TLDR, the report is https://nemtracker.github.io/, please note, my experience with BigQuery and Google stack is rather limited, this is just my own perspective as a business user .
Edit : 20 Sept 2019, Data Studio use now BI engine by default for connecting to BigQuery, now the report contains the historical data too.
I built already a dashboard that track AEMO Data using PowerBI, and it is nearly perfect except , the maximum update per day is 8 time, which is quite ok ( direct Query is not an option as it is not supported when you publish to web, actually it is support but rather slow) , but for some reason, I thought how hard would it be to build a dashboard that show always the latest Data.
Edit : 23 Sept 2019, actually now, my go to solution for near real time reporting is Google Data Studio, once you get used to real time time, you can’t go back.
The requirements are
- Very minimum cost, it is just a hobby
- Near Real time (the data is published every 5 minutes)
- Export to csv
- Free to share.
- Ideally not too much technical, I don’t want something to build from scratch.
I got some advices from a friend who works in this kind of scenario and it seems the best option is to build a web app with a database like Postgresql, with a front end in the likes of apache superset or Rstudio Shiny and host it in a cheap VM by digitalocean , which I may eventually do, but I thought let’s give BigQuery a try, the free tier is very generous, 1 TB of free Queries per month is more than enough, and Data Studio is totally free and by default use live connection.
Unlike PowerBI which is a whole self service BI solution in one package, Google offering is split to three separate streams, ETL, the data warehouse (Biguery) and the reporting tool (Data Studio), the pricing is pay per usage
For the ETL, Dataprep would be the natural choice for me,( the service is provided by Trifacta), but to my surprise, apparently you can’t import data from an URL, I think I was a bit unfair to Trifacta, the data has to be in google storage first, which is fine, but the lack of support for zip is hard to understand, at least in the type of business I work for, everyone is using zip

I tried to use Data fusion, but it involve spinning a new spark cluster !!!! , and their price is around 3000 $ per month !!!!!
I think I will stick with Python for the moment.
- The first thing you do after creating a new project in BigQuery is to setup cost control.
The minimum I could get for BigQeury is 0.5 TB per day

- The source files are located here, very simple csv file, compressed by zip, I care only about three fields
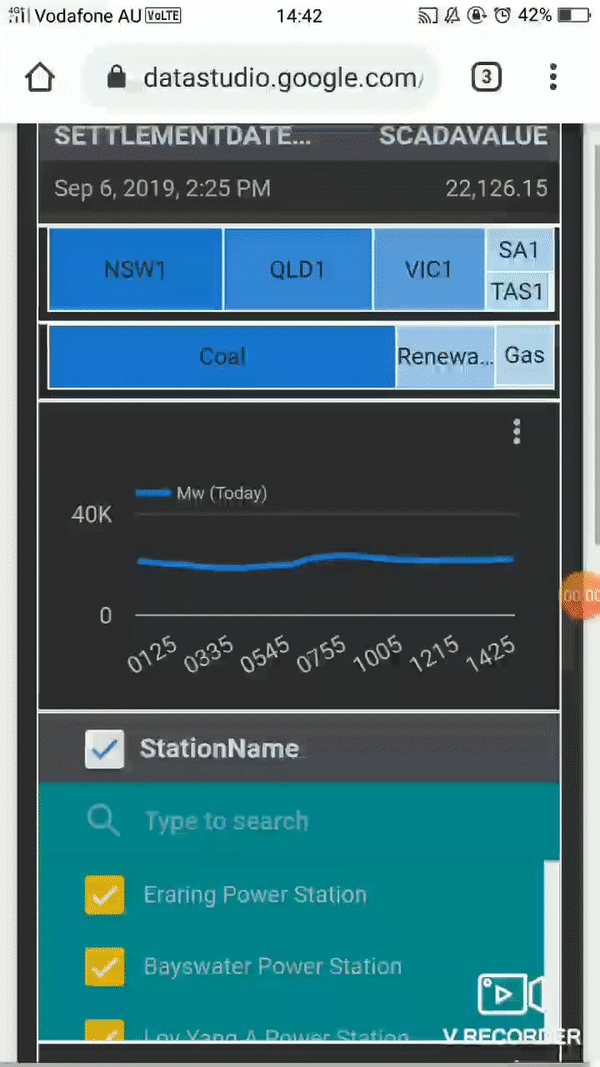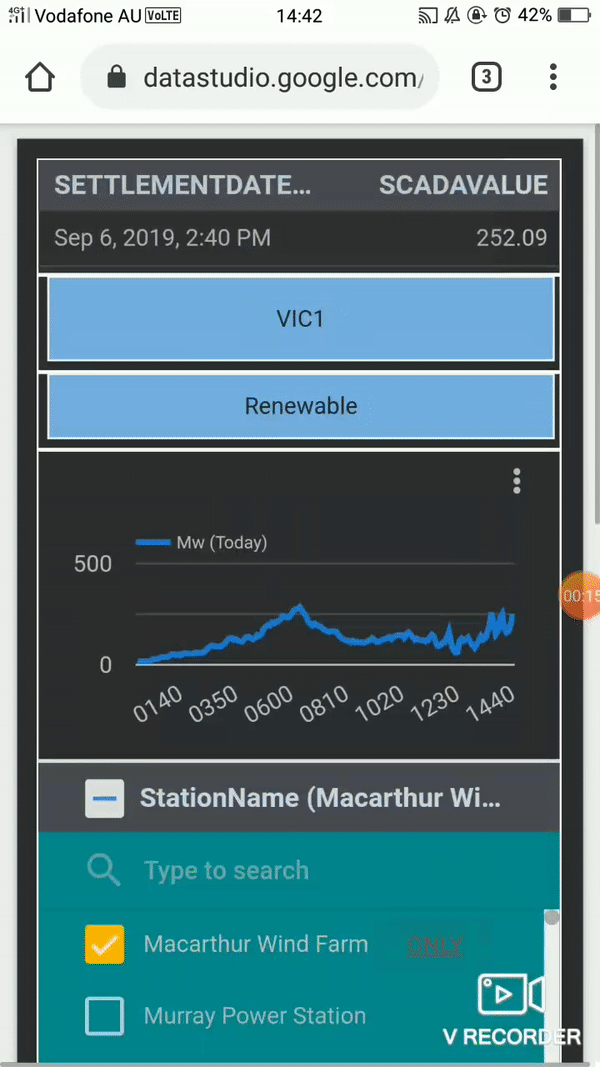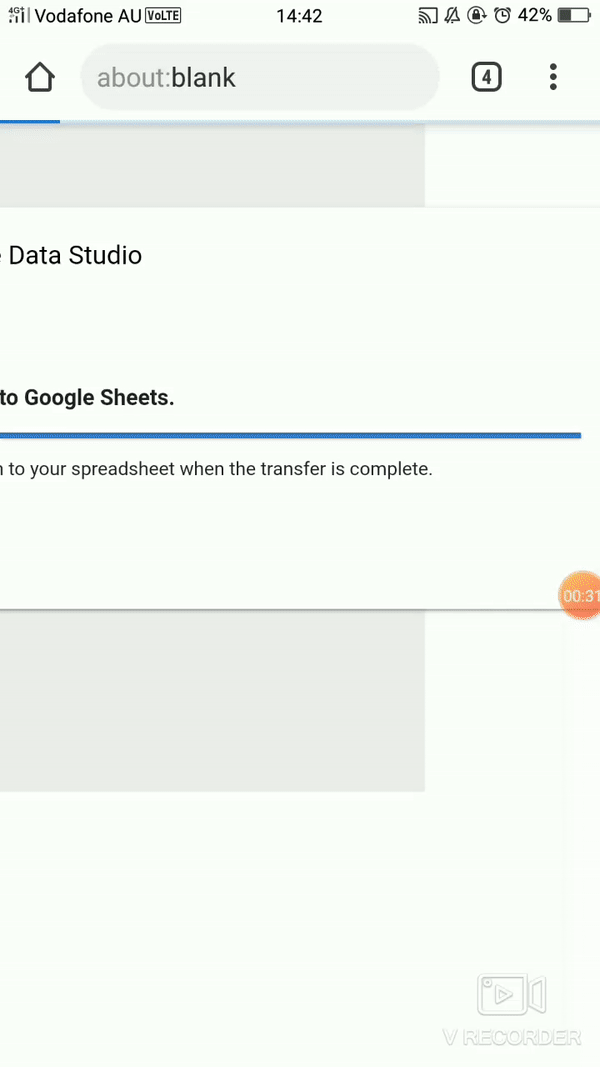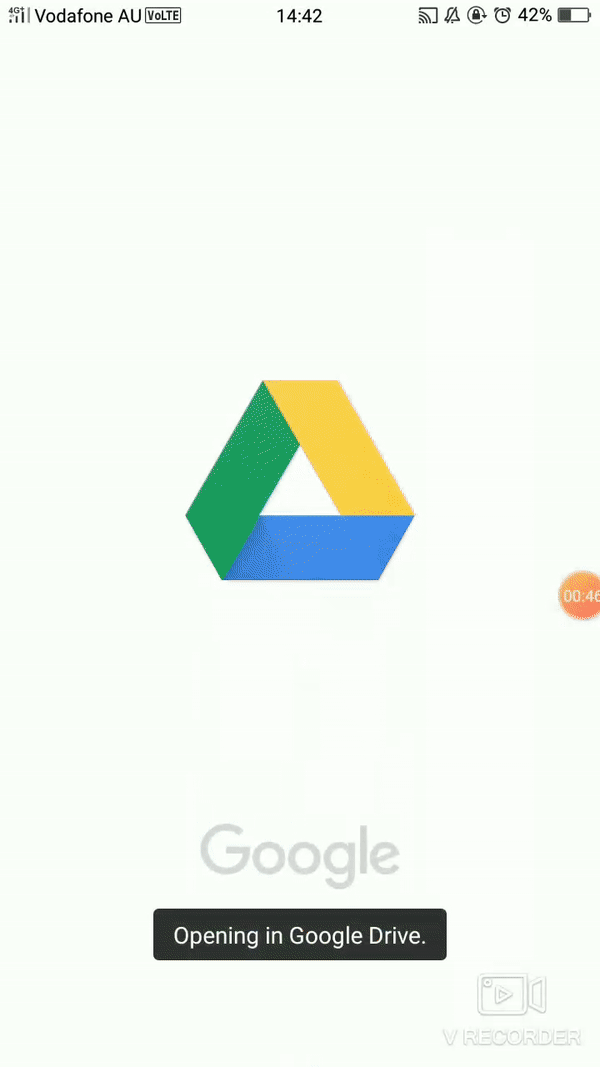
SETTLEMENT DATE : timestamp
DUID : Generator ID , ( power station, solar, wind farm etc)
SCADAVALUE : Electricity produced in Mw

- Add a table with partition per day and clustered by the field DUID

- Write a python script that load data to Bigquery,you can have a look at the code used here, hopefully I will blog about it separately

- Schedule the script to run every 5 minutes: I am huge fan of azure WebJob,
to be honest I tried to use Google function but you can’t write anything in the local folder by default, it seems the container has to be stateless but I just find it easy when I can write temporary data in the local folder (I have a limited understanding of Google function, that was my first impression anyway) ,now, I am using google functions and cloud Scheduler, Google functions provide a /tmp that you can write to it, it will use some memory resources.
- I added a dimension table that show a full Description for the generator id, region etc, I have the coordinates too, but strangely, Data Studio map visual does not support tiles!!!
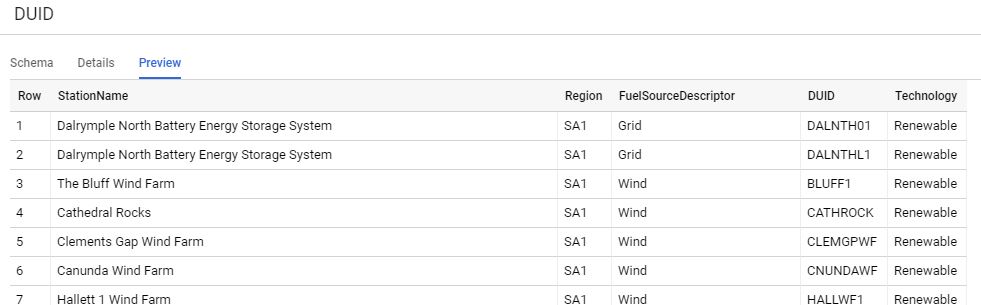
- Create a view that join the two tables and remove any duplicate, and filter out the rows where there is no production (SCADAVALUE =0), if there is no full Description yet for the generator id, use the id instead

Notice here, although it is a view, the filter per partition still works, and there is a minimum of 10 MB per table regardless of the memory scanned, for billing BigQuery used the uncompressed size !!
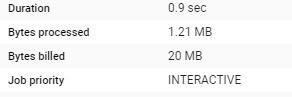
One very good thing though, the queries results are cached for 1 day, if you do the same query again, it is free!
- Create the Data Studio report : I will create two connections :
- live connection: pull only today data, every query cost 20 MB, as it is using only one date partition, (2 Tables), the speed is satisfactory, make sure to disactivate the cache

But to confuse everyone there two types of caches, see documentation here, the implication is sometimes you get different updated depending if your selection hit the cache or not, as the editor of the report, it is not an issue, I can manually click refresh, but for the viewer, to be honest, I am not even sure how it works, sometimes, when I test it with incognito mode, I get the latest data sometimes not.
- Import connection : it is called extract, it load the data to Data Studio in-memory database (it uses BI engine created by one of the original authors of multidimensional) , just be careful as the maximum that can be imported is 100 MB (non compressed), which is rather very small (ok it is free so I can’t complain really), once I was very confused why the data did not match, it turn out Data Studio truncate the import without warning, anyway to optimise this 100 MB, I extract a summary of the data and removed the time dimension and filtered only to the last 14 days, and I schedule the extract to run every day at 12:30 AM, notice today data is not included.

Note : Because both datasets use the same data source, cross filtering works by default, if using two different sources (let’s say, csv and google search, you need some awkward workaround to make it works)
- Voila the live report, 😊 a nice feature shown here (sorry for the gif quality) is the export to Sheet
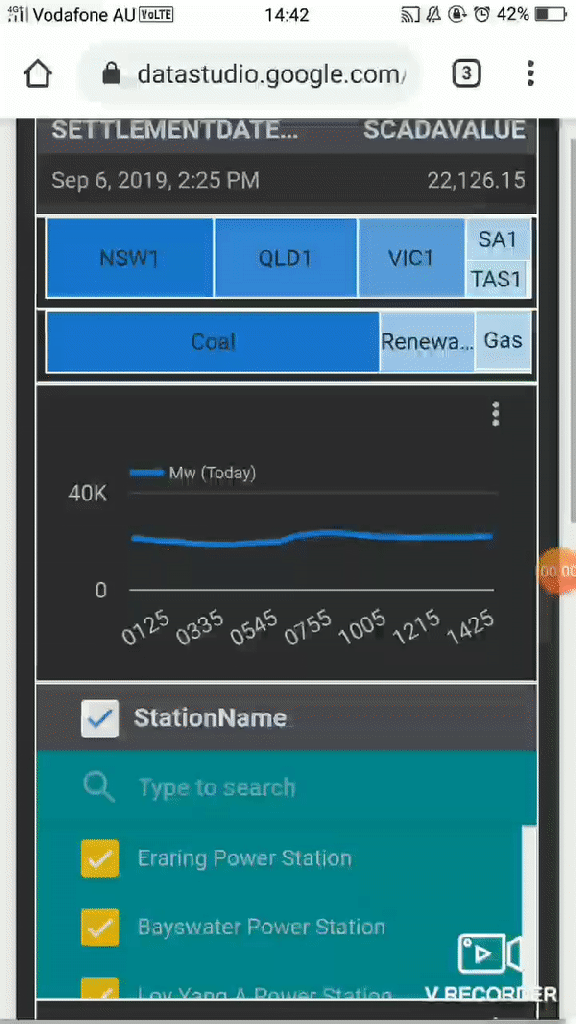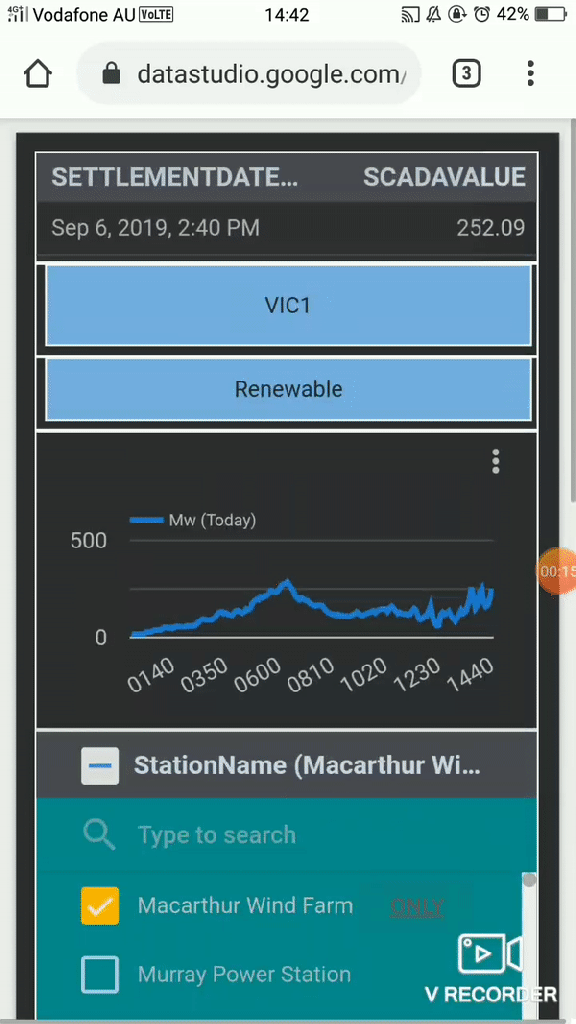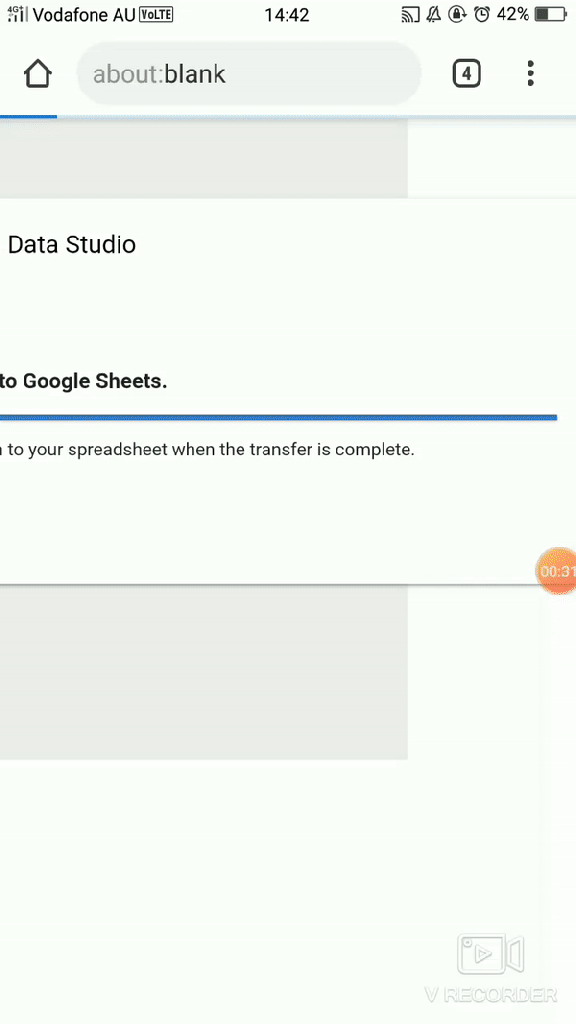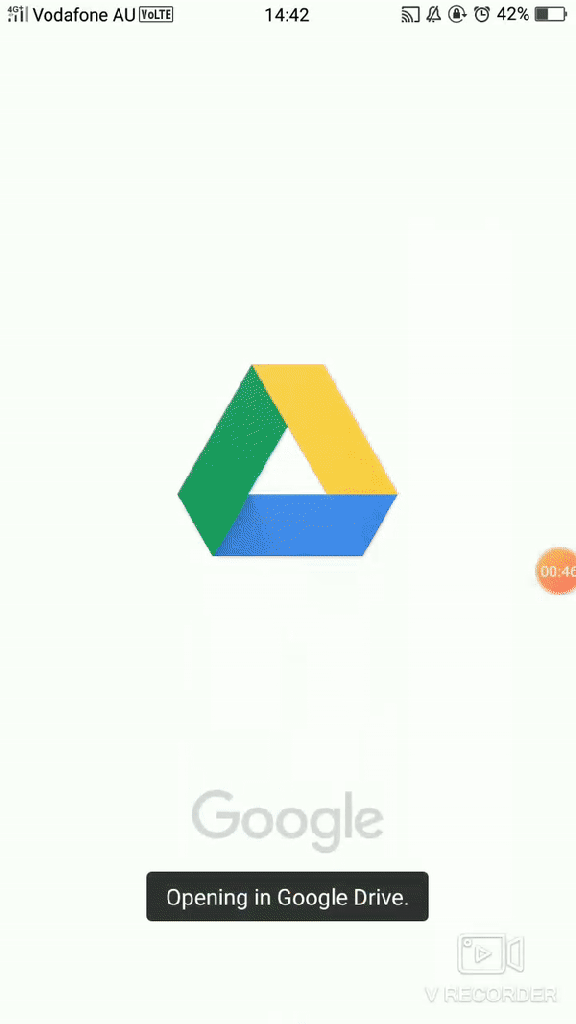
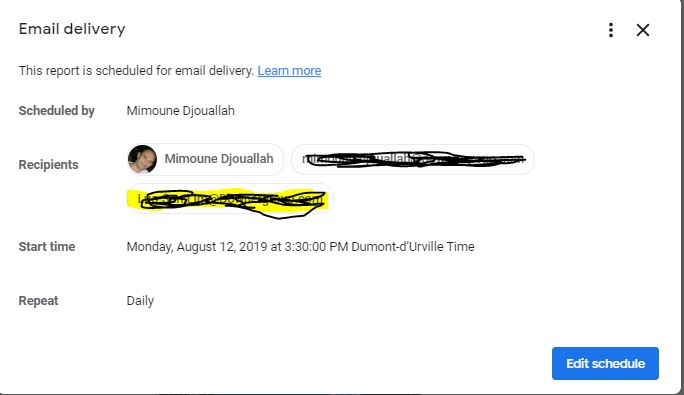
- Schedule email delivery
although the report is very simple, I must admit, I find it very satisfying, there is some little pleasure in watching real time data, some missing features, I would love to have
- An option to disactivate all the caches or bring back the option to let the viewer manually refresh the report.
- An option to trigger email delivery based on alert, (for example when a measure reaches a maximum value), or at least schedule email delivery multiple time per day.
- Make data Studio web site mobile friendly, it is hard to select the report from the list of available reports.
- Google Data Studio support for maps is nearly non existent, that’s a showstopper for a lot of business scenarios