Edit : 23 Dec 2021, Shant Hovsepian from Databricks was kind enough and gave me some suggestion, Blog Updated.
Edit : 25 Dec 2021, added a note regarding Delta Lake open storage format.
This is another short blog on a series of my first impression of using different Data warehouse Engine and how they behave when used for a BI Workload, I am particular interested in small dataset and Mainly looking at concurrency and latency.
How to conduct a simple Test
The approach is the same, Build a simple PowerBI report using Direct Query , you can use Tableau with Live connection too or you favorite BI tool.
I run one instance of the report, I like to use play slicer to simulate user interaction, then a second instance etc, and see how the Engine behave
Setup Databricks SQL
Databricks has made an amazing job, The Workspace is very neat and intuitive, there is no Mention of the word Spark at all, they hided all the complexity, as far as I am concerned, it act like any Cloud Data warehouse, I had some hiccups though, Azure did complain about some Cpu Quota, it was easy to fix, but very annoying, Google Cloud setup was easier, but as of this writing, there is no SQL interface yet and you have to pay a 100-200 $ cost for Kubernetes, I end up Using Azure

when you explore a new SQL Database, the first thing you check is the sample Data, Strangely, it will ask for a Compute to be running to even have a look at the metadata.

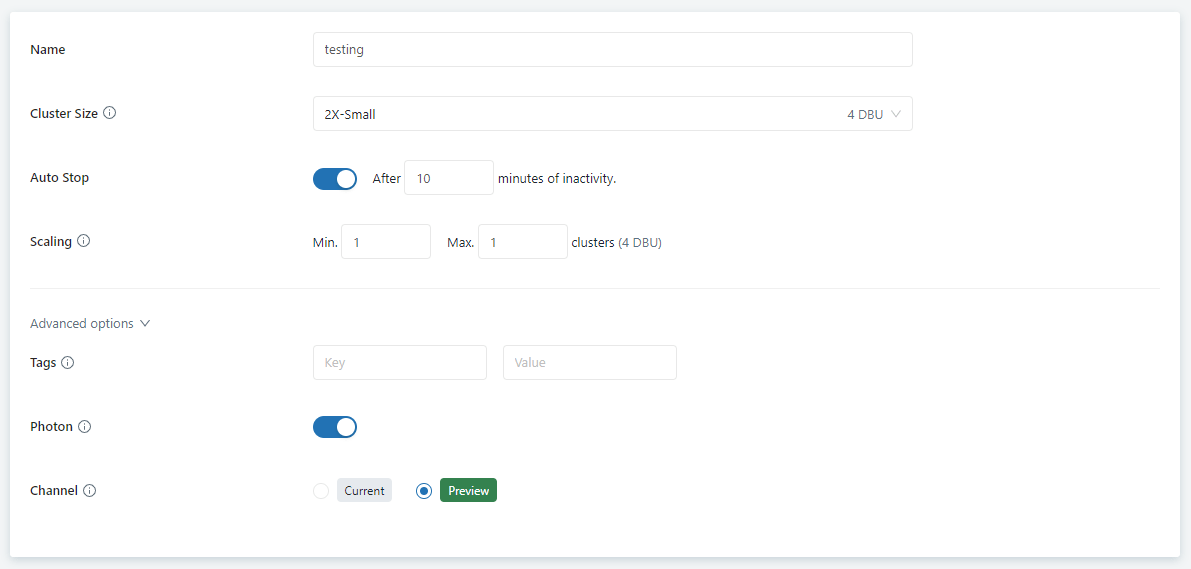
Creating a new Compute is very simple, I really like that you can select which version of the engine you want to run, Current or Preview, Auto Stop works as expected, but
it is really slow to start a Cluster ( around 4 minute)
The Minimum duration for Auto Stop is 10 minutes ( in practise, you should increase it to 1 Hour, a user waiting 5 minutes for his report to Start is not fun)
Databricks at least in Azure is a platform as a service, when you create a new cluster it will use your own resources to Provision a new VM (CPU, Disk etc), no surprise it take so long to start a new Cluster.
I notice when you resize a Cluster, the Engine became offline, it make sense maybe to use Auto Scaling instead.
For the Pricing, you pay in Databricks Unit (DBU) 1 DBU = 0.22 $/Hour and the resources generated, I can’t find the reference, but it seems an 2X-Small require 2 CPU with a cost of 0.64 $/Hour.
so the Total for my test Cluster is 0.22 * 4 + 0.64 * 2 = 2.16 $/Hour

Testing PowerBI
Connecting to PowerBI and Tableau was literally a 2 clicks away, In PowerBI you click on a link and it will generate a PowerBI report file, fantastic

I used some sample Data provided by Databricks, the main fact Table is 1 GB and has 30 Million records

here is my PowerBI Data Model

And here is the PowerBI report, Basically Looping on Customer Key and generate some simple aggregate, the report generate 3 SQL Queries every 5 Second

When I run Only 1 Instance of the report, it works rather well, added second Instance, still behaved well, but when I added a third Instance, it became unusable, and Queries start to get added to a Queue, the Cluster did not keep up with the Workload, I am surprise by the results

I notice something interesting, it seems, Databricks does not support result cache, what’s currently supported is SSD cache, it seems the Engine cache the raw data in the Local SSD, but the Engine will run the same Query even when the table did not change and it is the same SQL expression.
Using Performance analyser in PowerBI, the Query return in around 1.5 to 3 second, definitely it is not a sub second territory here.

Second try
Turn out the sample data Provided by Databricks is located in Washington state, in my defence, I thought when you create a new account, they copy the data in your account, that’s not the case.

I copy the same data into my local storage
redone the same test using 4 instance of PowerBI instead of 3, and Databricks behaved way better !!!!

Result Cache
The result cache implementation in Databricks is a bit unusual , Take this Query as an example
select
`o_custkey`,
sum(`l_quantity`) as `C1`,
count(1) as `C2`
from
(
select
`OTBL`.`l_quantity`,
`ITBL`.`o_custkey`
from
`hive_metastore`.`default`.`lineitem` as `OTBL`
inner join (
select
`o_orderkey`,
`o_custkey`,
`o_orderstatus`,
`o_totalprice`,
`o_orderdate`,
`o_orderpriority`,
`o_clerk`,
`o_shippriority`,
`o_comment`
from
`hive_metastore`.`default`.`orders`
where
`o_custkey` in (5, 11, 140, 4)
) as `ITBL` on (`OTBL`.`l_orderkey` = `ITBL`.`o_orderkey`)
) as `ITBL`
group by
`o_custkey`
limit
1000001
the First run took 2.75 second

The Second Run, which should be cached as I did not change the tables

1.19 second, is not a great result, I know Snowflake result cache return around 50 ms, and BigQuery around 100- 200 ms, if I understood correctly Because Databricks use an Open Storage Format, it has always to go back to Azure storage and check if something has changed, which introduce and extra latency.
Random Thoughts
Databricks SQL is a Data-Warehouse, in my opinion all this talk about lake House is just a distraction, as far as I can see, it is a Solid DWH with an open storage format ( it is a good thing), it is multi cloud which is a big advantages and the team is investing a lot in new functionalities.
I am aware that the biggest competitive advantage of Databricks compare to Snowflake is Delta Lake, its open table format, basically you can read your data for free see example here with PowerBI or you can use literally another Compute engine, but in this first look, I was only interested in Query performance not the overall architecture. (BigQuery has an open Storage API but it is not free)
Engine Startup time is really slow, 5 minute is too much, specially when other vendors offer 5 second startup ( Looking forward for the serverless preview in Azure).
I am not sure what’s going on exactly with concurrency, it seems Databricks is really good at aggregating massive data, but I am not sure, if is suited for High concurrency , low latency needed for Interactive BI Workload.
Databricks Got me interested in their engine, I need further testing, but it seems we have another interesting Azure DWH offering (Beside Snowflake).
After I quickly tested Azure Synapse ( Both Serverless and Dedicated) and Snowflake, I think for high Concurrency, Low latency , small dataset workload, Snowflake has an advantage, Databricks is a second, Synapse does not support this workload at all.
Some readers thought I was a bit unfair to databricks but that was not the intention as far as I am concerned, in the last 10 years, we saw some serious innovation in Data warehouse space.
BigQuery separating Storage from Compute.
Snowflake introducing the 60 second pricing Model, and being Multi Cloud
Databricks going even further and making the Storage open, so your data is not tied to one Engine.

2 thoughts on “First Impression of Databricks SQL”