Edit : this blog generated some strong feedback, This is not a benchmark of Vertipaq, but rather me arguing that it is indeed possible to have a good enough OLAP SQL Engine that read from disk instead of RAM ?
Vertipaq is the columnar Database used In PowerBI, Excel and Analysis service, it is an extremely fast DB and I have being using it since 2015 without really understanding how it works, it is just there giving back results in sub second, the only time I got performance issue was when I wrote terribly bad DAX.
Just for fun and hopefully we may even learn something useful, I run a couple of simple SQL Queries in DuckDB and replicate them in PowerBI desktop and see how the two system behave,Unfortunately Vertipaq don’t expose a fully functional SQL Endpoint, so you can’t simply run a typical SQL benchmark.
Setup
All test were done using my laptop ( a Dell with 16 GB of RAM), the data is TPCH-SF10, 60 million of rows for the base table, I had to add a PK for PowerBI as it does not support join on multiple fields, you can download the raw Data here
DuckDB queries were run using Visual studio notebook, I would had prefered Malloy but it does not support native DuckDB storage format yet , you can download the python files here and how to create the DB and Tables
For PowerBI, I use DAX Studio with cache turned off.
Loading Data
DuckDB support multiple mode, you can just run Queries directly on parquet files, you can load the data to memory using temp tables or you can import the data using DuckDB storage format, for performance reason I import the data, DuckDB don’t support compression very well yet, and consider the storage format as a work in progress, Index currently are not compressed and take a lot of space, without index, the size is around 3.6 GB
Parquet : 2.9 GB
DuckDB storage file format : 17 GB
Vertipaq : 3.9 GB
Notice here, DuckDB is reading from disk to run Queries, if does filter pushdown and scan only column used in Queries, Vertipaq has to load the whole database into memory before you can run any Queries, as far as I can tell this is the most important difference between the two systems and has a massive implication, both positive and negative.
Data Model
I am using the same Data Model as the previous blog, it is a nice bad Model for testing 🙂

1- Simple Count Distinct
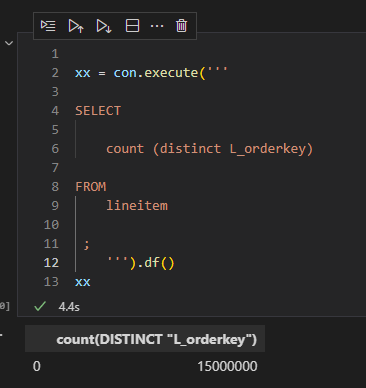
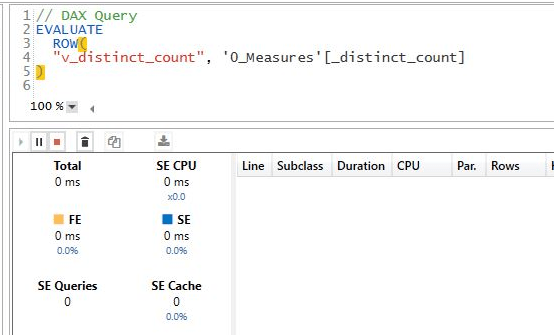
DuckDB : 4.4 S
Vertipaq : 0 S
For vertipaq it is a metadata Query, the distinct count for a whole column is created when you import the data, DuckDB don’t save that particular statistic.
2- Count Distinct group by low Cardinality
low cardinality simply means column with small number of unique values.
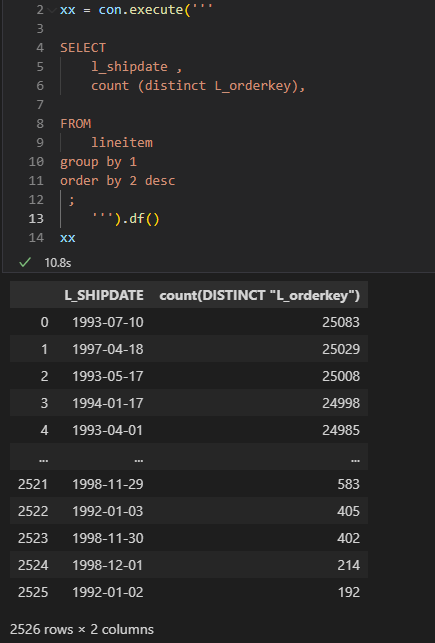

DuckDB : 10.8 S
Vertipaq : 7.1 S
3- Count Distinct group by high Cardinality
now count the distinct values but grouping by a column L_comments which contains 33 Million unique values


DuckDB : 49 S
Vertipaq : 29 S
4 – Sum group by low Cardinality
This one is using the Famous Query 1 of TPCH Benchmark


DuckDB : 0.7 S
Vertipaq : 0.3 S
5 – Sum group by high Cardinality


DuckDB : 2.7 S
Vertipaq : 17 S
6 – Aggregate using complex relationship but group by Low cardinality
The performance of Vertipaq keep surprising me, it is using some kind of index on joins, I don’t know really how it works, but the performance is impressive


DuckDB : 4.9 S
Vertipaq : 0.9 S
7 – Aggregate using complex relationship but group by High cardinality


DuckDB : 8.4 S
Vertipaq : 5.1 S
I was surprised by this results, it seems when you group by high cardinality column it will impact Vetipaq performance.
8 – Aggregate and filter on Text
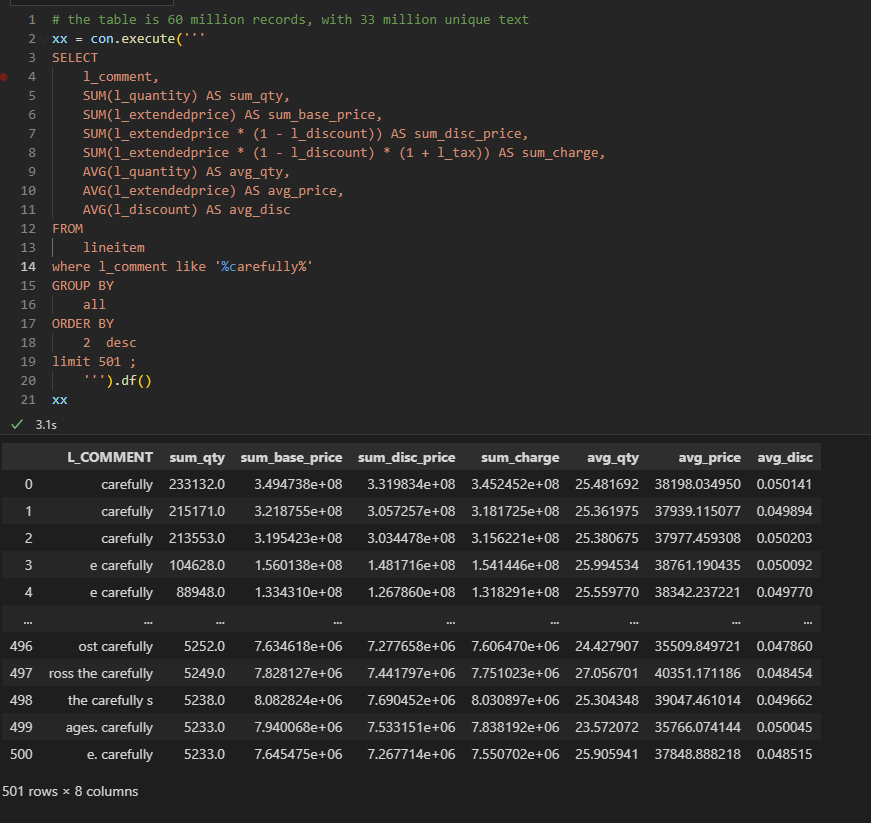
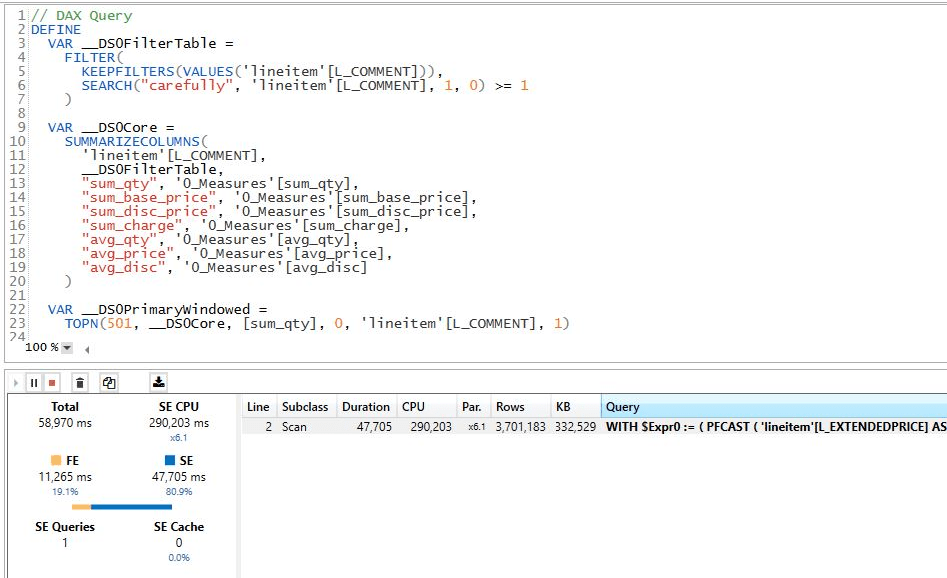
DuckDB : 3.1 S
Vertipaq : 58 S
The performance seems odd for vertipaq, maybe I am doing something wrong, but it should be straightforward
Edit : Alex was kind enough and provided this excellent explanation.

9- Count Distinct group by high Cardinality base Table 120 Million records
Basically that’s the point of the blog, yes Vertipaq works well because it does fit into my Laptop RAM, let’s try a complex Query using 120 Million ? I start getting memory errors

Actually the whole experience became sluggish, just saving any edits take ages.
Let’s try DuckDB, I will just Query from parquet, I don’t want to ingest 120 million records for one Query

Take Away
here is the summary results
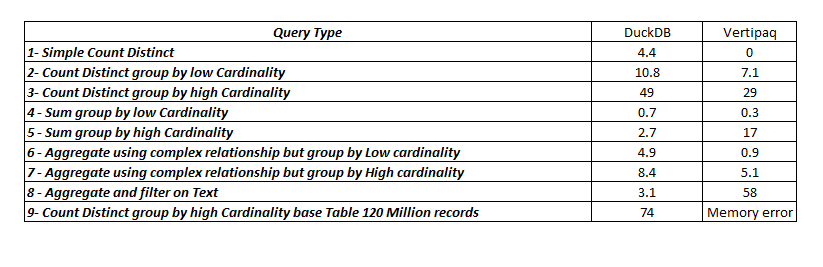
Vertipaq is extremely fast but the performance degrade when dealing with High cardinality columns, filtering using string seems slow though, the Index on join or whatever the engine is doing is genius, the result for the Query 4 and 6 are magic as far as I am concerned.
DuckDB is impressive especially with the fact it is reading from Disk, yes, it is slower than Vertipaq for a small Data size which is expected as generally speaking scanning from RAM will be faster than Disk, but it does scale better.
If your data don’t fit into the RAM, DuckDB seems like an interesting proposition.
