
Sometime to understand and appreciate how PowerBI Engine works is by comparing it to other product, when I was playing with thoughtspot, I noticed if you want to show items from a dimension that don’t have any value in the fact Table; you simply Model the relationship as a right join ( or full outer join to get values without a dimension item)
The Semantic Model is a very simple Star Schema with 1 Fact and 1 Dimension.
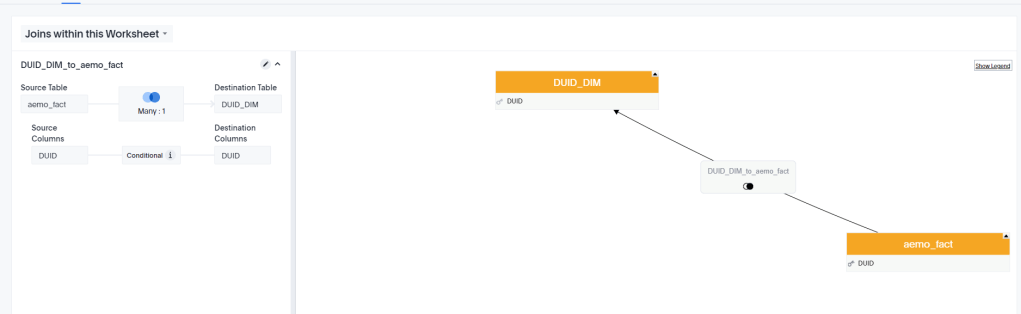
And here is the Query generated
SELECT
`ta_1`.`StationName` AS `ca_1`,
IFNULL(sum(`ta_2`.`Mwh`), 0) AS `ca_2`
FROM `testing-bi-engine`.`starschema`.`aemo_fact` AS `ta_2`
RIGHT OUTER JOIN `testing-bi-engine`.`starschema`.`DUID_DIM` AS `ta_1`
ON `ta_2`.`DUID` = `ta_1`.`DUID`
GROUP BY `ca_1`
LIMIT 1000
The Only reason, I noticed the right join, the Query was not accelerated by BigQuery BI Engine which is weird as the same Model in PowerBI was working fine !!! ( Btw, right join with small table should Work, I think it is a bug in BigQuery BI Engine, BI engine added support for right and full outer join)
Now I checked the same Model in PowerBI, using both Fact and Dimension as Direct Query
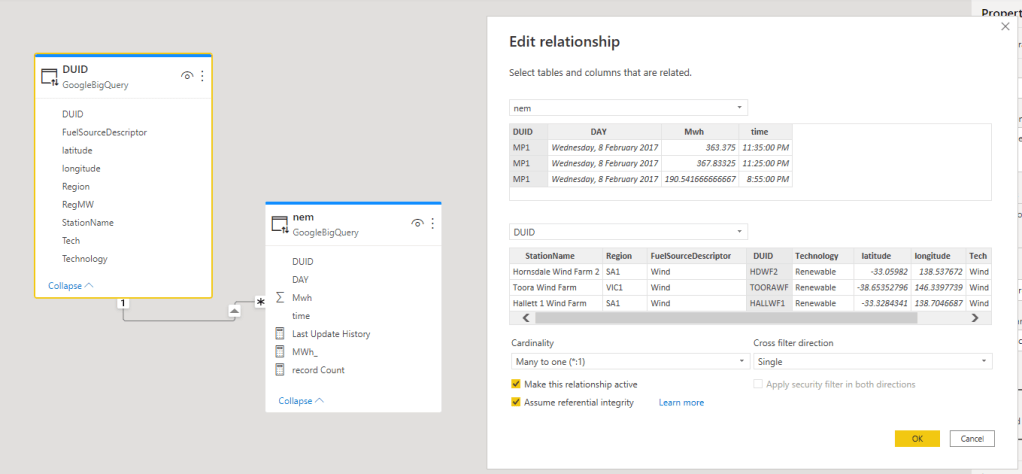
I am using only one visual using a Station Name from the dimension table and measure (Mwh) from the Fact Table
As expected because I am using “assume referential integrity” , the SQL Query generated will be an inner Join, one SQL Query is enough to get the data required.
select `StationName`,
`C1`
from
(
select `StationName`,
sum(`Mwh`) as `C1`
from
(
select `OTBL`.`Mwh`,
`ITBL`.`StationName`
from `test-187010`.`ReportingDataset`.`UNITARCHIVE` as `OTBL`
inner join `test-187010`.`ReportingDataset`.`DUID_DIM` as `ITBL` on (`OTBL`.`DUID` = `ITBL`.`DUID`)
) as `ITBL`
group by `StationName`
) as `ITBL`
where not `C1` is null
LIMIT 1000001 OFFSET 0
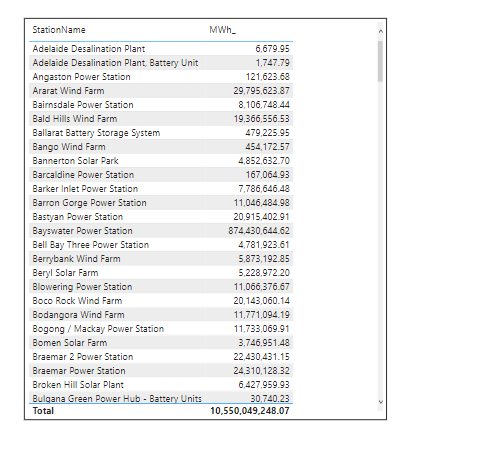
Show Items with no data
Now let’s add this option, Show items with no data ( Station Name that have null value in the Fact)
To get the required Data, you would expect a right join ? or maybe a left join from dimension to fact, I am glad that PowerBI Engine is not using either options, as Both are not optimized for BigQuery BI Engine, as a matter of Fact PowerBI Engine use only left join and inner join.
BI Engine is designed for a Big Fact table and smaller Dimension Tables ( 5 Millions as of this writing) my understanding it is a good practice for performance to have the small table at the left join side( this apply to other distributed Query Engine too like Synapse), anyway the Queries generated by PowerBI are fully accelerated and that’s a great news.
Using DAX Studio, I can see that PowerBI has generated two SQL Queries

one inner join to get the measures by dimension from the fact, and another Query to get all the items from the dimension Table, Then The Formula Engine join the results.
Ok why Should I care about Dual Mode ?
The answer is simply performance, let’s change the dimension Table to dual Mode
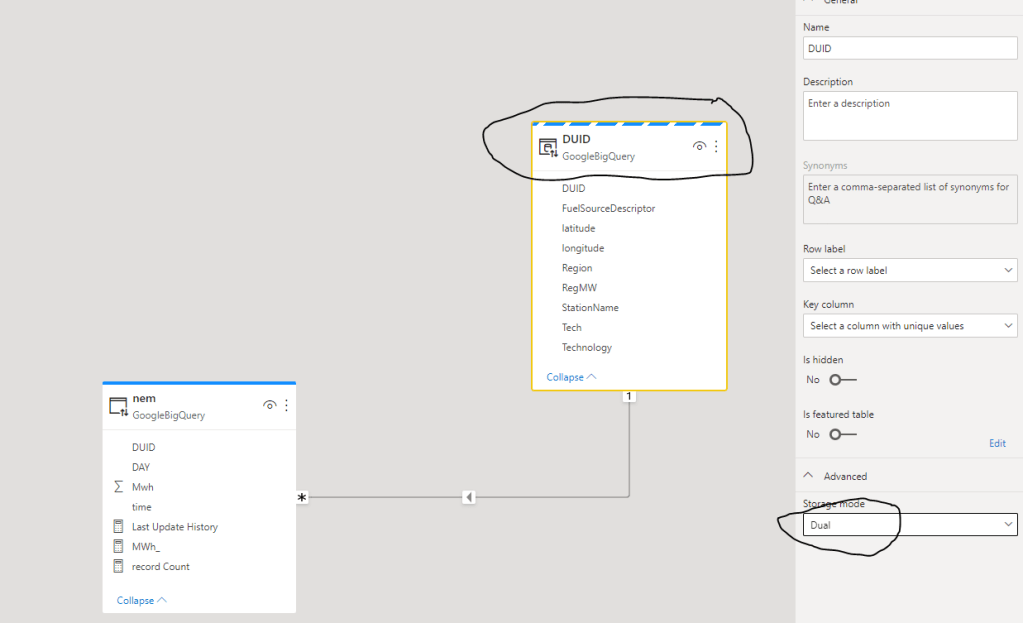
Now Let’s run the report again and see the Query generated using DAX Studio, yes it is still 2 Queries, but now the second Query is hitting the local cache (notice the word scan ) and the duration is basically 0 ms, so we saved nearly 2 seconds
It is all about the Slicer
Now let’s add a slicer to the the report, Both tables in Direct Query Mode

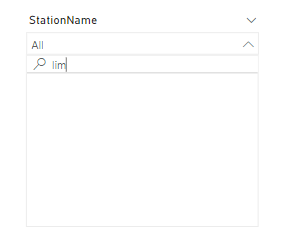
First issue , it is case sensitive, if you search “lim” you get nothing
The Second Problem, every search and selection trigger a new Query , Based on my own experience, a user can wait for a report a couple of second to get results, but if the slicer is not instantaneous, they will thinks something is not working
When I change the Dimension to Dual Mode, the search is instantaneous and not case sensitive, and the report will send only 1 query to get the results back

What’s the catch !!!
Dual Mode means the Table has to be refreshed to get the latest Data, if your dimension table change very frequently ( like a couple of second ), then you will get the same limitation of data import, but I think usually this is not the case, in the previous example the dimension change once a couple of months.
Take Away
If you have a Direct Query scenario, dual Mode for dimension Table is a very simple and efficient optimization and require literally one click.
Both PowerBI and the source Database have a concurrency limits (in Direct Query Mode) and the best optimization is not to generate the SQL Query in the first place, it may be not a big deal for one user, but for a hundred of users, it start to make a substantial difference, and obviously dual Mode assume a star Schema as a Data Model.
Another aspect which I think is not stressed enough in the discussion about DWH Modelling, The BI tools does Matter, Modeling is not done in vacuum, the reporting tables for PowerBI are not necessarily the same for Other BI tools.

2 thoughts on “Optimize PowerBI Direct Query performance by using Star Schema and Dual Mode.”