If you are on twitter or LinkedIn, Probably you heard already about the emergence of the “Modern” Data Stack and the triumph of the Cloud Data warehouse , this is all good, I use BigQuery BI Engine and I am amazed at what can be done with a little Bit of SQL.
Before I used to have an obsession with semantic model, I always thought you can’t have a decent analytical workflow without a proper multi fact semantic Model or what’s called now “Metric Store” , but I started changing my mind, flat wide table with multi grains are definitely ugly but they work , and storage is cheap, the point is ; there is a workaround it is not a showstopper, I think the issue is Further downstream.
To explain my point I will use PowerBI , and compare it to Apache Superset as an example, but the same can be said about other “Modern” tools too.
Analysis of Simple Table
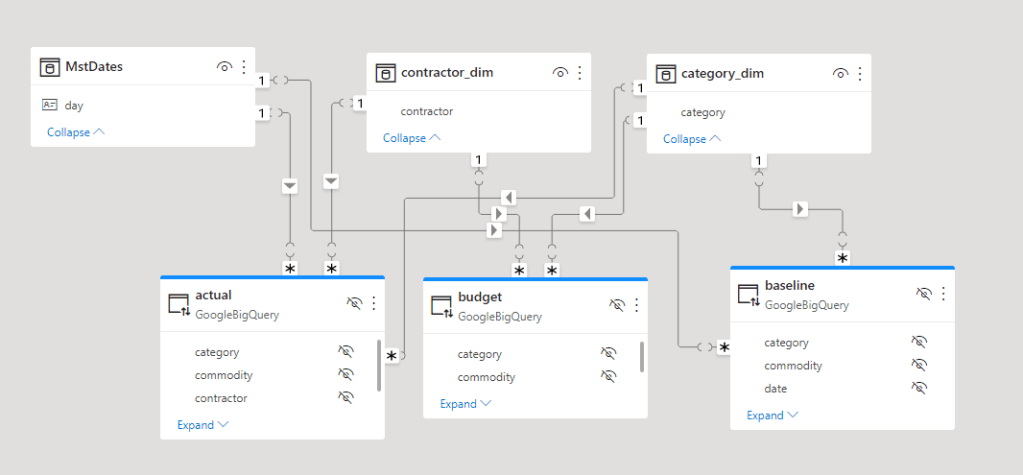
we will try to analyse only one table using Direct Query mode, the Table is loaded in an external Database, so no ETL , no OLAP, no data movement.
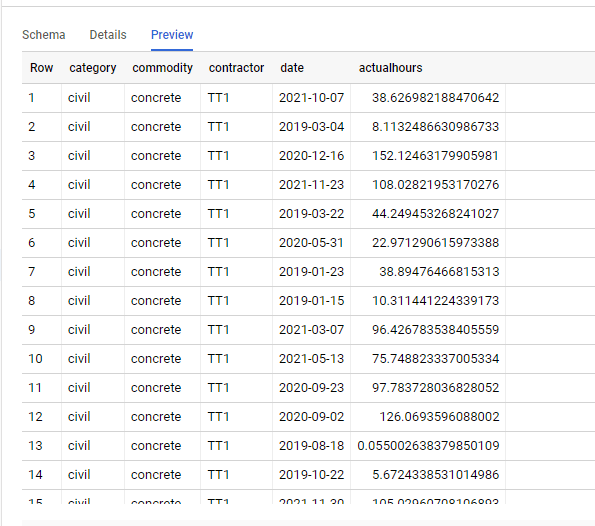
Then I created this simple Report
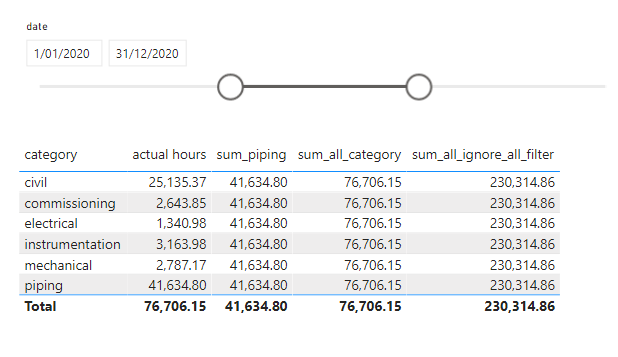
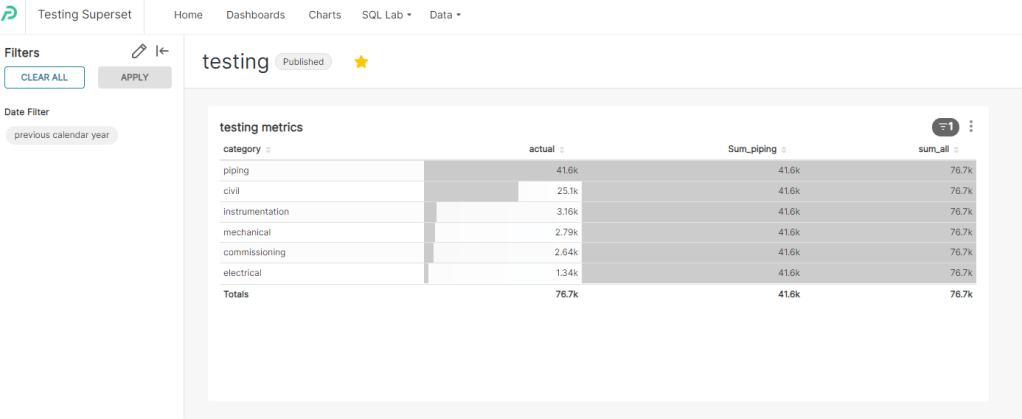
The main metric is Actual Hours, which is basically sum (Actual Hours) grouped by category, to my surprise, it was trivial to reproduce the first three metrics easily using Apache Superset
The SQL was not too complex

SQL Aggregate can not simply ignore filters
The Problem started with the Metric “sum_all_ignore_all_filter”, which basically sum the total hours and ignore any filters or grouping, In PowerBI, we use this syntax to get this behavior
sum_all_ignore_all_filter = CALCULATE(sum(actual[actualhours]),REMOVEFILTERS())
now let’s see the Query generated by Superset

As far as I know there is no way in SQL to add an aggregation and tell SQL to ignore the where clause , I presume you can create another Query and do a join, but I don’t think Superset permit this in the Metric definition, another solution is to use Parameters to pass the filter values, but then you will lose cross filter functionality.
Now you may wonder how PowerBI solved this Problem, how it is possible by just writing a generic Metric, it will always works regardless of filters or which dimension is used in group by ?
I know it is pretentious statement, but in my View this is the Ethos of the Product, this the killer feature of PowerBI
The idea is very simple, PowerBI DAX Engine will just send multiple SQL statement and assemble the results , the implementation is very complex involving two engines ( formula and Storage Engine), complex Query plan, and even a patent which I think it is worth reading , but obviously this is all hidden from the user.
here is a look at how the PowerBI process the report

And the Actual SQL Queries generated

Take Away
Obviously this is only my own understanding from an analyst point of View, but as far as I can see , all I can read is SQL is better than proprietary DSL, but no one explain how to handle very complex calculation that ignore filters and level of details using SQL and keeping the flexibility of Metrics, where they are just supposed to work.
The Previous example was just simple use case with one table, now imagine a complex model with multiple tables and Non additive Metrics.
I am not suggesting PowerBI is the only software that can do that, all what I am saying “Modern” consumption layer tools need to have more sophisticated SQL Generators.