Apache Superset is a very well known open source BI tool, I knew about it for the last couple of years, but was not thrilled by the idea of running a docker image on my laptop, recently though a new company Preset created by original author of the software start offering a cloud hosted service, basically they maintain the service and the consumer just use the software.
The pricing is very competitive, a free starter Plan with up to 5 users, then a pro plan for 20 $/Month/user ( the same as PowerBI PPU) and an Enterprise plan with custom pricing, kudos for the vendor for providing a free limited plan for users to learn and test.
The selling Point of Preset is very simple , it is open source software, so there is zero risk of vendor lock-in, if you are not happy with their service, you can always move your assets to another Provider or hosted yourself on-premise or in any cloud provider, this arguments is very attractive and make sense for a lot of customers , and companies like Red Hat have a good success using this business Model.
User interface

The user interface is simple and predictable which is a good thing, if you have used PowerBI or Data Studio you will feel at home.
Generally speaking there are two type of BI tools
- Integrated : The BI tools provide, ETL, Storage, Modeling and the viz layer , as an example : PowerBI, Tableau, Qlik , Data Studio
- Light : The BI tool scope is only Modeling and the viz layer, they need an External Database to host the data and run the SQL Query, Example Looker, Bipp etc ( I reference only the tool I personally used)
I guess the big assumption here, is that you have already a mature Data infrastructure which can be Queried from the same Data Base , Superset like Looker can not Query two DB in the same Dataset, The sweet spot for Superset is when all your data is hosted in a Cloud Data warehouse
Connecting to the Database
As usual I used BigQuery as my Data Source, the connection was pretty trivial to setup, although I could not figure out how to activate CSV upload
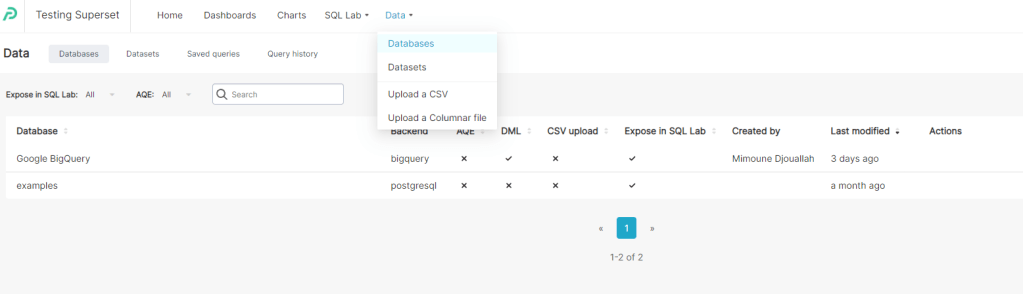
Building a Dataset
Dataset is the Data model it is the same concept as PowerBI with dimensions and Metrics (Measure), but it does not support relationships , you have to manually build a Query that join multiple tables or leverage a View in the Database , The metrics and dimension use SQL as calculation language.
One confusing aspect of the User interface; if you want to build a Dataset based on one table, you just click Data, Dataset then add Dataset, simple, but if you want to build it based on a SQL Query, you need to click on SQL Lab, then SQL Editor , you write the Query then save it as a dataset.
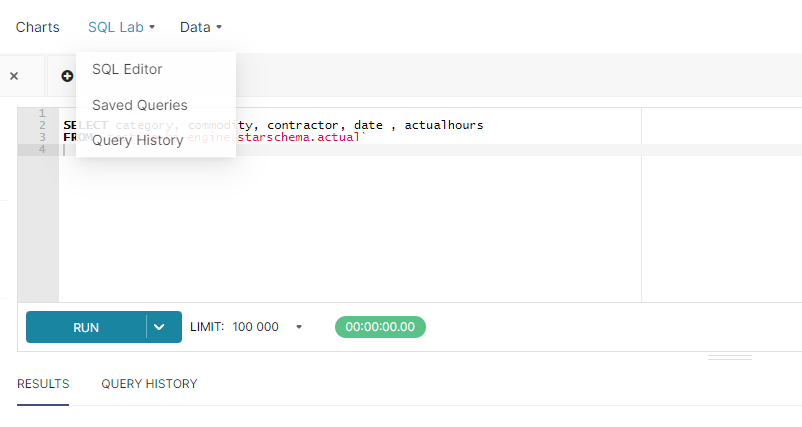
Example : Dataset based on A SQL Query and Parameter
I have a simple multi Fact semantic model in PowerBI, and usually used it as test case, 3 Facts with different grains and 3 dimension
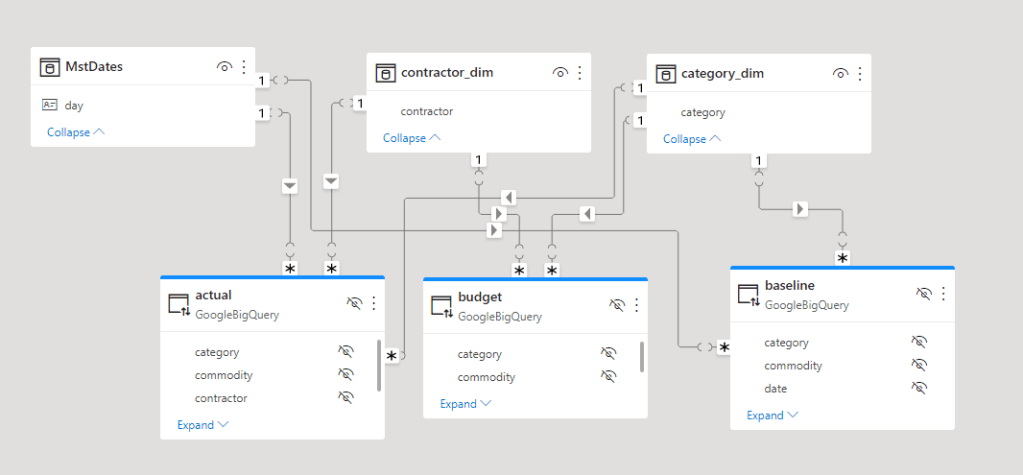
I add this SQL Query to generate the Dataset, Parameter is used to pass date as a filter, yes I am biased, I used PowerBI for so long, that writing SQL Query to return Dataset seems strange.
{% set param_Date = filter_values('day')[0] %}
SELECT category, commodity, actualhours , budgethours , forecast
FROM (
SELECT category, commodity , SUM(actualhours) AS actualhours
FROM `testing-bi-engine.starschema.actual`
WHERE date <= date(TIMESTAMP_MILLIS({{cache_key_wrapper(param_Date)}}))
GROUP BY category, commodity
) t2
FULL OUTER JOIN (
SELECT category, commodity , SUM(budgethours) AS budgethours
FROM `testing-bi-engine.starschema.budget`
GROUP BY category, commodity
) t3 USING(category, commodity)
FULL OUTER JOIN (
SELECT category, commodity , SUM(forecast) AS forecast
FROM `testing-bi-engine.starschema.baseline`
WHERE date <= date(TIMESTAMP_MILLIS({{cache_key_wrapper(param_Date)}}))
GROUP BY category, commodity
) t4 USING(category, commodity)

The metrics

The Columns

I am using BigQuery BI engine, one fact is 43 Million rows and another is 1 Million, and although Preset Cloud is hosted in AWS even with network transfer the experience is very smooth, as of this writing Publish to web is not supported yet, so all I can show is this GIF

Chart library
Apache Superset has a very decent visual library, the first I checked is Pivot table and it is not bad at all , my understanding cross filtering will be supported only on E Charts Viz

Take Away
Superset is a mature open source data consumption layer with an enterprise support provided by Preset Cloud, if you have a mature data infrastructure and you know SQL very well, then it is worth a shot, I suspect it will be very popular with tech savvy companies and startups.
Edit : added a new post about Superset SQL Metrics

One thing that disqualifies superset for me is lack of possibility to filter data by “human label” column and apply filter on technical id column. This is something that is so basic and not existing there… really strange …
LikeLike