A quick post on a nice functionality in BigQuery, if you create a Materialized view based on Table X, and you run a Query on that Table, the Query Optimizer is smart enough to reroute the Query plan to use the materialized View instead of the base Table, it is faster and substantially cheaper.
for example, let’s take this table which has a granularity of 5 minute ( 75 Million Records)
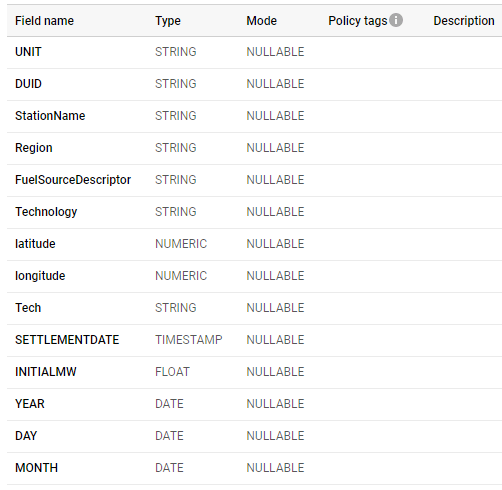
let’s create a Materialized view that aggregate at the day Level
CREATE MATERIALIZED VIEW XXXXX.ReportingDataset.UNITARCHIVE_Summary AS SELECT StationName, DUID, DAY, SUM(Mwh) AS Mwh FROM `XXXXXX.ReportingDataset.UNITARCHIVE` GROUP BY 1, 2, 3
The resulting MV is 16 MB, and 350K rows , notice once you create a MV, you can forget about it, BigQuery make sure it is updated, and for whatever reason if the MV was not updated the Query planner will default back to the base Table, please see documentation for further details
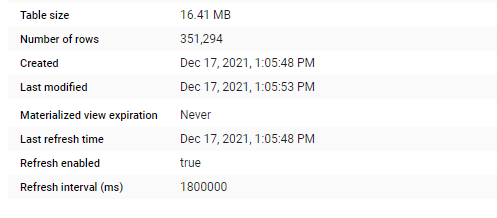
Now here is the interesting Part, let’s make a Query that target the Base Table
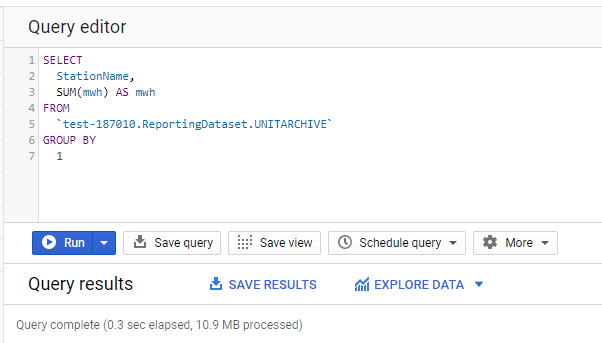
because the fields used in the Query exist already in the MV, the Query optimizer change the Query plan to use the MV, instead of scanning GB of data, it end up scanning 10 MB.
How About BI Engine
When Using BigQuery BI Engine performance wise both Queries either Base table or MV will return results in millisecond, but I suspect using Materialized view is beneficial as it uses less resources which means potential even more concurrency.

One thought on “BigQuery Materialized View optimization”