Flat table modeling in PowerBI can generated some very heated arguments, every time someone suggest that that it may be useful for a particular use case, the reaction is nearly universal, flat table are bad, I think it may be useful in some very specific scenarios.
let’s say you have a nice wide fact table generated by dbt and hosted in a fast Cloud DWH, all dimensions are pre joined, , to be very clear you will not need to join it with another fact, it is a simple analysis of 1 fact table at a very specific grain
I will use Power generation in the Australian market for the last 5 years as an example.
Import Mode
When using Import Mode, PowerBI import the data to the internal Database Vertipaq, it is just a columnar database, with some very specific behavior, because the whole table is loaded into memory, less columns, means less memory requirement, which is faster, and because it does uses index joins between Fact and dimensions when you define relationships, counterintuitively, the cost of doing join is less expensive than loading a whole column in the base table.
In Import Mode, it is a no-brainer, Star Schema is nearly always the right choice.
Direct Query Mode
In Direct Query Mode, the whole way of thinking change, PowerBI is just sending SQL Queries to the source system and get back results, you try to optimize to the source system, and contrary to popular beliefs Star Schema is not always the most performant ( it is rather the exception), see this excellent blog for more details , basically pre join will often give you better performance.
let’s test it with with one fact table ( The Table is 80 millions with a materialized view to aggregate data)

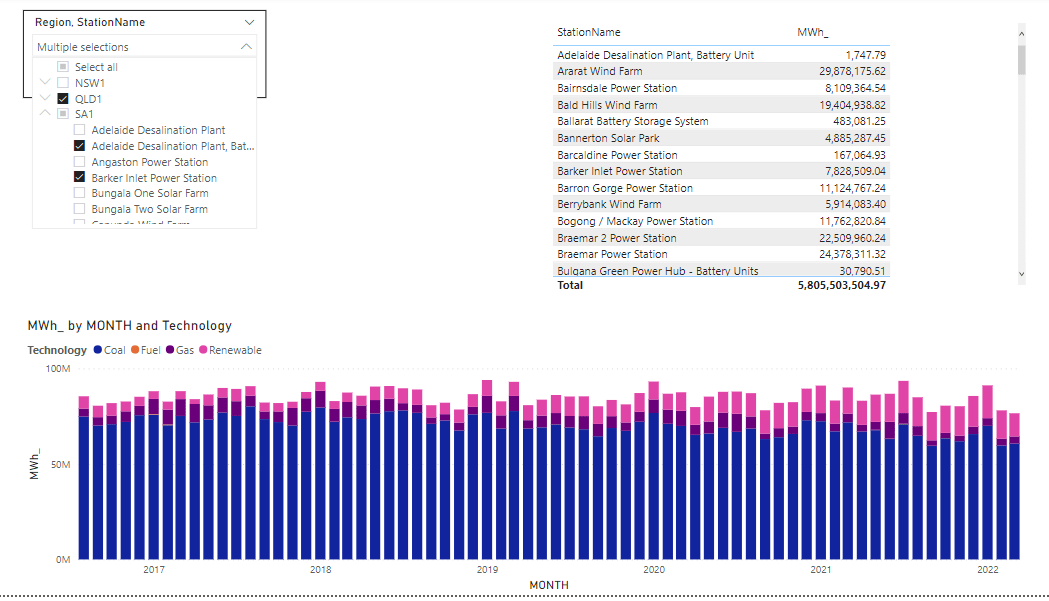
And the glorious Model in PowerBI, yes, just 1 Table

and let’s build some visuals
Now let’s check the Data Source performance
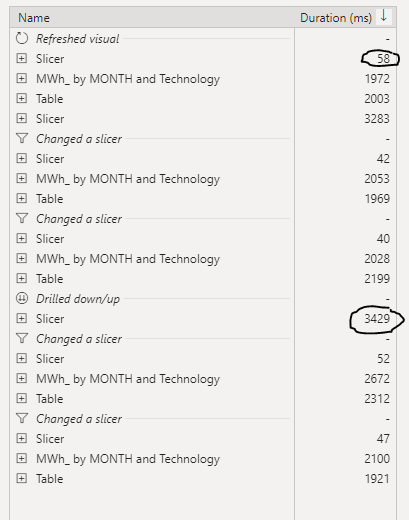
Slow Slicer
The Slicer is rather slow, probably you will say, of course scanning a whole 80 million columns is not very smart, actually that’s not the Problem.
for example when I extend the State NSW, PowerBI will generate two SQL Queries
the first one to get the station Name and took 481 ms
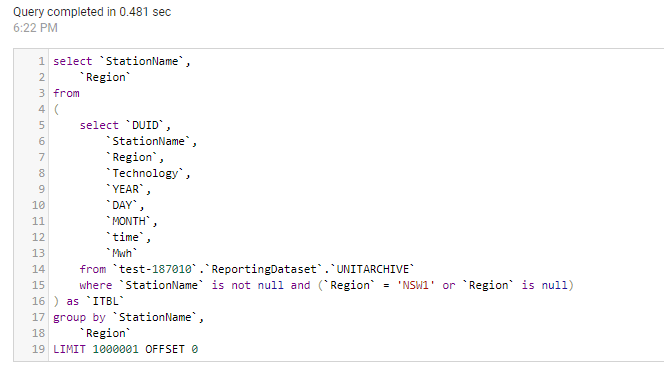
And the second Query to get the regions, 361 ms

PowerBI Formula Language will take some time to stitch the results together ( 1023 ms, that’s seems very slow to me ?)

in this case it is only 5 states, not a big deal, the Query results will be cached eventually after the report users expand all the options.
Is 3 second ? a good enough experience for an end user, I don’t think so, slicers have to be instantaneous, Visual can take up to 5 second, I don’t mind personally , but as a user I have a higher expectation for the slicers responsiveness, I will still use Dual Mode with a star schema
Take Away
If your Database can give you a sub second response time for the slicer selection and you have a very limited and clear analysis to do and you have to do it in Direct Query Mode, then flat wide table is just fine as long as you are happy with the SQL Generated.
