
Edit : February 2023 , Synapse serverless has substantially improved the Query performance for TPCH-SF10, first run which include calculating the statistics take around 2 minutes, but the second run is around 62 second.
In a previous blog, I did a benchmark for a couple of Database Engine, although it was not a rigorous test, pretty much the results were in the expected range, except for Synapse serverless, I got some weird results, and not sure if it is by design or I am doing something very wrong, so I thought it worth showing the steps I took hoping to find what’s exactly going on. The test was done in January 2022.
First Check : Same region
I am using an azure storage in Southeast Asia

My synapse Instance is in the same region

Ok both are in the same region, first best practice.
Loading Data into Azure Data Store
The 8 parquet files are saved in this Google drive, so anyone can download it,
Define Schema
In Synapse, you can directly start querying a file without defining anything, using Openrowset, I thought I can test TPC-H Query 1 as it uses only 1 table, which did not work , some kind of case sensitive issue, when writing this blog I run the same Query and it worked just fine, ( no idea what changed)
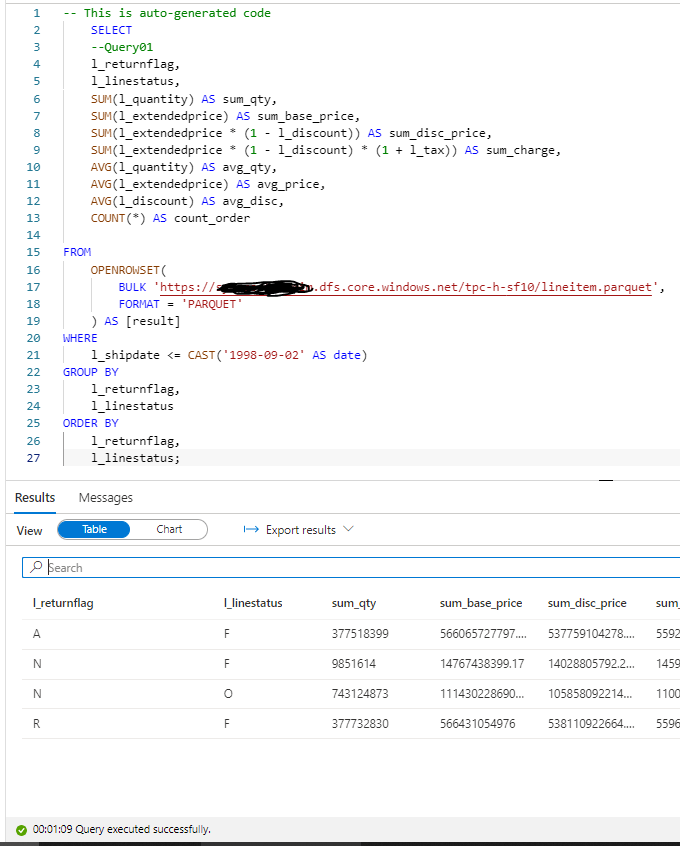
1 minute on a second run, hmm not good, let’s try a proper external table , the data_source and File_format were already defined, so need to recreate it again.
CREATE EXTERNAL TABLE lineitem_temp ( [L_ORDERKEY] bigint, [L_PARTKEY] bigint, [L_SUPPKEY] bigint, [L_LINENUMBER] bigint, [L_QUANTITY] float, [L_EXTENDEDPRICE] float, [L_DISCOUNT] float, [L_TAX] float, [L_RETURNFLAG] nvarchar(1), [L_LINESTATUS] nvarchar(1), [L_SHIPINSTRUCT] nvarchar(25), [L_SHIPMODE] nvarchar(10), [L_COMMENT] nvarchar(44), [l_shipdate] datetime2(7), [l_commitdate] datetime2(7), [l_receiptdate] datetime2(7) ) WITH ( LOCATION = 'lineitem.parquet', DATA_SOURCE = [xxx_core_windows_net], FILE_FORMAT = [SynapseParquetFormat] ) GO SELECT count (*) FROM dbo.lineitem_temp GO
A Proper Table with Data type and all

let’s try again the same Query 1

ok 2 minute for the first run, let’s try another run which will use statistics, it should be faster, 56 second ( btw, you pay for those statistics too)

Not happy with the results I asked Andy ( Our Synapse expert) and he was kind enough to download and test it, he suggested splitting the file give better performance , he got 16 second.
CETAS to the rescue
Create External Table as Select is a very powerful functionality in Serverless, The code is straightforward
CREATE EXTERNAL TABLE lineitem WITH ( LOCATION = '/lineitem', DATA_SOURCE = [xxxx_core_windows_net], FILE_FORMAT = [SynapseParquetFormat] ) as SELECT * FROM dbo.lineitem_temp
Synapse will create a new table Lineitem with the same data type and a folder that contain multiple parquet files.

That’s all what you can do, you can’t partition the table, you can’t sort the table, but what’s really annoying you can’t delete the table, you have first to delete the table from the database then delete the folder
but at least it is well documented

Anyway, let’s see the result now

Not bad at all, 10 second and only 587 MB scanned compared to 50 second and 1.2 GB.
Now that I know that CETAS has better performance, I have done the same for remaning 7 tables.
Define all the tables
First Create an external Table to define the type then a CETAS, Synapse has done a great job guessing the type, I know it is parquet after all, but varchart is annoying by default it is 4000, you have to manually adjust the correct length.
TPC-H document contains the exact schema
Running the Test
The 22 Queries are saved here, I had to do some change to the SQL, changing limit to Top and extract year from x to Year (x), Query 15 did not run, I asked the Question on Stackoverflow and Wbob kindly answer it very quickly
The first run, I find some unexpected results
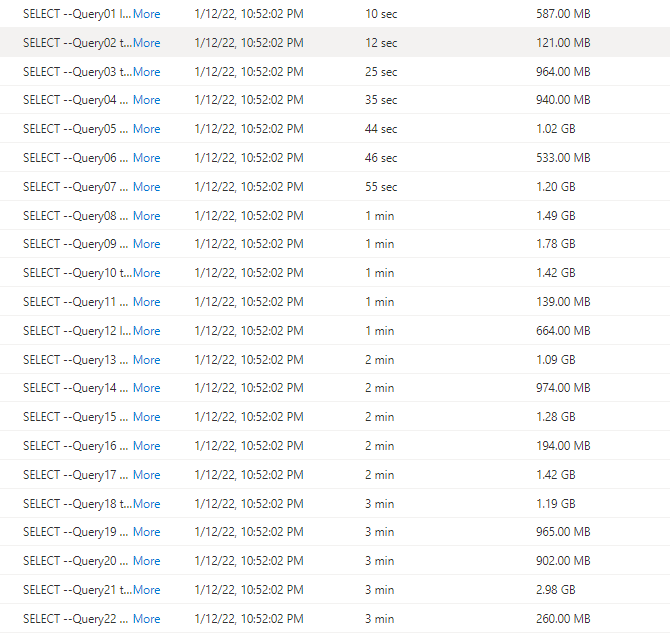
I thought I was doing something terribly wrong, the Query duration seems to increase substantially, after that I start messing around, what I found is, if you run just one Query at the time, or even 4, the results are fine, more than that, and the performance deteriorate quickly.
A Microsoft employee was very helpful and provided this script to Query the Database History
I imported the Query History to PowerBI and here is the results

There is no clear indication in the documentation that there is a very strict concurrency limitation, I tried to run the Script in SSMS and it is the same behavior, that seems to me the Engine is adding the Queries to a queue, there is a bottleneck somewhere.
Synapse serverless show the duration between when the Job was submitted until it is completed, there is no way to know the actual Duration of each Query, so basically the Overall Duration is the duration of the Last Query, in our Case Q22, which is around 3 Minutes.
Takeway
The Good news, the product team made it very clear, Synapse Serverless is not an Interactive Query Engine

Realistically speaking, reading from Azure storage will always be slower compared to a local SSD Storage, so no I am not comparing it to other DWH offering, having said that even for exploring files on azure storage, the performance is very problematic.

One thought on “Benchmarking Synapse Serverless using TPC-H-SF10”