1. delta-rs is an ACID Delta writer
delta-rs implements the Delta Lake protocol natively. merge, update, and delete go through optimistic concurrency control on every commit. No external coordinator, no catalog service. Two writers race for the same version of the log, one wins, the other retries.
All you need is a path. No metastore to provision, no catalog endpoint, no JDBC connection, no warehouse to wake up. A folder on disk (or on ADLS / S3 / GCS) is the whole interface.
Setup: B is a Delta table being fed a series of CSV batches (batch_001.csv, batch_002.csv, …). Each merge should ingest only files B hasn’t seen yet.
A naming note: the project is delta-rs but the Python package is deltalake (pip install deltalake). On Fabric, stick with what’s preinstalled — Python notebooks already ship with deltalake and OneLake access configured.
From the notebook:
# Bootstrap target B with batch_001 already ingestedwrite_deltalake(Target_PATH, pa.table({...}), mode="overwrite")vB = DeltaTable(Target_PATH).version() # v0# Compute the rows to ingest from the target's current statecon.sql(f"ATTACH '{Target_PATH}' AS tgt (TYPE delta, VERSION {vB});")our_rows = con.sql(""" SELECT s.id, s.value, parse_filename(s.filename) AS filename FROM read_csv_auto('source_csv/*.csv', filename=true) s WHERE parse_filename(s.filename) NOT IN (SELECT DISTINCT filename FROM tgt)""").arrow()# → 80 new rows from batch_002..005# First merge: 80 inserts, commits cleanlyDeltaTable(Target_PATH).merge( source=our_rows, predicate="t.filename = s.filename", source_alias="s", target_alias="t",).when_not_matched_insert_all().execute()# Same merge re-run: 0 inserts. The predicate is idempotent.DeltaTable(Target_PATH).merge(...).when_not_matched_insert_all().execute()
Two commits, both correct. The second run does nothing because the predicate already sees the rows. The transaction model travels with the table itself: move the folder, open it from another machine, and the next writer continues from the last commit.
write_deltalake(mode="append") and write_deltalake(mode="overwrite") are blind on purpose. Blind append means N concurrent appenders all succeed and the result is the union of their rows — exactly what you want for event streams or log ingestion. Blind overwrite means the new data wins and whatever was there is gone — what you want when the writer is the authoritative source for the table. OCC only kicks in for operations that actually read the target (merge, update, delete), since those are the only ones where a concurrent change can invalidate what you just computed.
2. I want the full read-to-write transaction, Python API is fine
A common pattern: DuckDB or Polars reads, transforms, and hands an Arrow table to delta-rs to commit. The notebook above is exactly that shape — DuckDB computes “filenames not yet in B” and delta-rs merges the result.
Inside delta-rs, OCC still works. What it cannot see is the read on the other side of the engine boundary. delta-rs knows about the merge it is about to commit; it does not know that DuckDB read B at version vB thirty seconds ago.
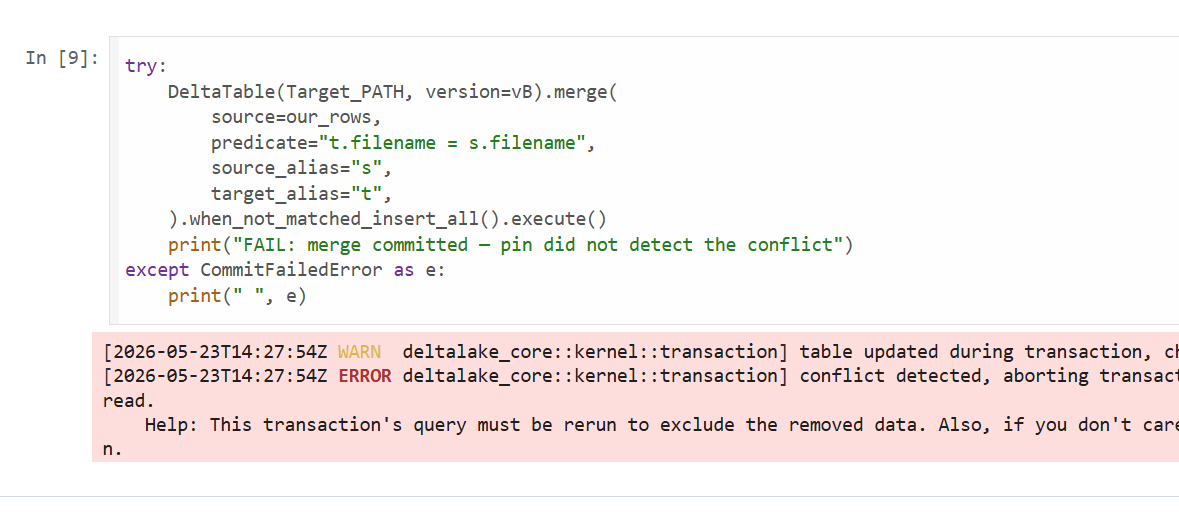
Carry the snapshot across the boundary by pinning both sides to the same version:
vB = DeltaTable(Target_PATH).version()import duckdbcon = duckdb.connect()con.sql(f"ATTACH '{Target_PATH}' AS tgt (TYPE delta, VERSION {vB});")our_rows = con.sql("SELECT ...").arrow()DeltaTable(Target_PATH, version=vB).merge( # ← pinned source=our_rows, predicate="t.filename = s.filename", source_alias="s", target_alias="t",).when_not_matched_insert_all().execute()
The OCC check now compares against vB instead of HEAD. If another process touched B in the meantime — say a parallel job deleted batch_001.csv — the pinned merge raises:
Failed to commit transaction: Commit failed: a concurrent transaction deleted data this operation read.
Catch it, recompute the diff against fresh state, retry. On the Polars side, pl.read_delta(path, version=vB) accepts the same pin, so the pattern works for any reader that exposes versioned reads.
The pin is just a number. No new infrastructure, no shared coordinator, still path-based.
3. I don’t want the Python API, I want SQL only
If you would rather write SQL — say, drive the pipeline from dbt — your options on Delta today are Spark and Fabric Data Warehouse. Both have supported dbt adapters and work great in production. I have to admit, I was hoping DuckDB would fill that gap, since it is a database and SQL-level transactions are what you expect from a database. The market went the other way: investment is going into catalog-based lakehouse formats (DuckLake, Iceberg), and the DuckDB Delta writer that does exist is tied to Unity Catalog and limited to blind appends. I don’t see them investing in a file-based conflict resolver any time soon 🙂 Lakesail seems interested in this use case, but it is still too early to call.
Takeaway
I personally use delta-rs for CSV ingestion, appends, and recording results from high-concurrency performance tests — it is fast, cheap, and bullet-proof in those scenarios. The open source maintainers are very helpful and care deeply about the product, as they use it themselves in production. But it is not the right tool for every case; Data Warehouse and Spark are more appropriate for complex workloads. With time you intuitively pick the tool that makes sense for a particular job and how much compute you can spend. None of that has to be an either/or: at the end of the day it is a lakehouse, and the whole concept of a lakehouse is having the option to choose the engine. That option matters — if we say only one engine (open source or not) is blessed for writes, then there is no point in the concept of a lakehouse.
Notebook: https://github.com/djouallah/Fabric_Notebooks_Demo/blob/main/TableFormat/delta/occ.ipynb
Thanks Raki for keeping me honest:)
Thanks to Ion for explaining how version worked when doing merge: https://www.linkedin.com/in/ionkoutsouris/
Edit : how about Spark
Thanks to Frithjof for explaining Spark behaviour : The merge fixes one snapshot at transaction start (current HEAD = post-delete) and uses it for both its scan and its conflict check. Internally consistent — but bound to HEAD-at-merge-start, which Spark chose, not to the state our read saw, same behaviour when using delta_rs with a lazy dataframe : https://github.com/djouallah/Fabric_Notebooks_Demo/blob/main/TableFormat/delta/occ_spark.ipynb