Disclaimer : this is not a scientific reproducible benchmark.
Edit : TL;DR, don’t use Synapse Serverless with Direct Query mode in PowerBI, it is an extremely bad idea.
One aspect that bother me about technical blogs nowadays, it seems cost is rarely considered, when the subject is about a fixed cost Product like PowerBI Pro license ( 1/user/10$/Month) then it is fine, we know what to expect, but when we talk about usage based Pricing, the cost structure is extremely important, a solution may be great for certain usage load, but it became just exorbitant when the load increases.
One particular architecture that some people start promoting as some kind of magical solution is the use of Synapse Serverless as a logical Data-warehouse, and somehow it can be used too as a live Query layer to PowerBI, I will argue in this blog that this setup is simple too expensive.
Testing Synapse Serverless Indirectly
My thinking is very simple, I was not very excited by the prospect of paying 200 dollars just to test Synapse Serverless, Instead I will test it indirectly, BigQuery BI Engine has a nice functionality that show how much data was scanned, it is for information only, we don’t pay by data scanned but instead in-memory reserved ( 1$/GB compressed/Day, minimum 1 hour).
The approach here is to get the volume of Data scanned and multiply it by 5$/TB (Synapse serverless Pricing) , I appreciate it is not 100 % accurate, but I hope will show a general pattern.
Load test using a PowerBI report
The Fact table is 12 GB, 72 Millions rows that get data add every 5 minutes, the Model is a simple Star Schema, I am using dual mode for the dimension Tables
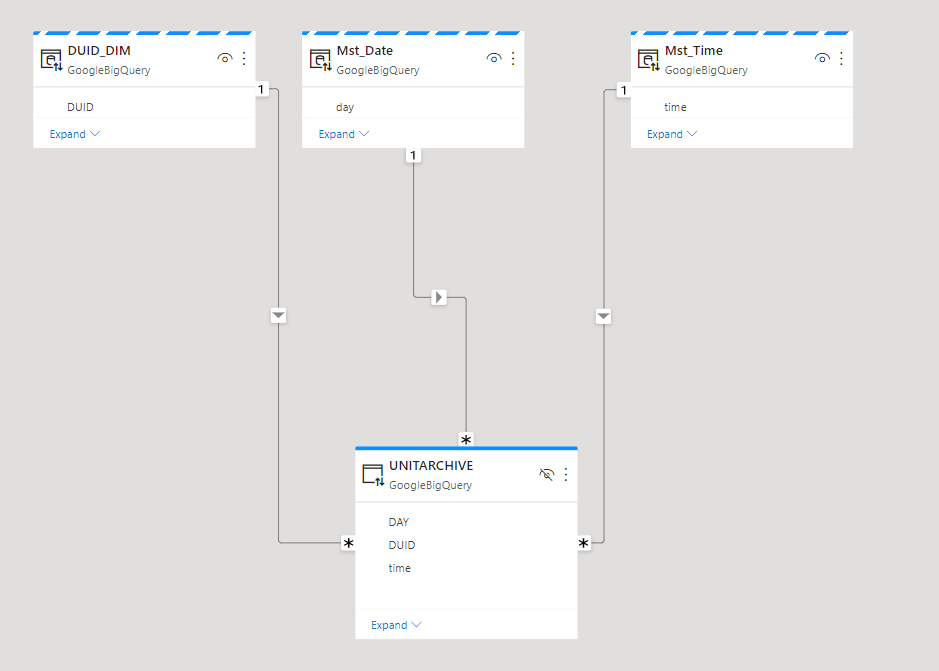
The test consist of using play Axis to loop on some dimension values every 5 second, I launched multiple copy of the same reports to generate more SQL Queries.
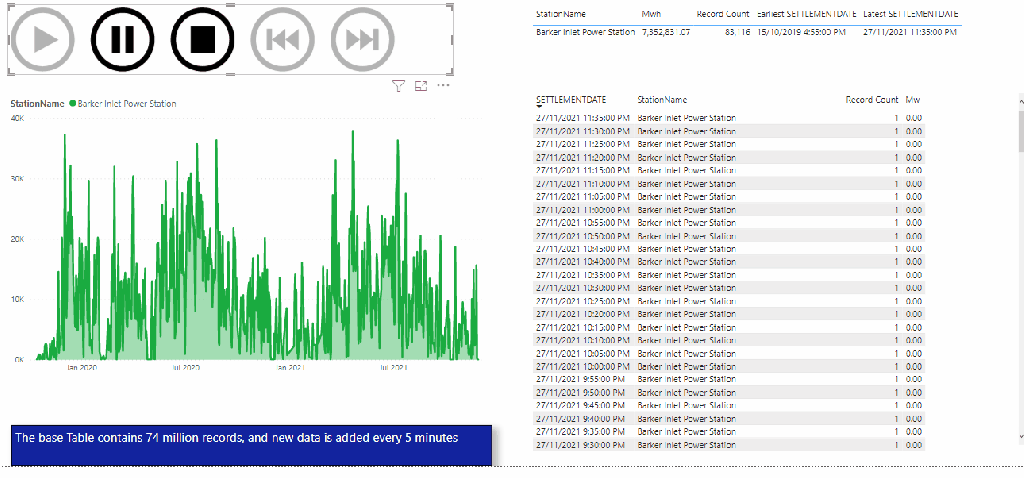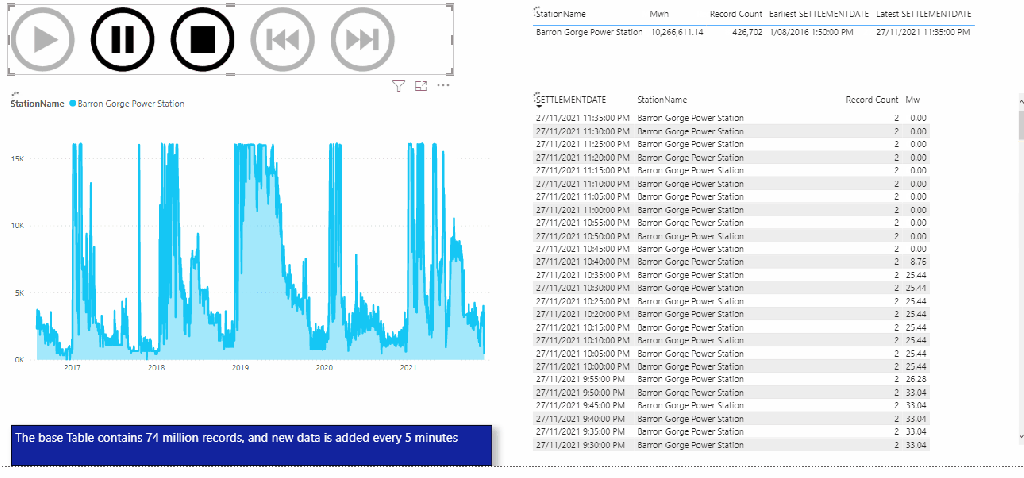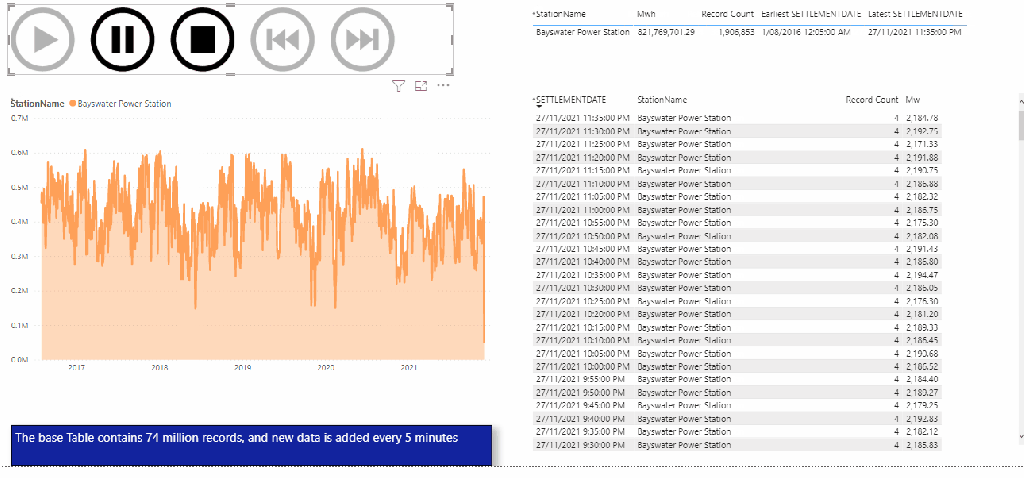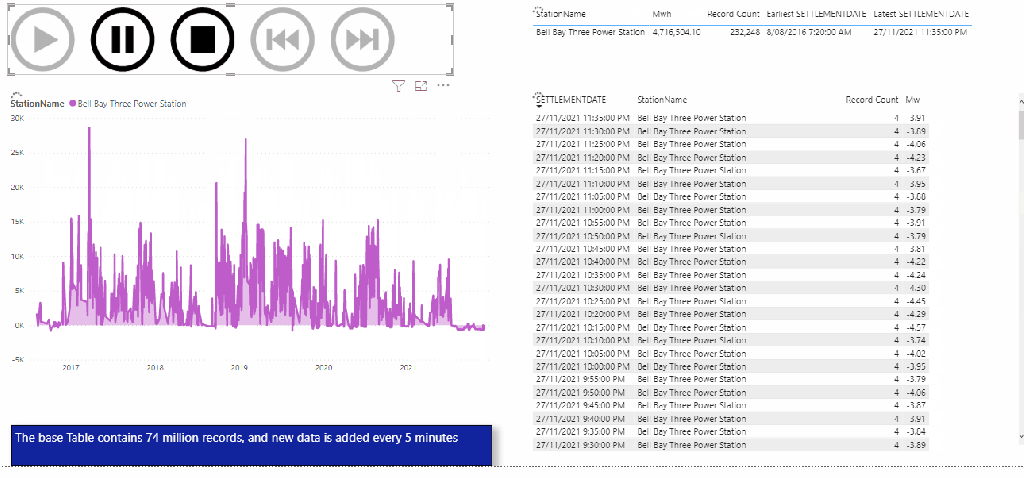
The Results
This table summarize the test results , more details in the report , please keep the filter between 22 Nov and 27 Nov 2021, as testing was done in that period.
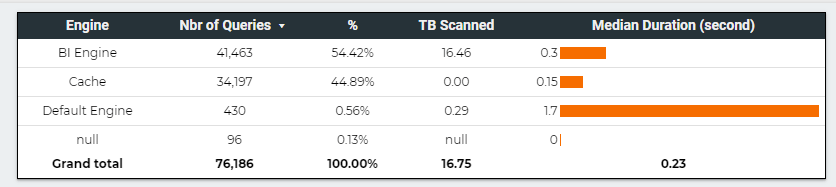
BigQuery BI engine is very fast, but that’s not the subject of the current blog, what’s interesting here is the volume of data scanned 16,75 TB, that’s a lot of data, which does not count for the cache.
For simplification purpose we estimate the cache to be the same ratio as scanned TB (16.46 * 44.89 %/54.42 %) = 13.58 TB
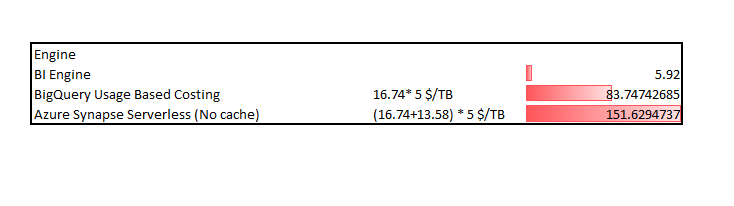
Synapse Serverless is 25 X more expensive than BigQuery BI Engine, and even if they add the result set cache it will be still 14 X more expensive ( Same as BigQuery without reservation)
Key findings
Interactive BI reports generate a massive number of SQL Queries, in our example, it was 76K Queries, which simply make SQL Engine that are cost based on data scanned too Much expensive.( Synapase Serverless and BigQuery default mode)
This scenario will be better served by a dedicated capacity, but as of this writing Synapse does not support auto suspense and auto resume which make it too expensive , and in any case, Synapse dedicated pool does not scale down well for small data ( hopefully Gen3 will fix that)
BigQuery BI Engine make Direct Query on PowerBI a viable solution, which is a great achievement and still with very competitive pricing.
Synapse Serverless is an interesting SQL Query Engine, but it not designed for heavy interactive BI load, I just hope people stop suggesting otherwise.
I think next year the battle for 100 GB interactive sub second BI workload will be an interesting space to watch, let’s see what Dedicated Pool Gen 3 , Databricks, Snowflake and Firebolt will bring to the table 🙂

3 thoughts on “Synapse Serverless vs BigQuery BI Engine using a dataset under 10 GB”