it is a quick post on how to query Onelake Iceberg REST Catalog using pure SQL with DuckDB, and yes you need a service principal that has access to the lakehouse
it works reasonably well assuming your region is not far from your laptop, or even better , if you run it inside Fabric then there is no network shenanigans, I recorded a video showing my experience
Why read operations do not always need full consistency checks
I hope DuckDB eventually adds an option that allows turning off table state checks for purely read scenarios. The current behaviour is correct because you always need the latest state when writing in order to guarantee consistency. However, for read queries it feels unnecessary and hurts the overall user experience. PowerBI solved this problem very well with its concept of framing, and something similar in DuckDB would make a big difference, notice duckdb delta reader already support pin version.
I know it is a niche topic, and in theory, we should not think about it. in import mode, Power BI ingests data and automatically optimizes the format without users knowing anything about it. With Direct Lake, it has become a little more nuanced. The ingestion part is done downstream by other processes that Power BI cannot control. The idea is that if your Parquet files are optimally written using Vorder, you will get the best performance. The reality is a bit more complicated. External writers know nothing about Vorder, and even some internal Fabric Engines do not write it by default.
To show the impact of read performance for Vordered Parquet vs sorted Parquet, I ran some tests. I spent a lot of time ensuring I was not hitting the hot cache, which would defeat the purpose. One thing I learned is to test only one aspect of the system carefully.
Cold Run: Data loaded from OneLake with on-the-fly building of dictionaries, relationships, etc
Warm Run: Data already in memory format.
Hot Run: The system has already scanned the same data before. You can disable this by calling the ClearCache command using XMLA (you cannot use a REST API call).
Prepare the Data
Same model, three dimensions, and one fact table, you can generate the data using this notebook
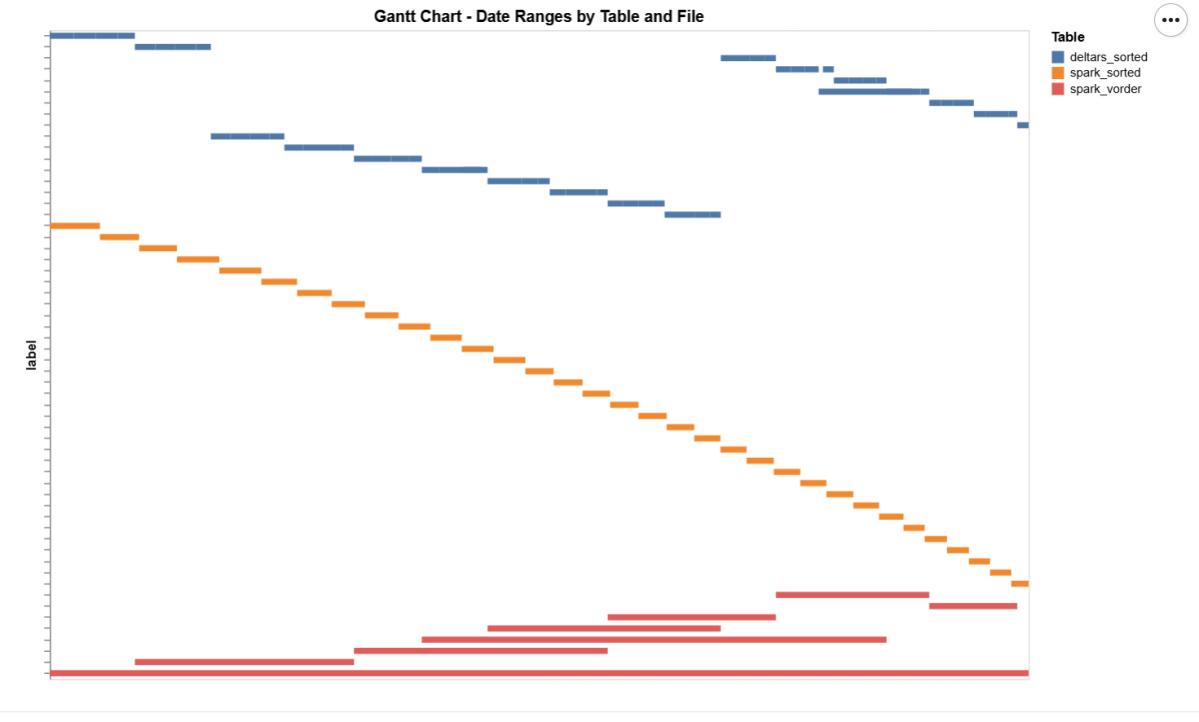
Deltars: Data prepared using Delta Rust sorted by date, id, then time.
Spark_default: Same sorted data but written by Spark.
Spark_vorder: Manually enabling Vorder (Vorder is off by default for new workspaces).
Note: you can not sort and vorder at the same time, at least in Spark, DWH seems to support it just fine
The data layout is as follows:
I could not make Delta Rust produce larger row groups. Notice that ZSTD gives better compression, although it seems Power BI has to uncompress the data in memory, so it seems it is not a big deal
I added a bar chart to show how the data is sorted per date. As expected, Vorder is all over the place, the algorithm determines that this is the best row reordering to achieve the best RLE encoding.
The Queries
The queries are very simple. Initially, I tried more complex queries, but they involved other parts of the system and introduced more variables. I was mainly interested in testing the scan performance of VertiPaq.
def run_test(workspace, model_to_test):
for i, dataset in enumerate(model_to_test):
try:
print(dataset)
duckrun.connect(f"{ws}/{lh}.Lakehouse/{dataset}").deploy(bim_url)
run_dax(workspace, dataset, 0, 1)
time.sleep(300)
run_dax(workspace, dataset, 1, 5)
time.sleep(300)
except Exception as e:
print(f"Error: {e}")
return 'done'
Deploy automatically generates a new semantic model. If it already exists, it will call clearvalue and perform a full refresh, ensuring no data is kept in memory. When running DAX, I make sure ClearCache is called.
The first run includes only one query; the second run includes five different queries. I added a 5-minute wait time to create a clearer chart of capacity usage.
Capacity Usage
To be clear, this is not a general statement, but at least in this particular case with this specific dataset, the biggest impact of Vorder seems to appear in the capacity consumption during the cold run. In other words:
Transcoding a vanilla Parquet file consumes more compute than a Vordered Parquet file.
Warm runs appear to be roughly similar.
Impact on Performance
Again, this is based on only a couple of queries, but overall, the sorted data seems slightly faster in warm runs (although more expensive). Still, 120 ms vs 340 ms will not make a big difference. I suspect the queries I ran aligned more closely with the column sorting—that was not intentional.
Takeaway
Just Vorder if you can. Make sure you enable it when starting a new project. ETL, data engineering have only one purpose, make the experience of the end users the best possible way, ETL job that take 30 seconds more is nothing compared to a slower PowerBI reports.
now if you can’t, maybe you are using a shortcut from an external engine, check your powerbi performance if it is not as good as you expect then make a copy, the only thing that matter is the end user experience.
Another lesson is that VertiPaq is not your typical OLAP engine; common database tricks do not apply here. It is a unique engine that operates entirely on compressed data. Better-RLE encoded Parquet will give you better results, yes you may have cases where the sorting align better with your queries pattern, but in the general case, Vorder is always the simplest option.
While preparing for a presentation about the FabCon announcement, one item was about OneLake Diagnostics. all ll I knew was that it had something to do with security and logs. As a Power BI user, that’s not exactly the kind of topic that gets me excited, but I needed to know at least the basic, so I can answer questions if someone ask 🙂
Luckily, we have a tradition at work , whenever something security-related comes up, we just ping Amnjeet🙂
He showed me how it works , and I have to say, I loved it. It’s refreshingly simple.
You just select a folder in your Lakehouse and turn it on.
That’s it , the system automatically starts generating JSON files, neatly organized using Hive-style partitions, By default, user identity and IP tracking are turned off unless an admin explicitly enables them. You can find more details about the schema and setup here.
What the Logs Look Like
Currently, the logs are aggregated at the hourly level, but the folder structure also includes a partition for minutes (even though they’re all grouped at 00 right now).
Parsing the JSON Logs
Once the logs were available, I wanted to do some quick analysis , not necessarily about security, just exploring what’s inside.
There are probably half a dozen ways to do this in Fabric ; Shortcut Transform, RTI, Dataflow Gen2, DWH, Spark, and probably some AI tools too, Honestly, that’s a good problem to have.
But since I like Python notebooks and the data is relatively small, I went with DuckDB (as usual), but Instead of using plain DuckDB and delta_rs to store the results, I used my little helper library, duckrun, to make things simpler ( Self Promotion alert).
Then I asked Copilot to generate a bit of code for registering existing functions to look up the workspace name and lakehouse name from their GUIDs in DuckDB, using SQL to call python is cool 🙂
The data is stored incrementally, using the file path as a key , so you end up with something like this:
Then I added only the new logs with this SQL script:
try:
con.sql(f"""
CREATE VIEW IF NOT EXISTS logs(file) AS SELECT 'dummy';
SET VARIABLE list_of_files =
(
WITH new_files AS (
SELECT file
FROM glob('{onelake_logs_path}')
WHERE file NOT IN (SELECT DISTINCT file FROM logs)
ORDER BY file
)
SELECT list(file) FROM new_files
);
SELECT * EXCLUDE(data), data.*, filename AS file
FROM read_json_auto(
GETVARIABLE('list_of_files'),
hive_partitioning = true,
union_by_name = 1,
FILENAME = 1
)
""").write.mode("append").option("mergeSchema", "true").saveAsTable('logs')
except Exception as e:
print(f"An error occurred: {e}")
1- Using glob() to collect file names means you don’t open any files unnecessarily , a small but nice performance win.
2- DuckDB expand the struct using this expression data.*
3- union_by_name = 1 in case the json has different schemas
4- option(“mergeSchema”, “true”) for schema evolution in Delta table
Exploring the Data
Once the logs are in a Delta table, you can query them like any denormalize table.
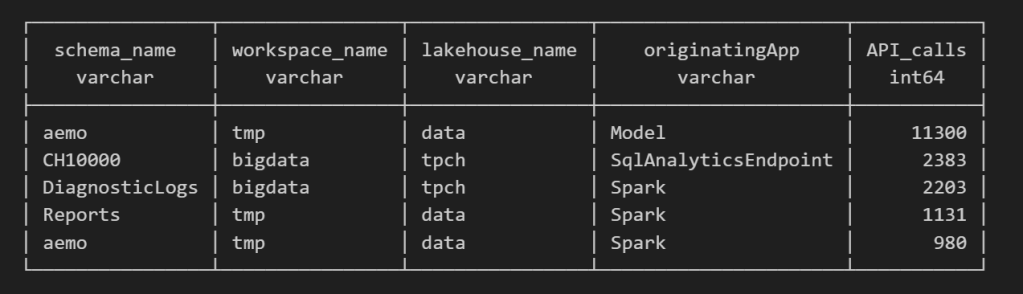
For example, here’s a simple query showing API calls per engine:
Note : using AI to get working regex is maybe the best thing ever 🙂
SELECT
regexp_extract(resource, '([^&/]+)/([^&/]+)/(Tables|Files)(?:/([^&/]+))?(?:/([^&/]+))?', 4) AS schema_name,
get_workspace_name(workspaceid) AS workspace_name,
get_lakehouse_name(workspaceid, itemId) AS lakehouse_name,
originatingApp,
COUNT(*) AS API_calls
FROM logs
GROUP BY ALL
ORDER BY API_calls DESC
LIMIT 5;
Fun fact: OneLake tags Python notebook as Spark. Also, I didn’t realize Lineage calls OneLake too!
as I have already register Python functions as UDFs, which is how I pulled in the workspace and lakehouse names in the query above.
Takeaway
This was just a bit of tinkering, but I’m really impressed with how easy OneLake Diagnostics is to set up and use.
I still remember the horrors of trying to connect Dataflow Gen1 to Azure Storage ,that was genuinely painful (and I never even got access from IT anyway).
It’s great to see how Microsoft Fabric is simplifying these scenarios. Not everything can always be easy, but making the first steps easy really gives the feature a very good impression.
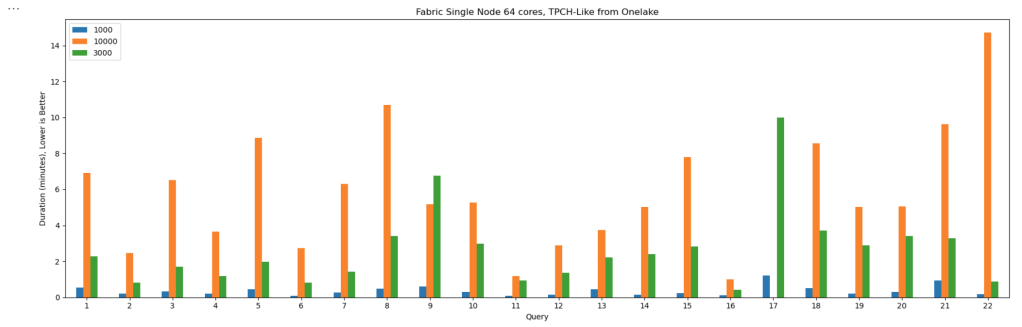
This started as just a fun experiment. I was curious to see what happens when you push DuckDB really hard — like, absurdly hard. So I went straight for the biggest Python single-node compute we have in Microsoft Fabric: 64 cores and 512 GB of RAM. Because why not?
Setting Things Up
I generated data using tpchgenand registered it with delta_rs. Both are Rust-based tools, but I used their Python APIs (as it should be, of course). I created datasets at three different scales: 1 TB, 3 TB, and 10 TB.
From previous tests, I know that Ducklake works better, but I used Delta so it is readable by other Fabric Engines ( as of this writing , Ducklake does not supporting exporting Iceberg metadata, which is unfortunate)
The goal wasn’t really about performance . I wanted to see if it would work at all. DuckDB has a reputation for being great with smallish data, but wanted to see when the data is substantially bigger than the available Memory.
And yes, it turns out DuckDB can handle quite a bit more than most people assume.
The Big Lesson: Local Disk Matters
Here’s where things got interesting.
If you ever try this yourself, don’t use a Lakehouse folder for data spilling. It’s painfully slow(as the data is first written to disk then uploaded to remote storage)
Instead, point DuckDB to the local disk that Fabric uses for AzureFuse caching. That disk is about 2 TB. or any writable folder
You can tell DuckDB to use it like this:
SET temp_directory = '/mnt/notebookfusetmp';
Once I did that, I could actually see the data spilling happening in real time which felt oddly satisfying, it works but slow , it is better to just have more RAM 🙂
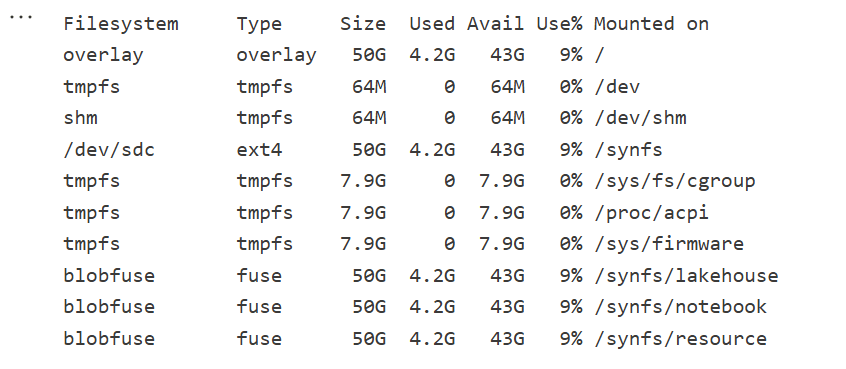
Python notebook is fundamentally just a Linux VM, and you can see the storage layout using this command
!df -hT
Here is the layout for 2 cores
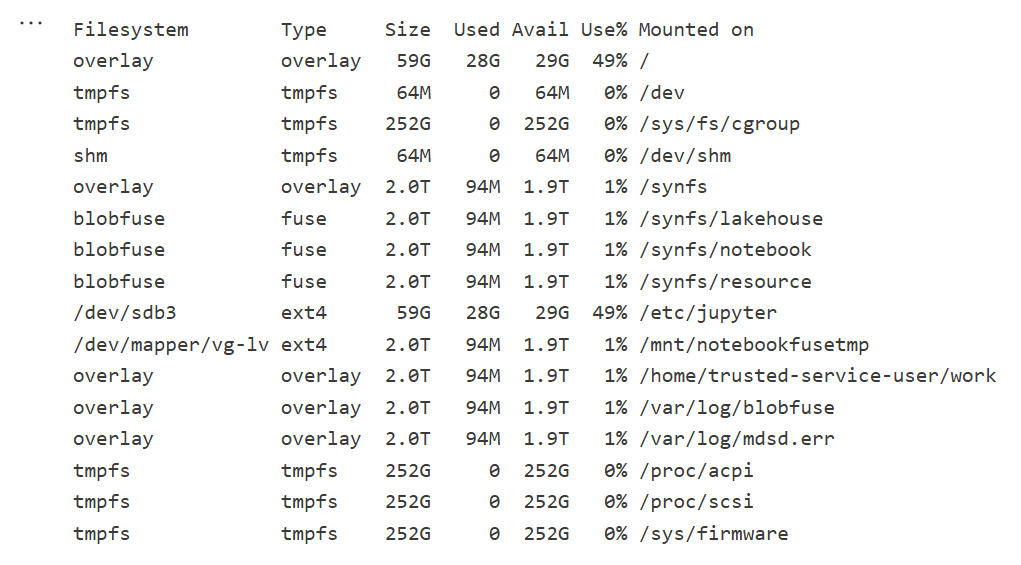
Which is different when running it for 64 cores ( container vs VM, something like that), I notice the local disk increased with more cores, which make sense
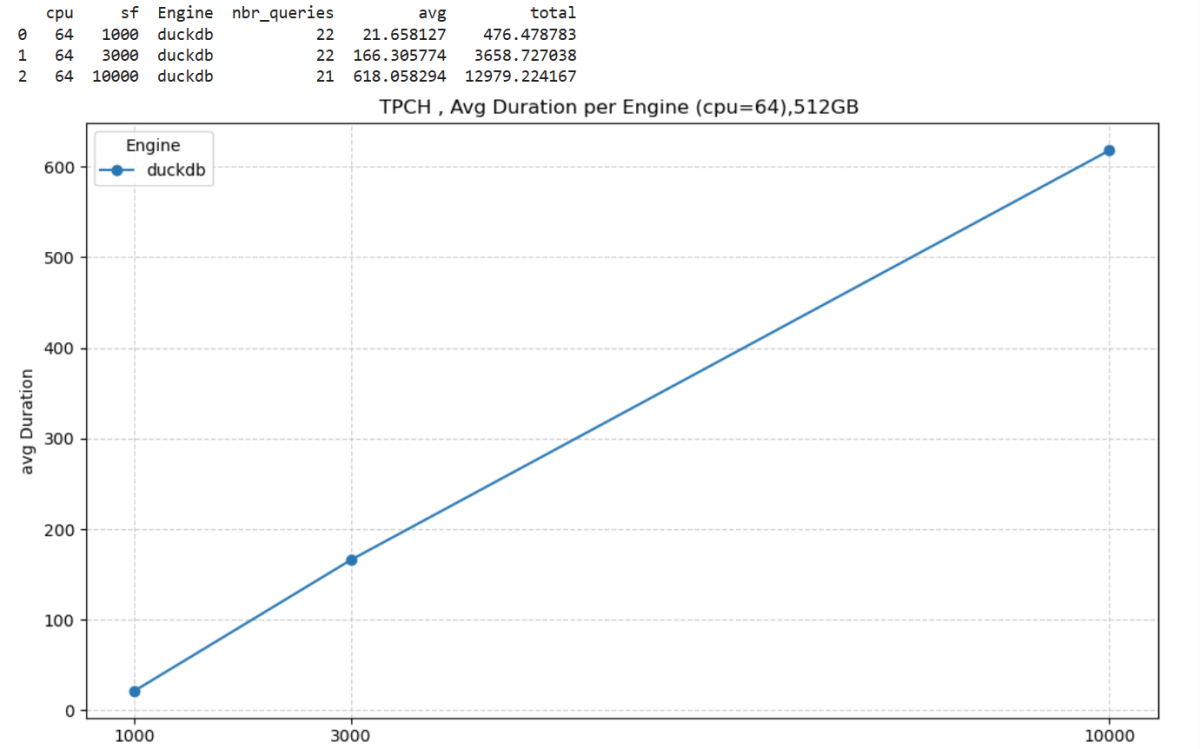
The Results
Most queries went through without too much trouble. except Query 17 at 10 TB scale? That one It ran for more than an hour before my authentication token expired. So technically, it didn’t fail 🙂
DuckDB does not have a way to refresh Azure token mid query. as far as I know
Edit : according to Claude, I need at least 1-2 TB of RAM (10-20% of database size) to avoid disk thrashing
Observations: DuckDB’s Buffer Pool
Something I hadn’t noticed before is how the buffer pool behaves when you work with data way bigger than your RAM. It tends to evict data that was just read from remote storage — which feels wasteful. I can’t help but think it might be better to spill that to disk instead.
I’m now testing an alternative cache manager called duck-read-cache-fs to see if it handles that better. We’ll see, i still think it is too low level to be handled by an extension, I know MotherDuck rewrote their own buffer manager, but not sure if it is for the same reason.
Why not test other Engines
I did, actually , and the best result I got was with Lakesail at around 100 GB. Beyond that, no single-node open-source engine can really handle this scale. Polars, for instance, doesn’t support spilling to disk at all and implements fewer than 10 of the 22 standard SQL queries.
Wrapping Up
So, what did I learn? DuckDB is tougher than it looks. With proper disk spilling and some patience, it can handle multi-terabyte datasets just fine, and sometimes the right solution is just to add more RAM
personally , I never had a need for TB of data ( my sweet spot is 100 GB) and distributed system (Like Fabric DWH, Spark etc) will handle this use case way better, after all they were designed for this scale.
But it’s amazing to see how far an in-process database has come 🙂 just a couple of years ago, I was thrilled when DcukDB could handle 10 GB!