TL;DR : a proof of concept how to assemble a ‘Toy’ Lakehouse using Delta Table and DuckDB, You can download the Notebook here . Cloud storage throughput is the bottleneck of the system, I will appreciate a vote on this feature request
Delta lake one of the main storage file format used by Databricks and Microsoft has an experimental support for a standalone reader, it means you don’t need a big Data Engine to read it nor to write it, it is experimental at this stage but under active development.
I already blogged about it already, But I was using my laptop, turn out it works relatively well using any major Cloud storage provider, initially I tried Azure Cloud Storage and it did works, but I could not find any free Azure notebook offering, and I am not interested in paying any egress fees, instead I end up used Google Cloud Storage and Colab
I would like to talk more about arrow dataset, which I think is an amazing technology
The Overall Idea is simple, I have a delta table in a cloud storage created by something like Apache Spark, DuckDB can’t read Delta Directly but instead I am using the Delta lake python package that can produce an arrow Dataset whch can be Queried by DuckDB or any other engine that support Arrow.
Arrow Dataset
Let’s look at this section of the code, as per the documentation, an arrow dataset does not copy the data but it is like a Virtual Table that knows about all the files inside that particular path, what’s exciting in theory Engine does not need to know about the storage at all, if it is csv, parquet or something else.
For example in the future, a Query engine would not even care if the Table is Delta or Iceberg, obviously it is not the case today but there is no reason it will not happen.
Filter Pushdown
When you read data from a cloud storage, for latency issues, it make sense to read the minimum possible number of files, currently only filter partition works, but they are working on adding filter on any columns
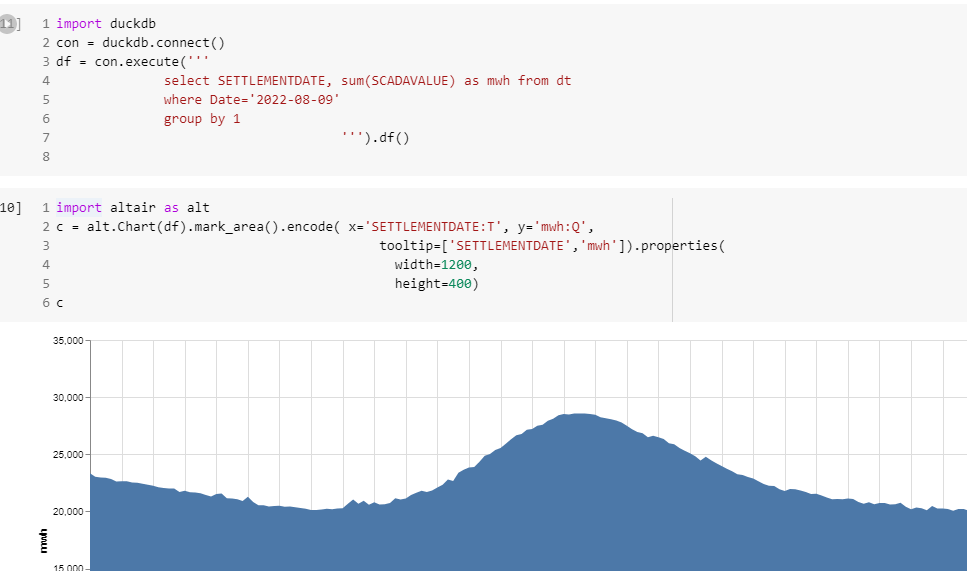
Final results
Currently, it is not particularly fast, but I can Query the Data Directly from a cloud storage and show arbitrary chart.
Local Cache
If the data is small and fit the notebook SSD, and does not change very often, it make sense to first download the data into a local DuckDB Database file and run Queries locally , it will be substantially Faster.
Take Away
I was a bit suspicious about this whole Lake House thing, but maybe I was wrong about it, having an open storage format will open all kind of interesting possibilities and that’s a very good thing.
As you can see, anyone can build a lake house, now we need to figure out a boring details, the overall performance of the system 🙂

One thought on “Poor Man’s lakehouse using Cloud Storage, Delta lake and DuckDB”