Edit 26 May 22 Please vote to have table function available in Datamart
With PowerBI February 2022 release , finally we can use M Dynamic parameter with SQL Server in Direct Query Mode, I was really excited, I had a couple of patterns where I used M Parameter with BigQuery to do calculation on the fly that iare not supported natively in PowerBI, for example Geospatial calculation.
My first example was dynamic changing of dimension, it just works as it is relatively simple, see example here, very excited it works.
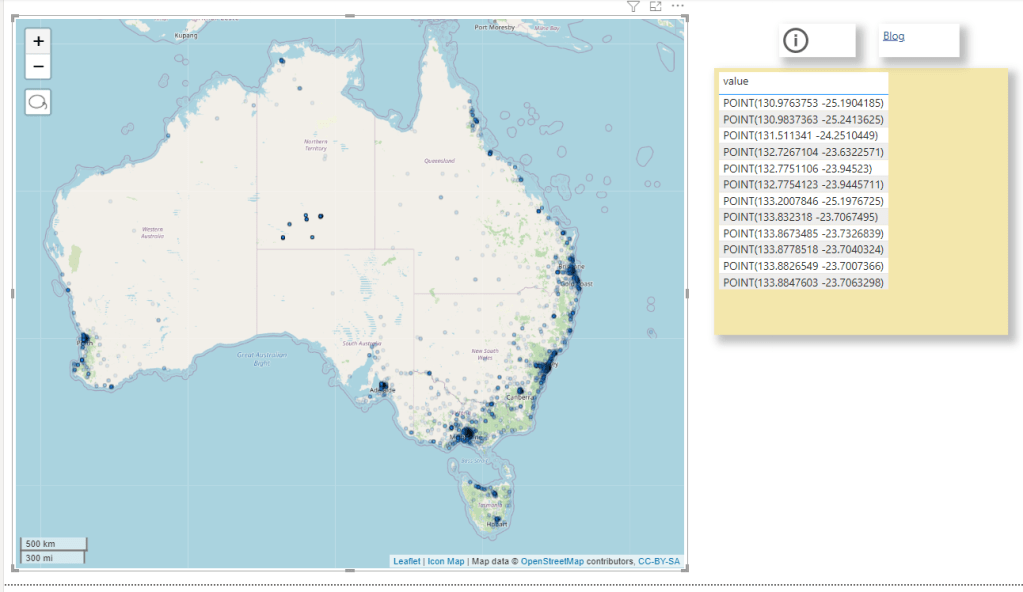
Then I tried to port this example from BigQuery, basically you select some points in a map, and you get back the polygon and the area, The calculation has to be done on the fly, pre calculating the results is not practical, generating all possible calculation is just too much.
The first step of getting the points selected as a nice list was very easy, see code here
let
TagsList = if Type.Is(Value.Type(tag_selection), List.Type) then
Text.Combine({"'" , Text.Combine(tag_selection, ",") , "'"})
else
Text.Combine({"'" , tag_selection , "'"}),
finalQuery= "select 1 as poly, value from string_split("& TagsList&",',') ",
Source = Sql.Database("XXXXXXXX", "DB", [Query=finalQuery])
in
Source
I selected some points in Icon Map and dynamic M parameter get populated, I was really excited, The hard part is done and all I need is to write some T-SQL
T-SQL Rabbit hole
I am no SQL expert by any means, by some weird coincidence, my first Database was BigQuery, (I used MS Access long time ago ), so this is the first time I tried to use T-SQL in a non trivial way ( at work I use T-SQL to retrieve data, maybe doing some joins and stuff in that nature but no GIS for sure).
The Good thing is , the amount of resources available on SQL Server is phenomenal, I got some indication on Stack overflow, but something weird happen.
I start writing T-SQL code in SSMS and it works fine, when I copy it to PowerBI, it generate errors, I was really angry and can’t understand what’s going on, I thought it is something weird about PowerBI.
I know that PowerBI, embed any custom SQL inside a Subquery, that’s very standard, actually Tableau does the same as well as Google Data Studio.
Turn out, SQL Server don’t support CTE inside a subquery
Chris has blogged about it here, that was very kind of him, basically his points is just write a view in a database, it is better to have the logic upstream anyway, which totally make sense, except it is not a realistic solution, Business users don’t just get write access to the database, actually they are very lucky to get even read access.
Update : we now have Datamart which will change everything.