loading just to save on the disk space.
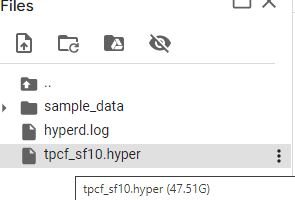
That’s 47 GB, the Free Colab VM has only 13 GB of RAM, an Engine like PowerBI Vertipaq would not work, as it needs first to load the whole file into RAM, before running any Queries, Hyper works differently, it stream the data straight from the disk, and will just read what’s required by the Query using only the column needs and the rows needed, basically it is extremely efficient at prunning data from the disk.
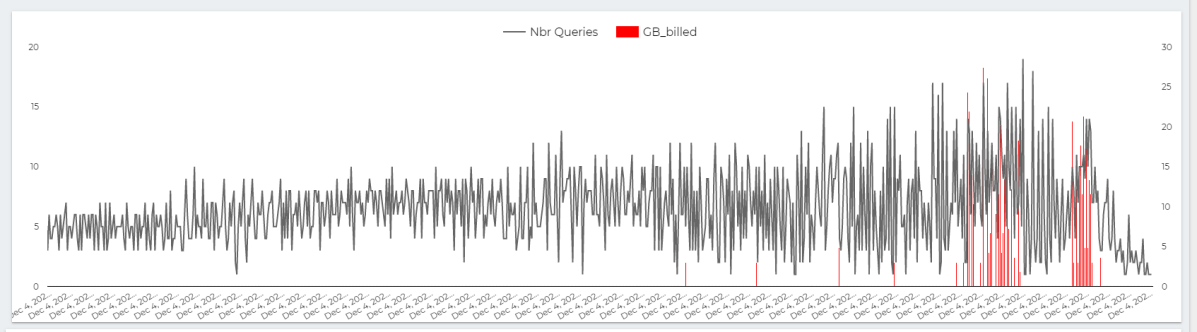
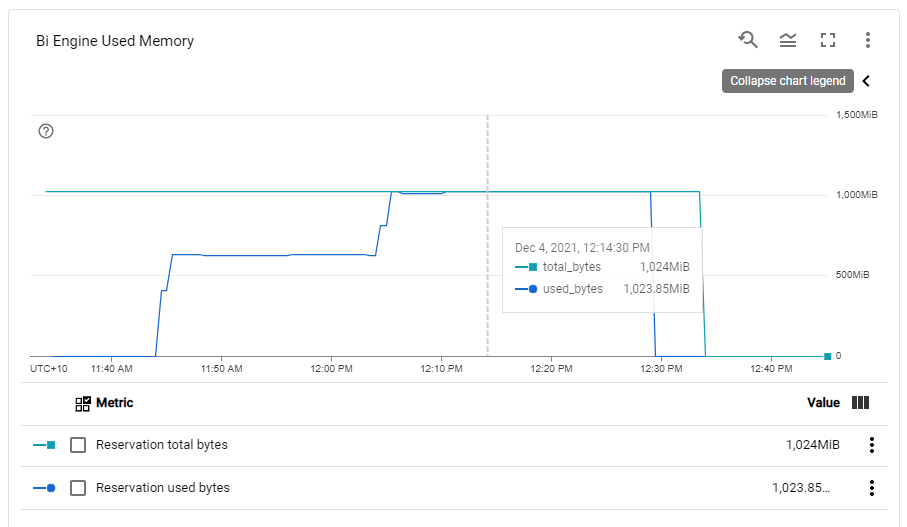
Now let’s see the second graph

I was watching the RAM usage and it is absolutely beautiful, most of the time it is less than 2 GB, in some Queries you can see the memory usage increase then Hyper decide to spill to disk, I was very worried about Query 21 ( The DB killer) and Hyper just smash it, like it is nothing, it was so efficient, you can nearly feel the engine, everything make sense, it was a joyful moment.
Some Observation
This is just my personal opinion having played with a couple of SQL Engine.
- You don’t need a specialist DB to handle Analytical Workload, a well designed columnar DB like Hyper and others is the perfect example.
- I love DuckDB, but there is still a lot of work to do, which is a good news, as we can still squeeze more juice from our laptops.
- I always believed PowerBI vertipaq to be the golden standard of analytical DB, I am not sure anymore, loading everything to RAM regardless of the Queries received seems a bit archaic these days, streaming from disk with only what’s required seems a better use of the hardware, and it scale better.
- I believe having a fast non trivial logical semantic layer that just generate SQL Queries to a DB maybe the right architecture for this era.