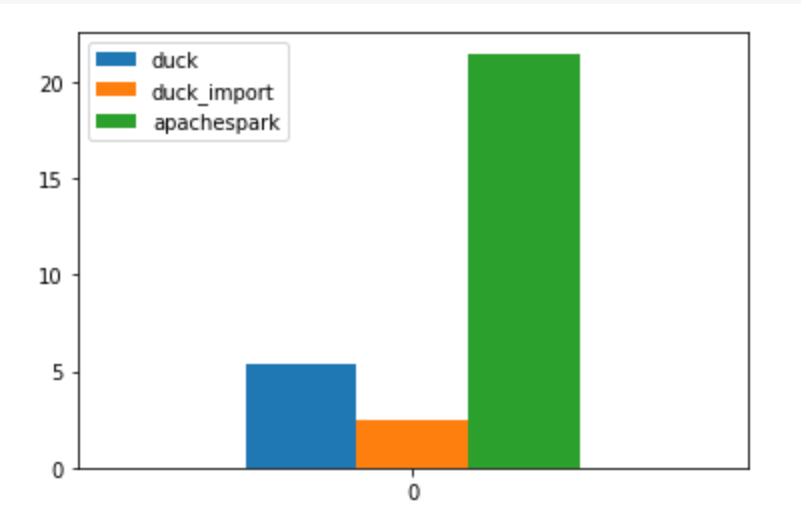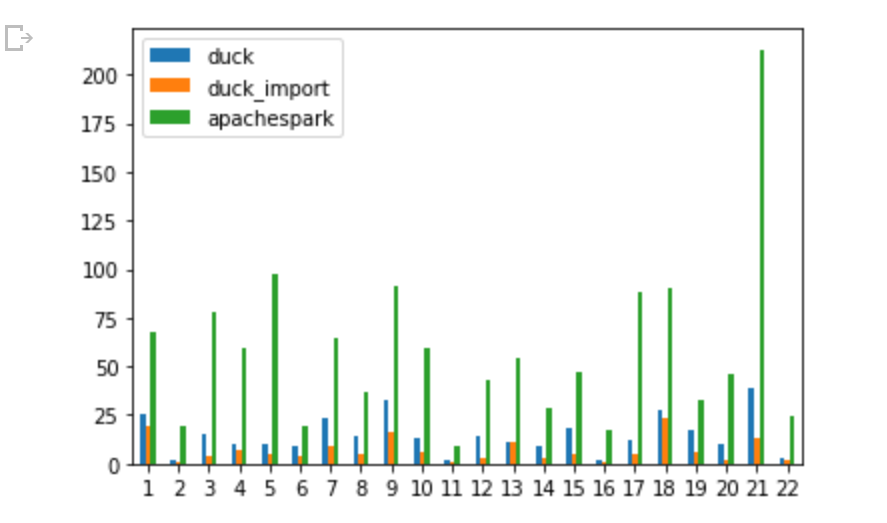
TL;DR ; Although the optimal file size and the row group size spec is not published by Microsoft, PowerBI Direct Lake mode works just fine with Delta table generated by non-Microsoft tools and that’s the whole point of a Lakehouse.
Edit : added example on how to write directly to Onelake
Quick How to
You can download the Python script here, it is using the open source Delta lake writer written in Rust with a Python Binding.(does not require Spark)
Currently Writing Directly to OneLake using the Python writer is not supported, there is an open bug , you can upvote it, if it is something useful to you
The interesting part of the code is this line

You can append or overwrite a Delta table, delete a specific partition is supported too, merge and delete rows is planned
The Magic of OneLake Shortcut
The idea is very simple, run a python script which create a delta table in Azure storage then make it visible to Fabric using a shortcut, which is like an external table, no data is copied
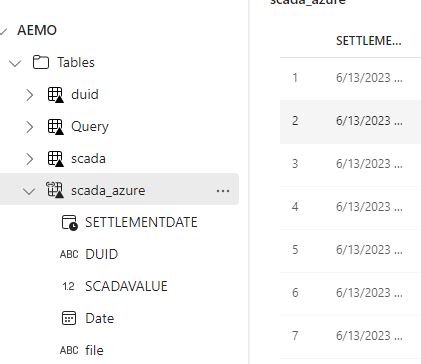
The whole experience was really joyful 🙂 lakehouse discovered the table and showed a preview

Just nitpicking, it would be really nice if the tables from the shortcut have different colors, the icon is not very obvious.
If you prefer SQL, then it is just there
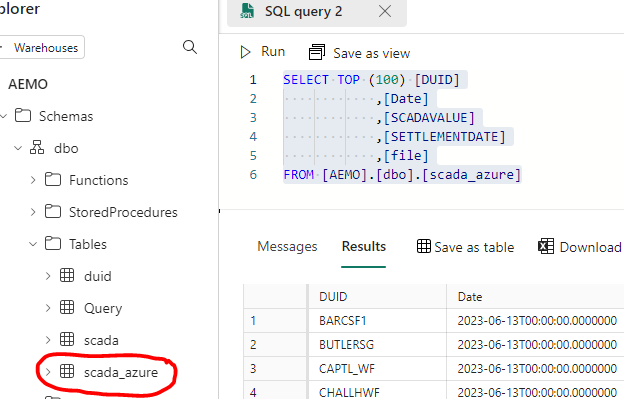
Once it is in the lake, it is visible to PowerBI automatically. I just had to add a relationship , I did not use the default dataset as for some reason, it did not refresh correctly, it is a missed opportunity as this is a case where default dataset just makes perfect sense.

But Why ?
Probably you are asking why,in Fabric we have already Spark and dataflow Gen2 for this kind of scenarios ? which I did already 🙂 you can download the PowerQuery and PySpark Script here
So what’s the best tool ? I think how much compute every solution will consume from your capacity will be a good factor to decide which solution is more appropriate, today we can’t see the usage for Data Flow Gen2 so we can’t tell.
Actually , I was just messing around, what people will use is the simplest solution with less friction, a good candidate is Dataflow Gen2, and that’s the whole point of Fabric, you pay for convenience, still I would love to have a fully managed single node python experience.