
TL:DR ; Databend is a new Data warehouse vendor, they have a paid Cloud service for Enterprise workload, but offer a full DWH engine as a Python Package, you can download a notebook that uses Cloudflare R2 as a remote storage
Introduction
Note : This Blog is a quick introduction to the Python library and will not review the commercial offering
DWH as a code was first coined by the famous TJ the idea is very simple, you just write a python script to process data interactively from a remote storage, basically in the simplest use case, you don’t necessarily needs a middle man, sorry I meant a DWH, you run an Engine like DuckDB or Polars, and you get your results, Databend push this concept even further with the native support of a custom built lakehouse table format and support for disk cache and even result cache, yes in a notebook, who would have thought that !!!!
Databend Architecture
Databend architecture is a typical Modern cloud data warehouse, contrary to something like Snowflake, everything is open source
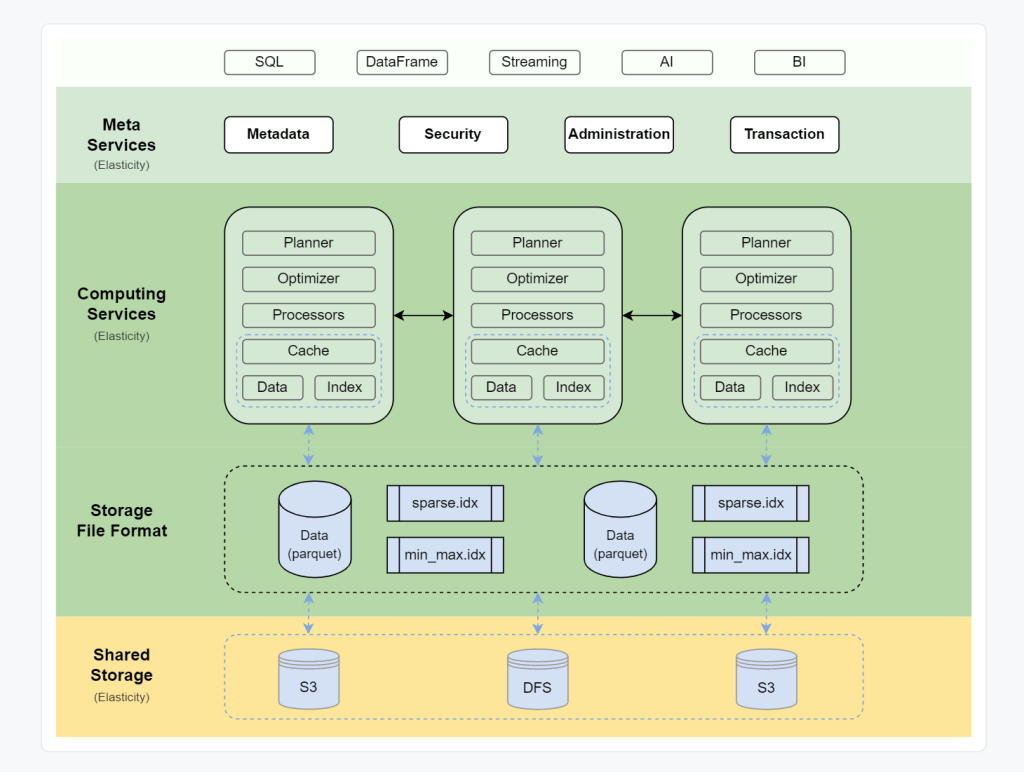
in a notebook environment some layers don’t make much sense, you can install a docker image but that’s not something that interests me.
Setup
I built a Python notebook that generate some data ( using TPCH ) load it to Cloudflare R2, it works obviously with S3, but R2 has free egress fees.
- First Run : Directly from remote storage
- Disk cache : if the data was already downloaded in the VM of the notebook, it will run locally
- Result cache : if the exact query was run again and the base Table did not change then results are returned in a sub 20 ms !!!
Databend use a native table format called strawboat that looks like Apache Iceberg, you can read the details here, I know probably it is much more complicated than that but in mind, snapshot is an iceberg thing, transaction log is a delta table concept.
Load Data into R2
I Think databend can’t use “create or replace” syntax, so I had to drop the table if exist then recreated, the syntax is pretty standard, you need only to have R2 credential

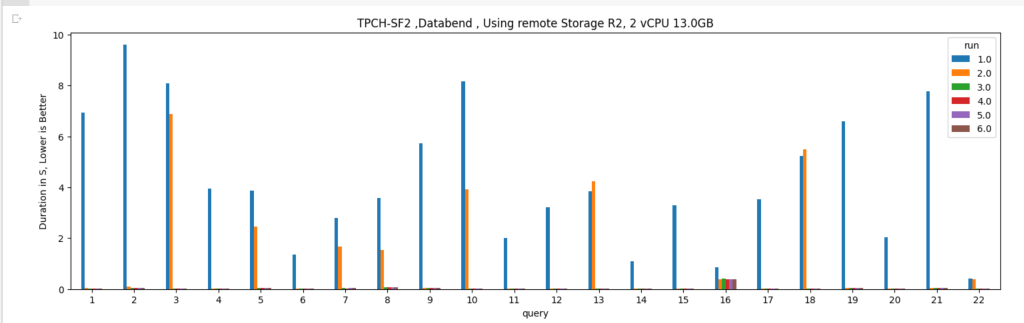
Run TPCH Queries
I modified the first Query of TPCH to scan the whole “Linitem” table just to test the disc cache, notice that in Python the disk cache is not on by default and you have to turn it on by passing an environment variable

The same for the result cache,

And here are the results. Please note the first run is dependent on R2 throughput and says nothing about Databend performance, you will notice the result cache takes virtually no time.
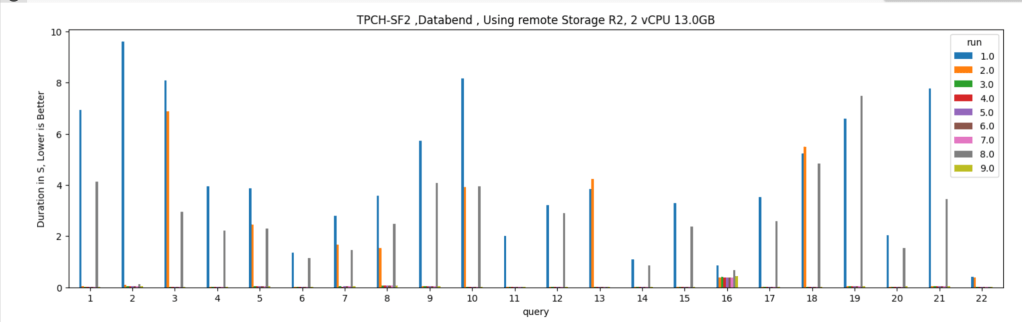
Cache Invalidation
Just to mess with it, I delete some rows from table “lineitem” and “customer”

which invalidate the result cache and disk cache, and trigger a remote scan, I can’t believe I am writing this about a SQL Engine running from a notebook
Take away
That was just a quick introduction, the python API is still in the early stage for example, the metadata layer is saved locally in the notebook which I think it is not very convenient, the dev said they can do something about, but it is really refreshing to see new startup building new products with new ideas.
