TL;DR : OneLake is really an Open Storage system and works with any tool that understands Azure ADLS Gen2 API, but they changed the endpoint naming which was very confusing, (at least for me), but there is no catch, it is the same tech under the hood, there is no Vendor Lock-in, it is totally an open ecosystem.
Use Case :
For no obvious reason, I thought about an unusual scenario: Load data to OneLake using Dataflow Gen2 and Query the results using Snowflake, it works with any Engine that understands Delta Table, mind you, no Spark was involved at all, all using native code.
Azure AD
Fabric use Azure AD for authentication, and support service principal too , this is the recommended route, I am not sure if Snowflake understand OneLake Endpoint format, I think it expect something like this : “accountname.blob.core.windows.net/container_name/”
But OneLake you get something like this
“sharing@onelake.dfs.fabric.microsoft.com/sharing.Lakehouse/Tables/scada”
Maybe it works but I have not tested it, probably it is a blog for another day.
Shortcut
Another approach is to create a shortcut to an existing ADLS Gen2 storage account, it is trivial to setup and support read and write, which I did

I can write the data using either Spark or Dataflow Gen2, the Data Warehouse is not supported, you can read only using the OneLake Endpoint, anyway, for this example I am using Dataflow Gen2 to write the data

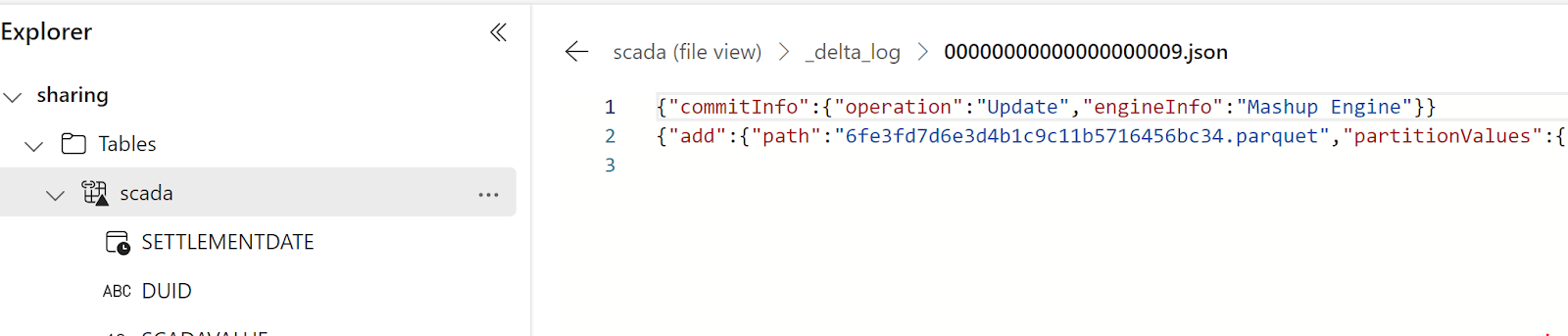
Turns out, PowerQuery has a native Delta table writer 🙂 , you can see it in the log
And here is the Data in Azure Storage

I feel like if you want to share data with external parties, maybe using an external Azure Container is a more flexible solution. I know it may sound silly but the fact I can see the data using the storage explorer in Azure independently of Fabric makes it seem more neutral.
Reading from Snowflake
Snowflake recommends using a service principal,but for this quick demo, I used a SAS token, making sure to grant read and list.

And then used this SQL Script the define the external table
create database ONELAKE ; create schema AEMO ; USE ONELAKE.AEMO ; CREATE OR REPLACE STAGE onelake URL='azure://fabricshare.blob.core.windows.net/scada/' CREDENTIALS=(AZURE_SAS_TOKEN='xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx') ; CREATE or replace EXTERNAL TABLE scada( SETTLEMENTDATE TIMESTAMP AS (value:SETTLEMENTDATE::VARCHAR::TIMESTAMP), DUID varchar AS (value:DUID::varchar), SCADAVALUE NUMBER(12,5) AS (value:SCADAVALUE::NUMBER(12,5)), file varchar AS (value:file::varchar)) LOCATION=@ONELAKE REFRESH_ON_CREATE = FALSE AUTO_REFRESH = FALSE FILE_FORMAT = (TYPE = PARQUET) TABLE_FORMAT = DELTA; ALTER EXTERNAL TABLE SCADA REFRESH; select settlementdate,sum(scadavalue) as mw from scada group by all;
to get the latest Data, you can run this SQL code
ALTER EXTERNAL TABLE SCADA REFRESH;
and because it is using Delta Table, you will not get dirty reads, only fully committed data is read.
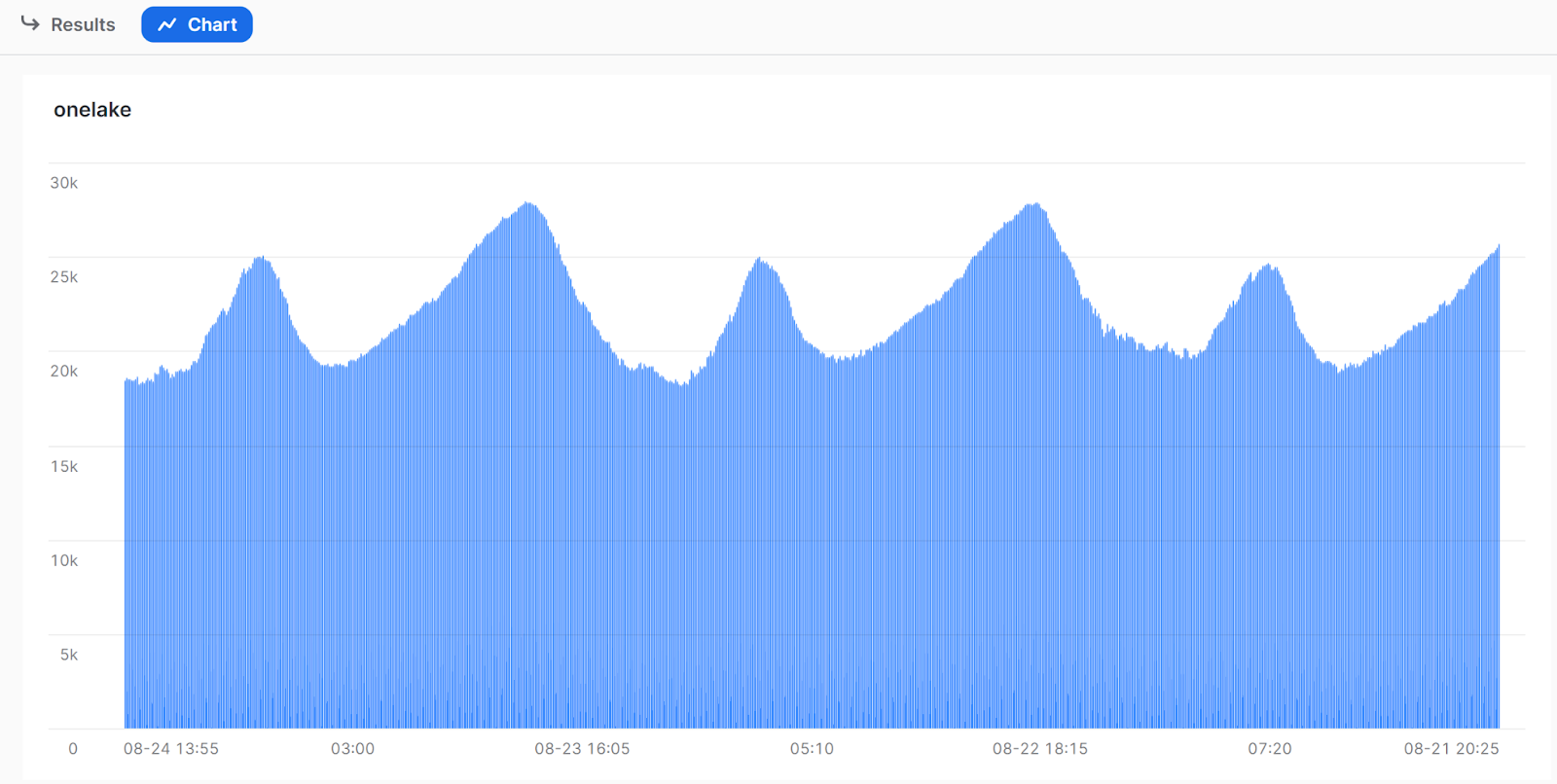
And here is a sample chart from Snowflake
Writing from Snowflake
Snowflake doesn’t support writing to Delta Table, which I think is a great use case for PowerBI users with Direct Lake mode. I guess for now, a user can use Fabric Data Factory to get the data, I feel there is a missed opportunity here.
Parting thoughts
I had a mixed feeling about Delta Table and the concept of Lakehouse in general, I felt it was too tight to Spark ecosystem, rather useful only for big data setup, I changed my mind,first by using Delta Rust and now Fabric is doing a good job making it even more accessible for business users, I think that’s progress, and to be very clear this setup works with Databricks, DuckDB and any Database that reads Delta Table.
