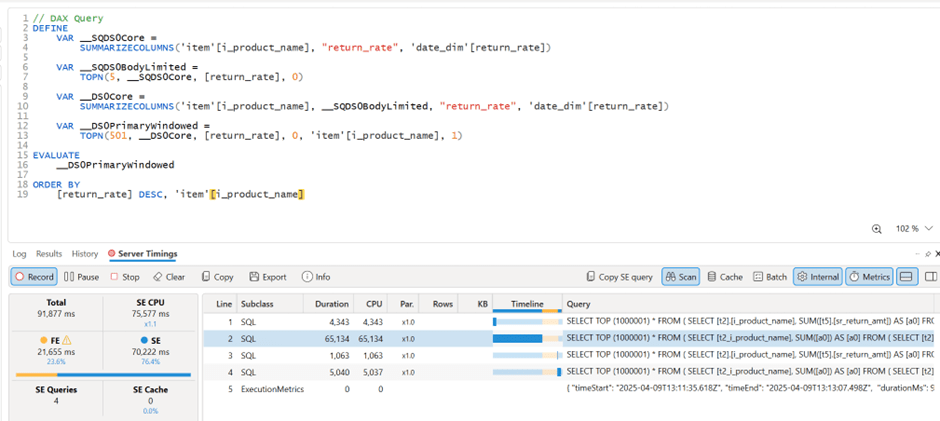
TL;DR ; This post shares a quick experiment I ran to test how effective (or ineffective) small language models are at generating SQL from natural language questions when provided with a well-defined semantic model. It is purely an intellectual curiosity; I don’t think we are there yet. Cloud Hosted LLMs are simply too good, efficient, and cost-effective.
You can download the notebook and the semantic model here.
⚠️ This is not a scientific benchmark.
I’m not claiming expertise here—just exploring what small-scale models can do to gain an intuition for how they work. Large language models use so much computational power that it’s unclear whether their performance reflects true intelligence or simply brute force. Small-scale models, however, don’t face this issue, making their capabilities easier to interpret.
Introduction
I used Ollama to serve models locally on my laptop and DuckDB for running the SQL queries. DuckDB is just for convenience—you could use any SQL-compatible database
For a start I used Qwen3, 4B, 8B and 14B, it is open weight and I heard good reviews considering it’s size, but the same approach will works with any models, notice I turn off thinking mode in Qwen.
To be honest, I tested other small models too, and they didn’t work as well. For example, they couldn’t detect my graphics card. I probably missed some configuration, but since I don’t know enough, I prefer to leave it at that.
0. Semantic Model Prompt
A semantic_model.txt file acts as the system prompt. This guides the model to produce more accurate and structured SQL outputs , the semantic model itself was generated by another LLM, it does include non trivial verified SQL queries ,sample values, relationships , measures etc, custom instructions
“no_think” is to turn off the thinking mode in Qwen3

1. Setup and Environment
- The notebook expects an Ollama instance running locally, with the desired models (like
qwen3:8b,qwen3:4b) already pulled usingollama run <model_name>.
2. How It Works
Two main functions handle the process:
get_ollama_response:
This function takes your natural language question, combines it with the semantic prompt, sends it to the Local Ollama server, and returns the generated SQL.execute_sql_with_retry:
It tries to run the SQL in DuckDB. If the query fails (due to syntax or binding errors), it asks the model to fix it and retries—until it either works or hits a retry limit.
In short, you type a question, the model responds with SQL, and if it fails, the notebook tries to self-correct and rerun.
3. Data Preparation
The data was generated using a Python script with a scale factor (e.g., 0.1). If the corresponding DuckDB file didn’t exist, the script created one and populated it with the needed tables. Again, the idea was to keep things lightweight and portable.
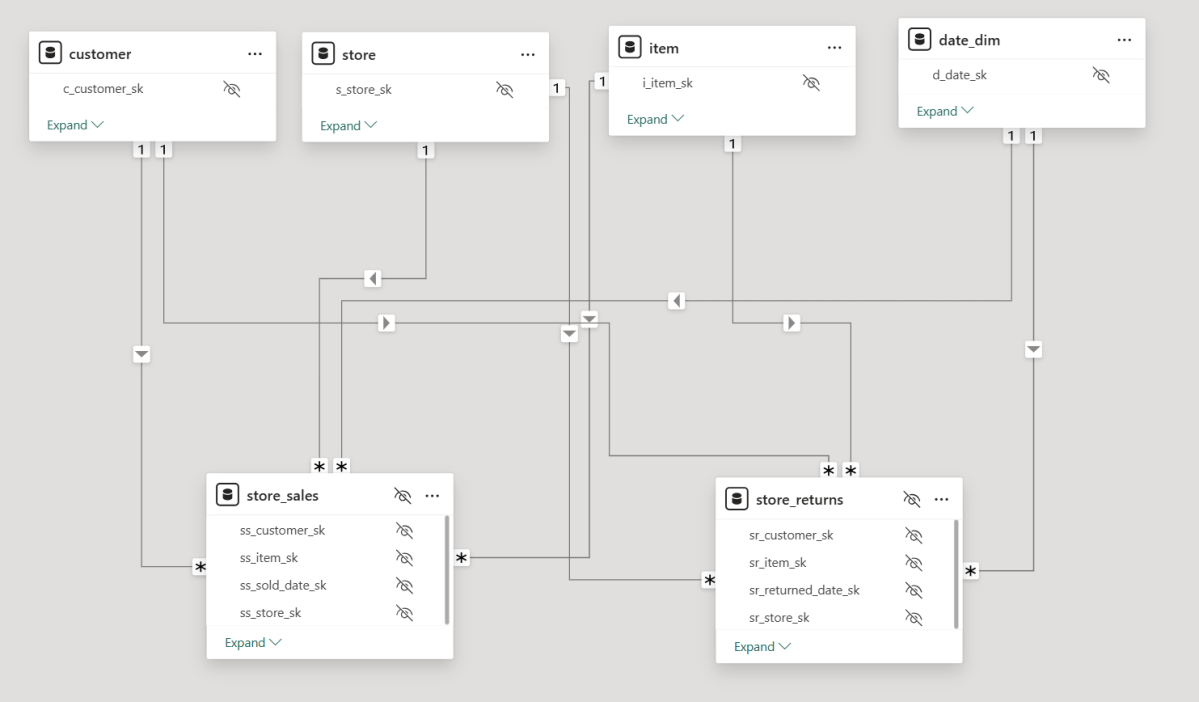
Figure: Example semantic model
4. Testing Questions
Here are some of the questions I tested, some are simple questions others a bit harder and require more efforts from the LLM
- “total sales”
- “return rate”
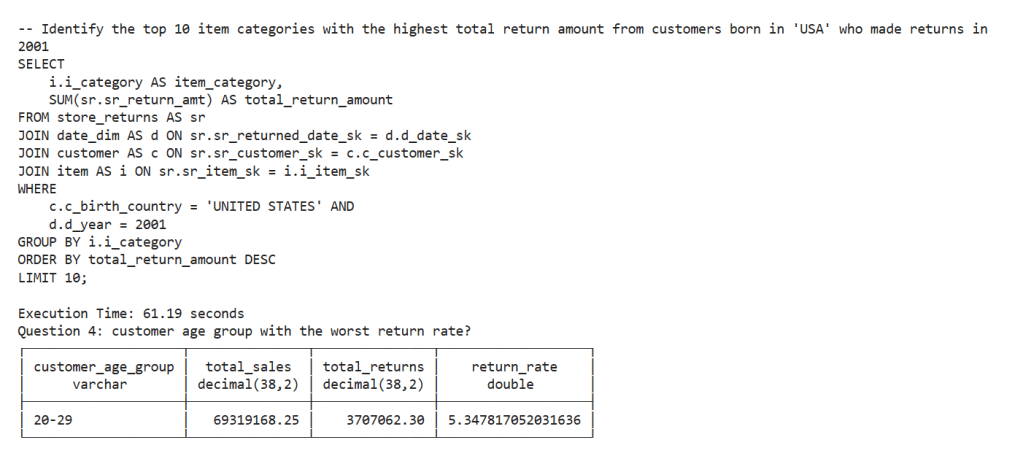
- “Identify the top 10 item categories with the highest total return amount from customers born in ‘USA’ who made returns in 2001.”
- “customer age group with the worst return rate?”
- “return rate per year”
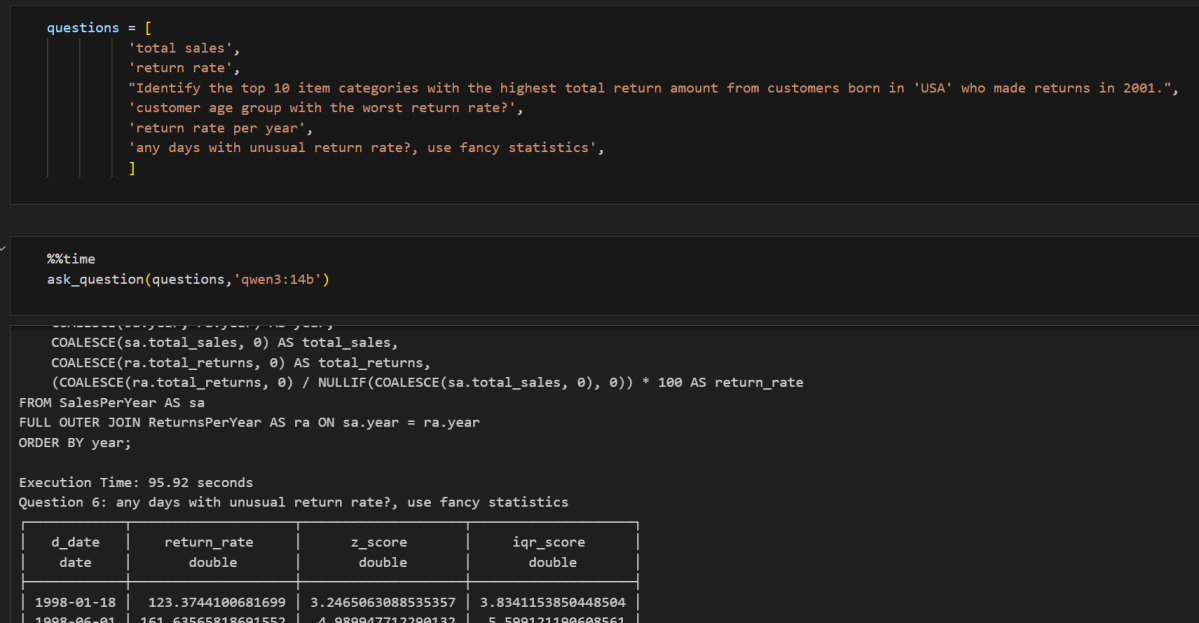
- “any days with unusual return rate?, use fancy statistics”
Each question was sent to different models (qwen3:14b, qwen3:8b, qwen3:4b) to compare their performance. I also used %%time to measure how long each model took to respond, some questions were already in the semantic model, verified query answers, so in a sense it is a test too to see how the model stick with the instruction
5. What Came Out
For every model and question, I recorded:
- The original question
- Any error messages and retries
- The final result (or failure)
- The final SQL used
- Time taken per question and total time per model
6. Observations
Question 6 : about detecting unusual return rates with “fancy statistics “stood out:
- 8B model:
Generated clean SQL using CTEs and followed a star-schema-friendly join strategy. No retries needed. - 14B model:
Tried using Z-scores, but incorrectly joined two fact tables directly. This goes against explicit instruction in the semantic model. - 4B model:
Couldn’t handle the query at all. It hit the retry limit without producing usable SQL.
By the way, the scariest part isn’t when the SQL query fails to run, it’s when it runs, appears correct, but silently returns incorrect results
Another behavior which I like very much, I asked a question about customers born in the ‘USA’, the model was clever enough to leverage the sample values and use ‘UNITED STATES’ instead in the filter.
Execution Times
- 14B: 11 minutes 35 seconds
- 8B: 7 minutes 31 seconds
- 4B: 4 minutes 34 seconds
Tested on a laptop with 8 cores, 32 GB RAM, and 4 GB VRAM (Nvidia RTX A2000), the data is very small all the time is spent on getting the SQL , so although the accuracy is not too bad, we are far away from interactive use case using just laptop hardware.
7- Testing with simpler questions Only
I redone the test with 4B but using only simpler questions :
questions = [
'total sales',
'return rate',
"Identify the top 10 item categories with the highest total return amount from customers born in 'USA' who made returns in 2001.",
'return rate per year',
'most sold items',
]
ask_question(questions,'qwen3:4b')the 5 questions took less than a minutes, that promising !!!
Closing Thought
instead of a general purpose SLM, maybe a coding and sql fine tuned model with 4B size will be an interesting proposition, we live in an interesting time