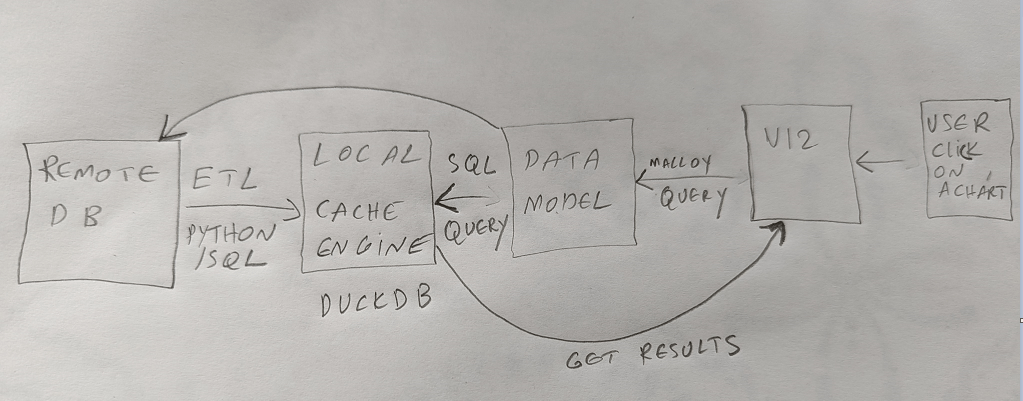
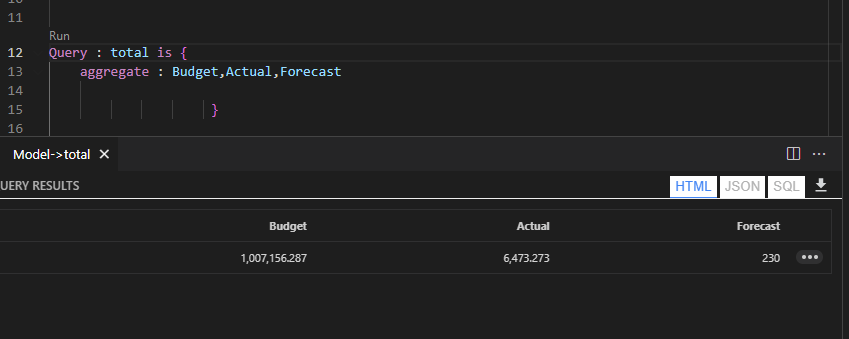
This is a quick blog showing how the two languages behave when dealing with multiple fact tables.
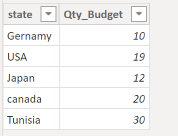
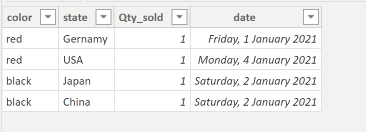
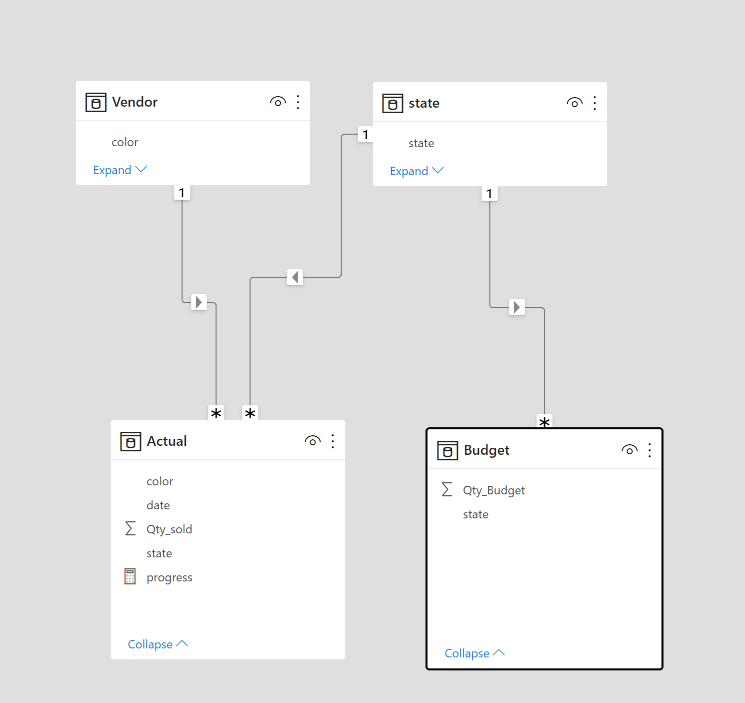
let’s start with a simple Model, Two Tables Budget and Actual storing items sold by country and color
Budget
Actual
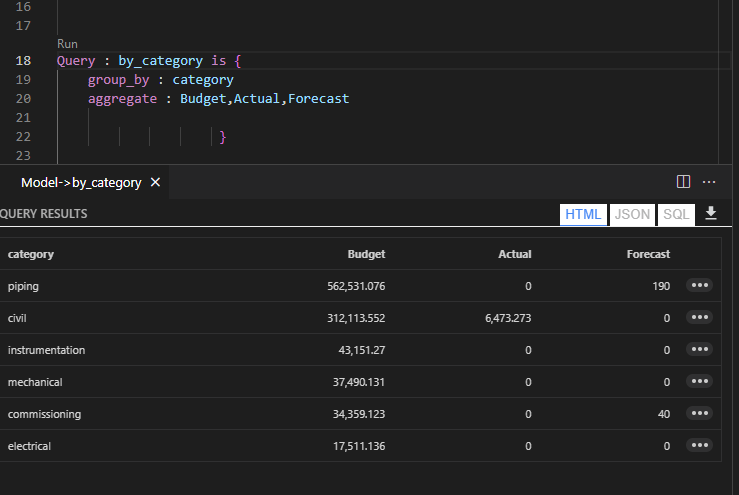
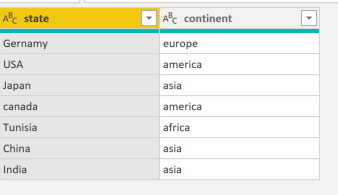
For example we want to ask, how many items were sold by continent, we don’t have this information, we need a dimension table that map state to continent.
DAX
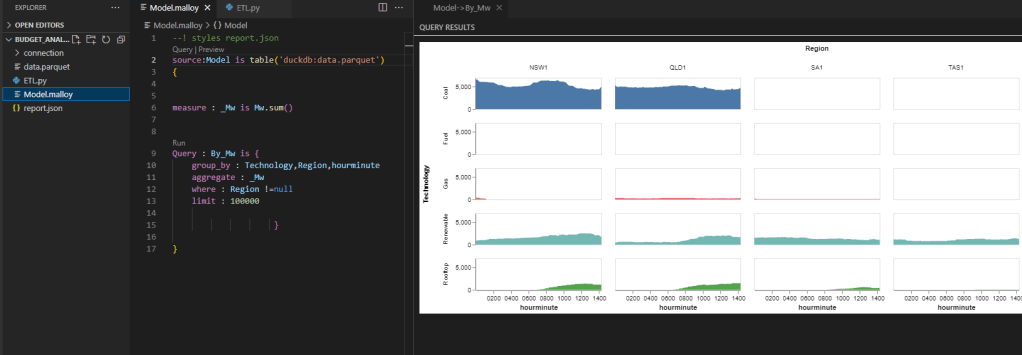
And the Data Model will look like this.
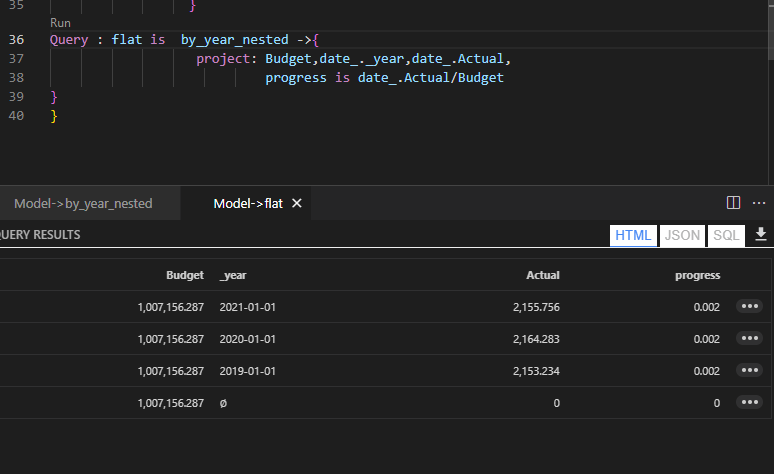
To get the results, we write this DAX Query in DAX Studio ( Btw, the new version 3 is very slick !!!)

DAX will generate two SQL Query to get the results from the two tables and merge the results, using the internal “Formula” Engine

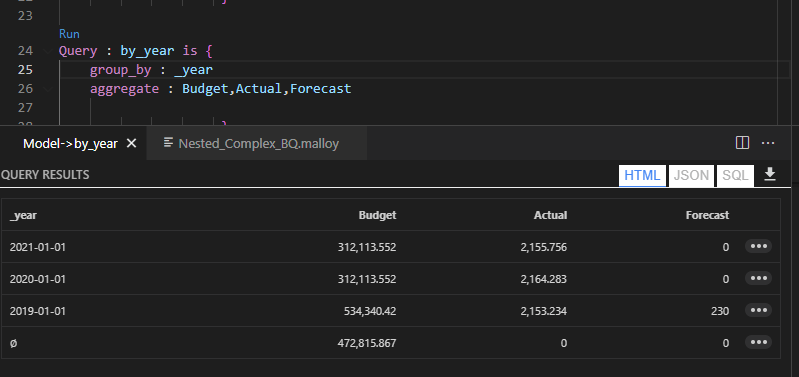
Malloy
in Malloy we do the same by writing code, you can download the Data Model here
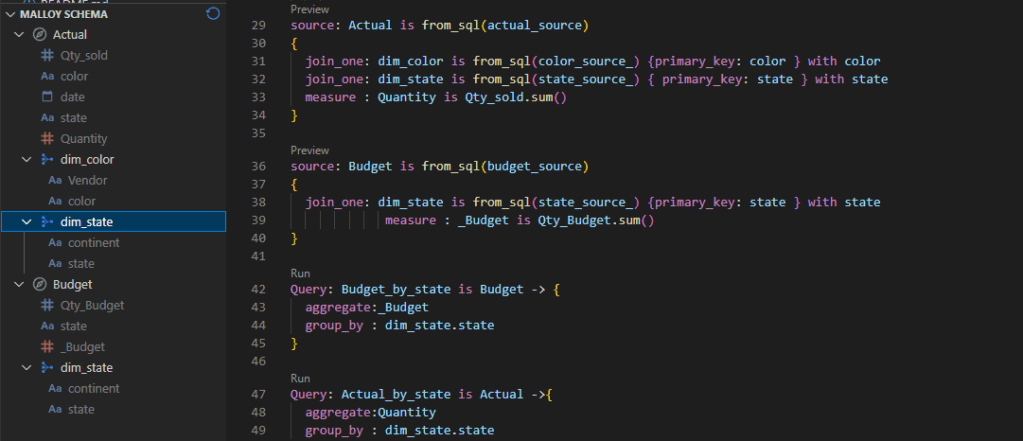
In DAX we use summarize columns to aggregate measures from different tables, as far as I can tell, Malloy don’t support this model yet, The tables Budget and Actual are independent, basically you need to manually join the two Queries generated from the two tables.
Query: Budget_by_state is Budget -> {
aggregate:_Budget
group_by : dim_state.state
}
Query: Actual_by_state is Actual ->{
aggregate:Quantity
group_by : dim_state.state
}
query: merge_results is from_sql(state_source_) {
join_one: q2 is from(->Budget_by_state ) with state
join_one: q3 is from(->Actual_by_state) with state
} ->{
group_by : continent
aggregate: QTY_Budget is sum(q2._Budget),QTY_Sold is sum(q3.Quantity)
}
And we get the same results, Malloy always generate one SQL Query, as there is no way to merge the results internally, as a matter of fact the only “calculation” engine is the SQL Database, which is in this particular case DuckDB.

Obviously you can always create new source by using state as a base table, but I don’t think it is a sustainable solution, as the whole point is to have One model that answers a lot of different Questions.
Take Away
Native support to multiple tables is obviously not unique to DAX, thoughtspot TML support it out of the Box, I hope Malloy developers consider this common scenario for future development.