TL;DR : Direct Query with Fabric SQL is considered a background operation, which means the usage is smoothed over a 24 hours period, this blog is definitely not a recommendation nor a good practise or anything in that nature, but I was just curious, what if this make Direct Query an attractive proposition in some scenarios ?
Use Case, Small Data with frequent refreshes
We assume it is a small company ( 10 users),we will test using a Fabric F2 SKU and PowerBI Pro license as a front end. ( free PowerBI readers start from F64)
Monthly cost = Fabric 156 $ + PowerBI Pro 10 x 10 = 256 US $/Month
In this case, the business requirement is to have the freshness of 5 minutes, the user needs to the see the latest data, which make import not an option as it is limited to 8 times per day
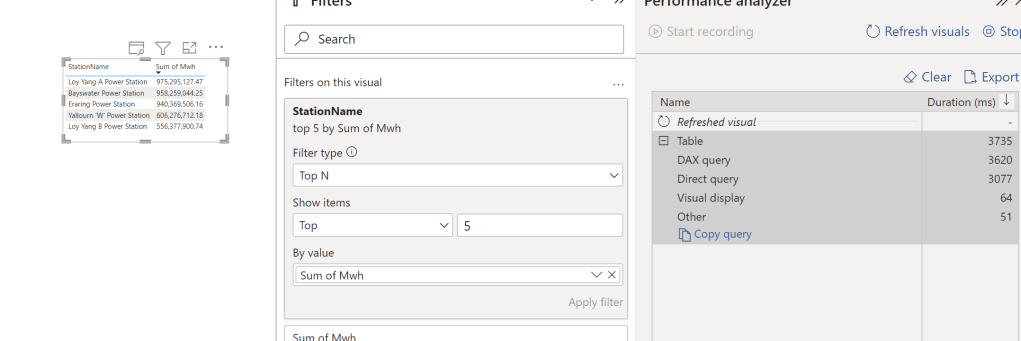
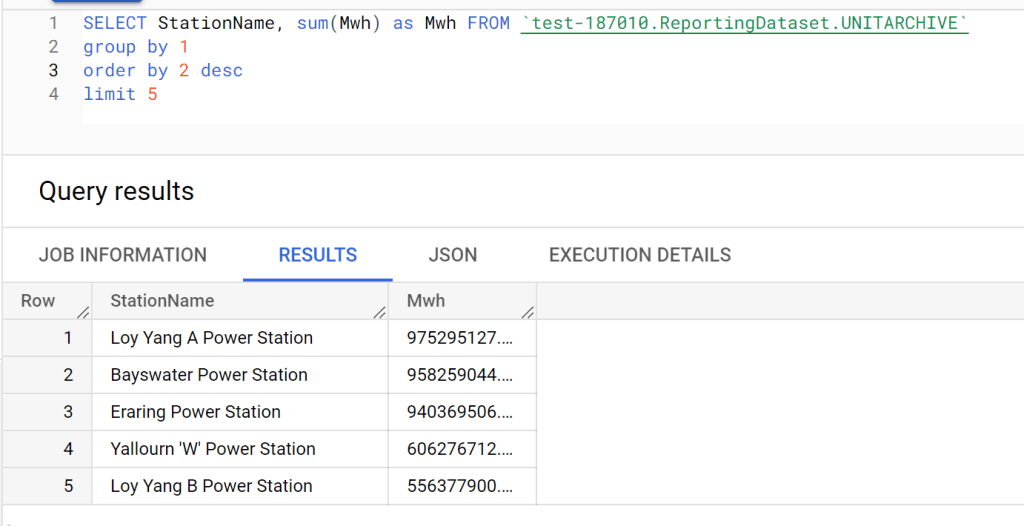
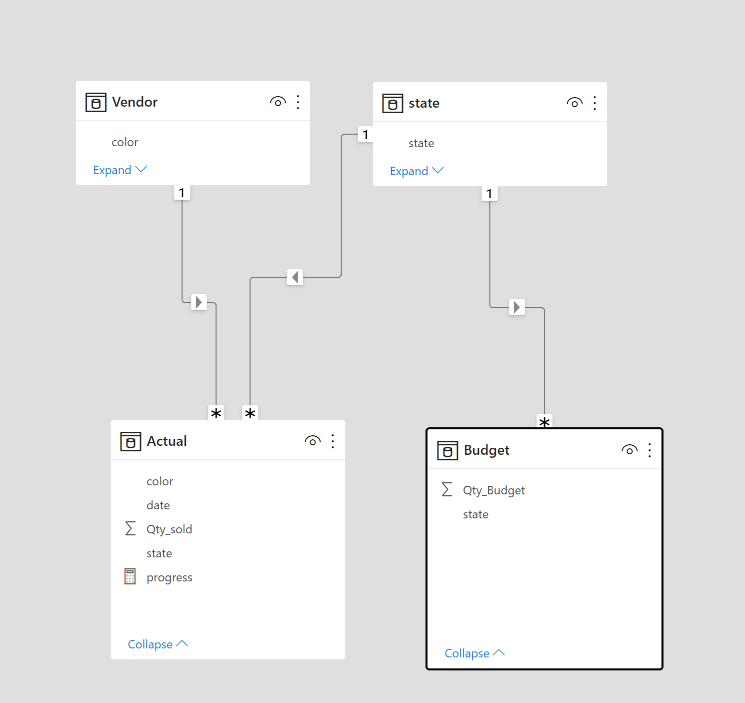
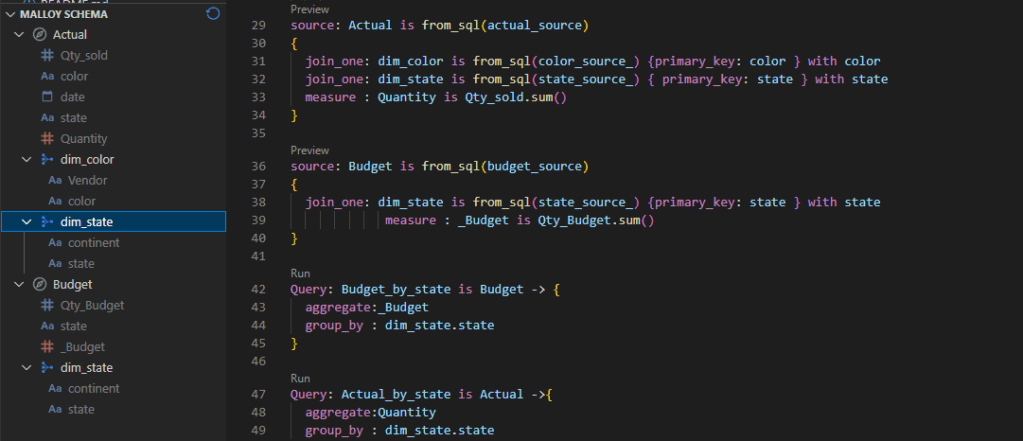
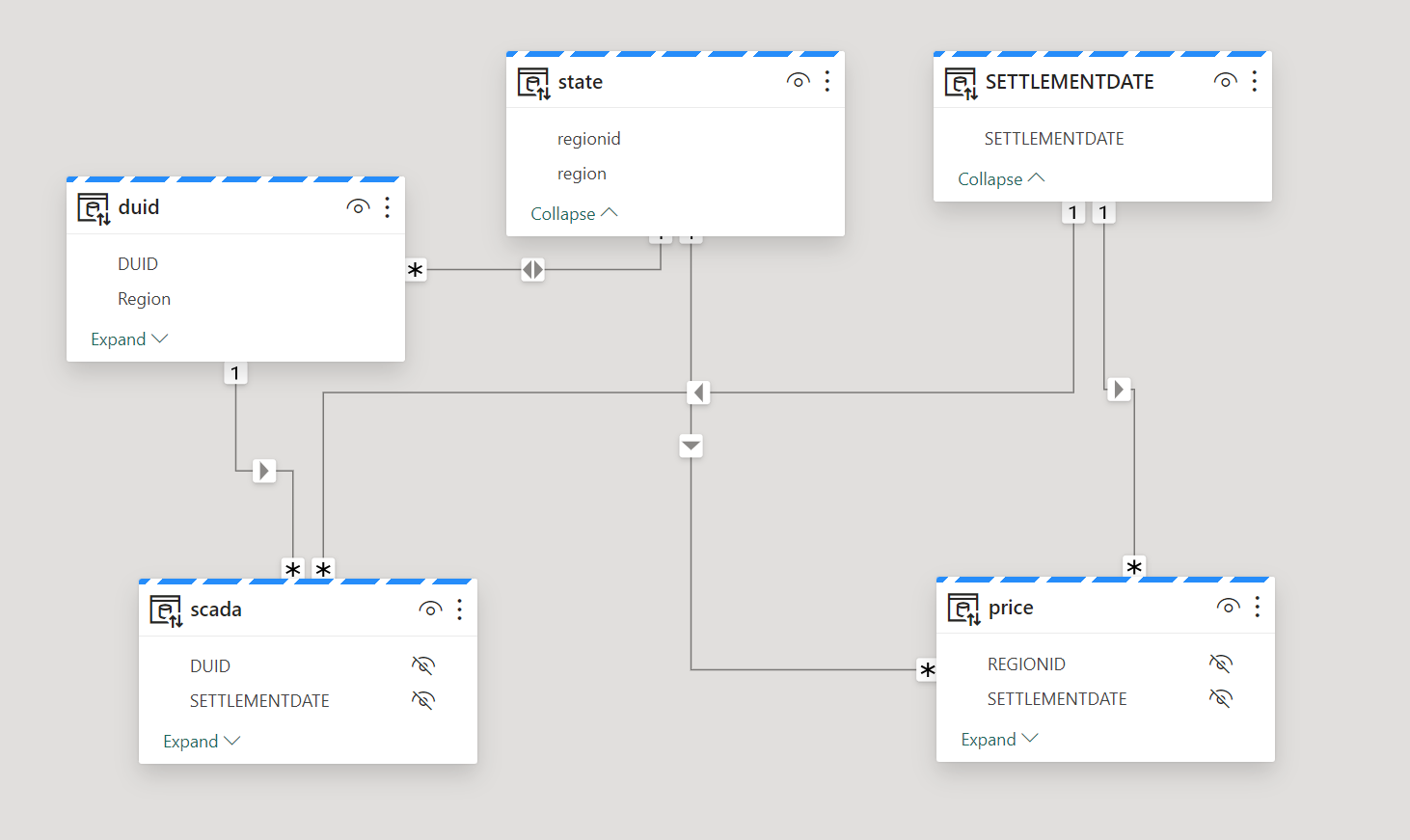
The Data Model
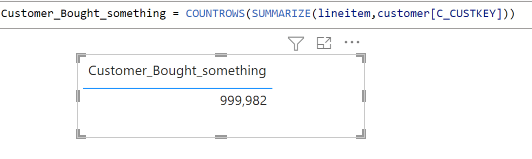
The data model is relatively small, 5 Tables, 3 dimensions and two fact tables, the biggest one is 9 Million rows, the facts are ingested with new data every 5 minutes, Table State and Settlement Date are fixed, and DUID changes very slowly, maybe once every couple of months.
Fabric Notebook as an ingestion tool
To reduce compute usage, we used Spark notebook with the smallest compute, 4 cores and 32 GB of RAM

How to simulate concurrency
This one is tricky, 10 users does not mean, they will all open the same report at the same time and continuously clicking refresh, I know there are tools to test load PowerBI but you needs to install Powershell and stuff, I just simulated by using a dynamic slicer and running multiple copies of the report concurrently.
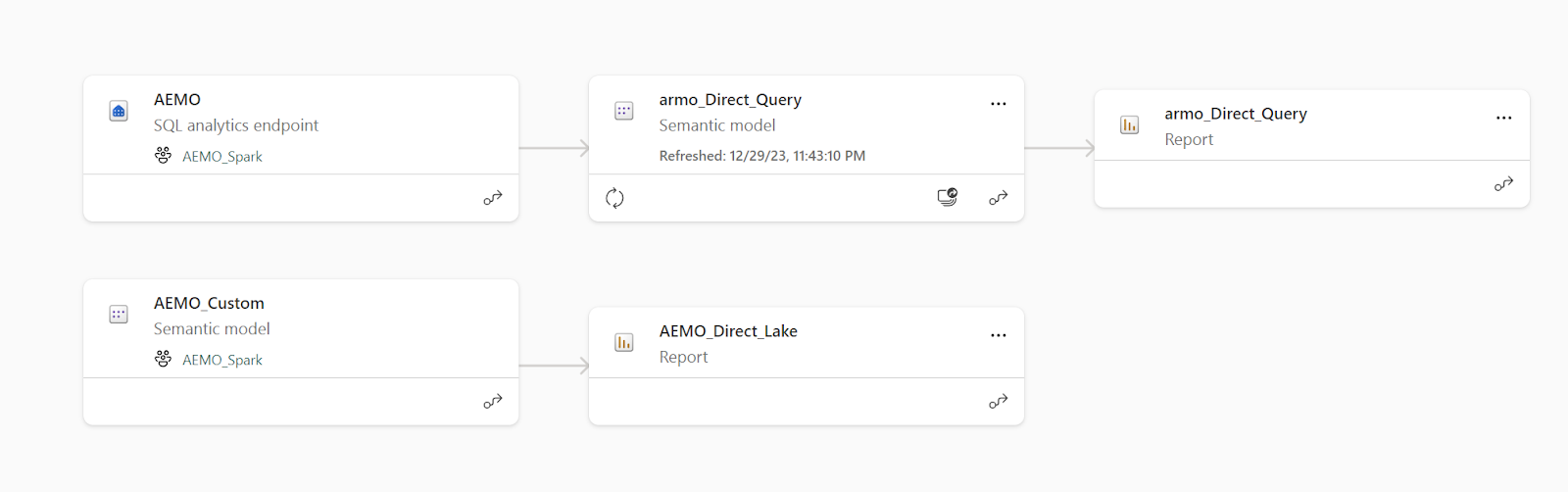
Two Workspaces
we will try to keep it as simple as possible, no medallion architecture here, just two workspaces
Backend Workspace : using an F2 capacity
Front End Workspace : old school pro license workspace

Direct Lake Mode vs Direct Query vs Import in Fabric
As an oversimplification and specially for People not familiar with microsoft BI stack, PowerBI Engine is called analysis Service and it does basically two thing
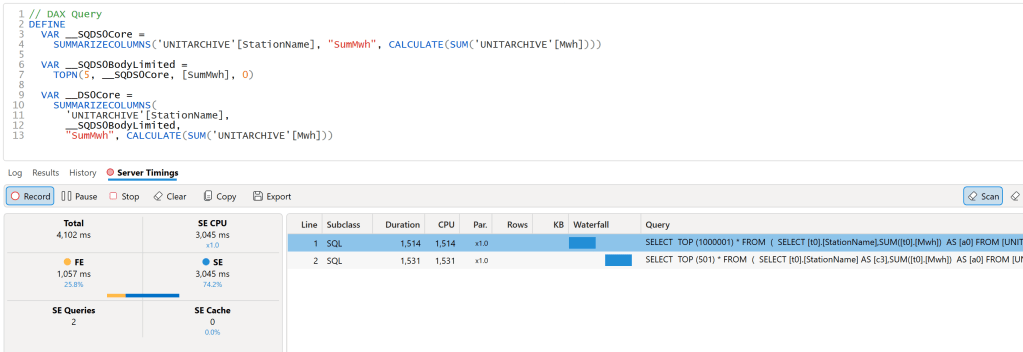
Formula Engine : Translate DAX using the semantic model to SQL
Storage Engine : get the data from storage using SQL
Direct Query mode : The data is served by a DB like Synapse or BigQuery, SQL Server etc
Direct Lake mode : The Data is served by Vertipaq, the data format is open source
Import mode : The Data is served by Vertipaq, the data format is proprietary
Note that Import and Direct Lake difference is in the storage format, but the In-Memory format is the same ( that’s a very clever design decision)
Vertipaq will always be the Fastest Engine
Vertipaq is designed for one thing, pure speed, so I don’t have any expectation that other Engines can compete with it, we are talking milliseconds even with joins and multiple tables, I am more interested in resource usage though

Resource Usage Profile
Direct Lake (interactive tasks are smoothed over a short period of time)
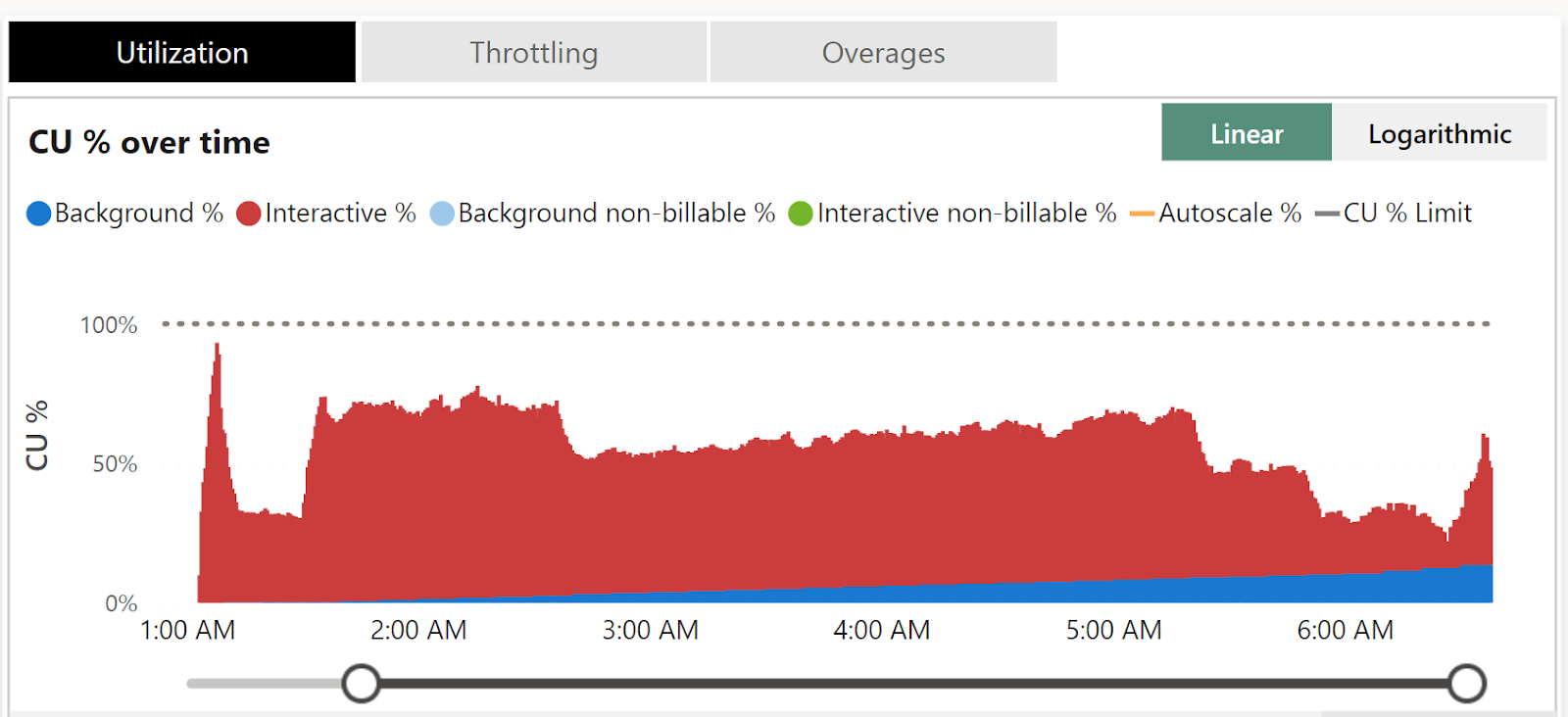
Direct Query with Fabric SQL (Background are smoothed over 24 hours)

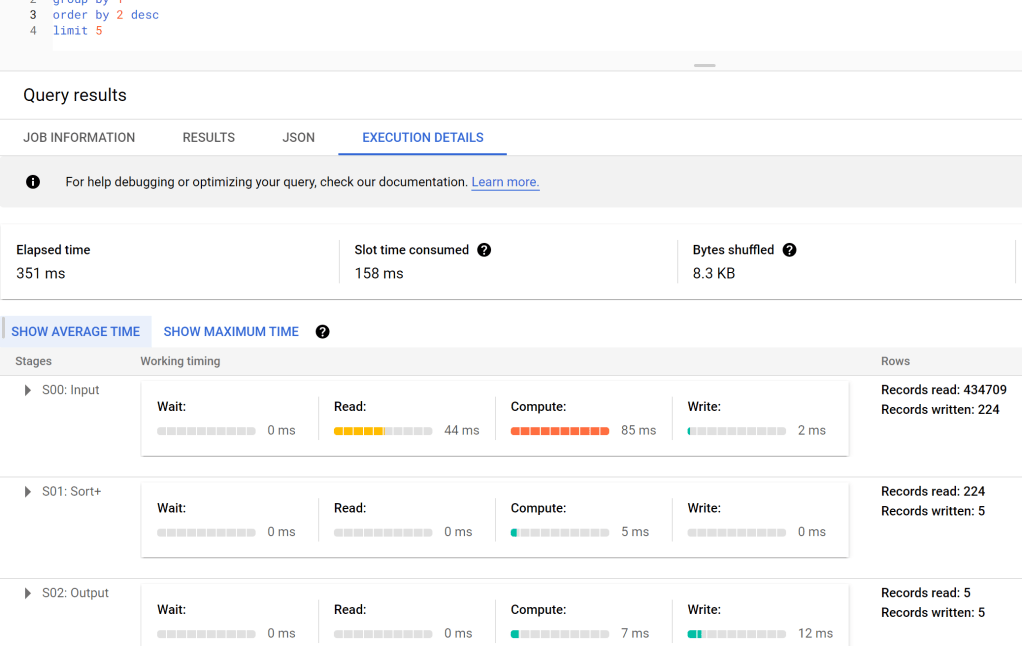
To be fair both modes worked as expected, Direct Lake is definitely faster which is expected but what got my attention is the DWH did well and drained the capacity with only a rate of 2 CU/s, there is no bursting, it is the baseline performance here, that’s extremely encouraging as one of the biggest complaint about cloud DWH is they don’t scale down very well.
Keep in mind in both cases, the total capacity you can consume in 24 hours is still limited by
24 X 2 CU = 172,800 CU(s).
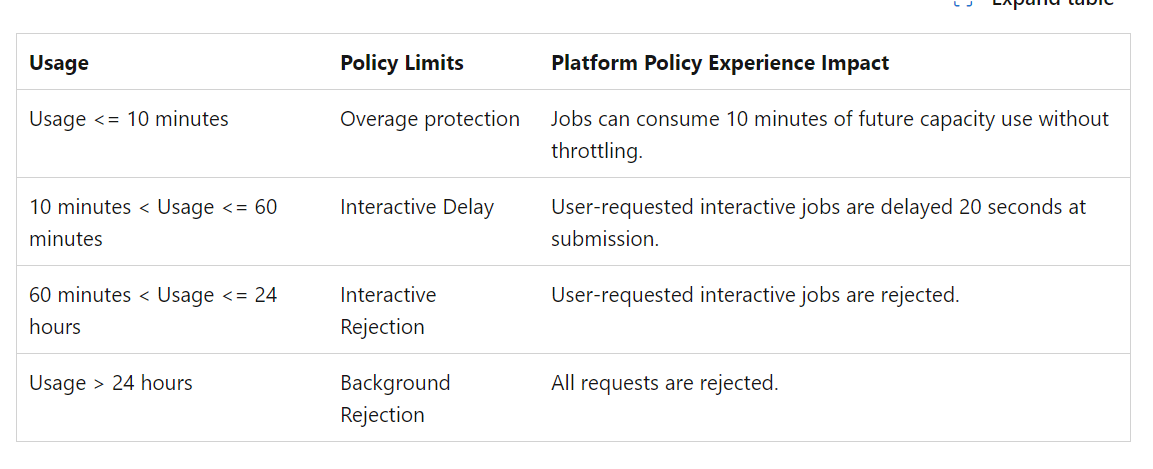
Having a look at this documentation as it is important to understand how to properly size your capacity
PowerBI is still very chatty
PowerBI does generate a lot of SQL Queries in Direct Query mode, most of it took between 500 ms to 1 second. that’s not bad for a SQL Engine that cost 0.36 $/Hour

Ok what does this all mean ?
I reserve the right to change my view after further testing, but my hypothesis is, given that the DWH has a very good performance but more importantly very efficient engine at lower scale and with the fact it is considered a background operation, Direct Query maybe an interesting option if you need more than 8 refresh per day and you are using PowerBI Pro license with a small scale F SKU.
But as always test using your own data.