
I had a simple data ingestion use case, Notebook A inserts data to a Delta Table every 5 minutes and Notebook B backfills the same table with new fields but only at 4 am.
Initially I just scheduled Notebook A to run every 5 minutes and Notebook B to run at 4 AM , did not work as I got a write conflict, basically Notebook B take longer time to process the data, when it is ready to update the table, it is a bit too late as it was already modified by Notebook A and you get this error

Workarounds
Solution 1 : Schedule Notebook A to run every 5 minutes except from 4 AM to 4:15 AM, today it is not supported in Fabric scheduler ( although it works fine in Azure Data Factory).
Solution 2 : Partition by Date to avoid Spark writing to the same file at the same time, which is fine for my table as it is big enough around 230 Millions spread over 6 years, generating 2000 files is not the end of the world, but the same approach does not work for another table which is substantially smaller around 3 millions
Solution : Turn out, there is a code base orchestration tool in Fabric Notebook
I knew about MSSparkUtils mainly because Sandeep Pawar can’t stop talking about it 🙂 but I did not know that it does orchestration too, in my case the solution was trivial.
Add a check in notebook A if there is a new file to backfill ; if yes call Notebook B
if len(files_to_upload_full_Path) > 0 :
mssparkutils.notebook.run("Transform_Backfill_Previous_Day")And it did work beautifully ( I know the feeling, it is easy when you know it)
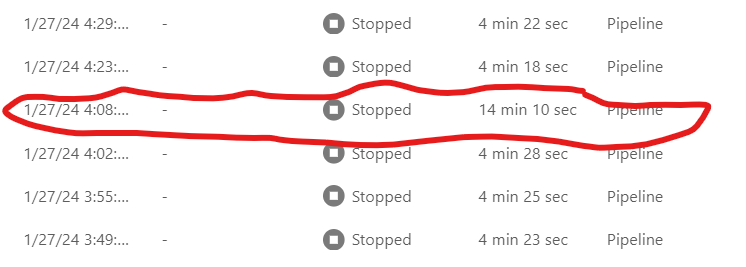
Notice that the second Notebook runs using the same Runtime, so it is faster and maybe even cheaper.
Ok there is More
Conditionally running a notebook based on a new file arrival is a simple use case, but you can do more, for example you can run multiple notebooks in parallel or even define complex relationships between Notebooks using a DAG with just Python code !!!!

Take Away
This is just a personal observation , because Fabric was released with all the Engines at the Same time, a lot of very powerful features and patterns did not get a chance to be fully exposed and appreciated, and based on some anecdotal evidence on twitter , it seems I am not the only one who never heard about Fabric Notebook code orchestration.
For PowerBI people Starting with Fabric, Python is just too Powerful. Yes, we did fine without it all these years, but if you have any complex data transformation scenarios, Python is just too important to ignore.
Thanks Jene Zhang for answering my silly questions.

One thought on “Use Fabric Notebook code based orchestration tool to avoid concurrent write conflicts.”