TL;DR : a notebook to compare TPCH-SF10 results for Spark and DuckDB on a single Node.
Apache Spark is a system design for Big Data workload using distributed computing, it scale out very well just by adding more compute nodes, in real life though, it is used a lot with smaller data, people use whatever they have access to.
I don’t have a lot of experience with Pyspark, but I know enough to run some SQL Queries, and what a better way to test that than TPCH benchmark, in this case, I used a scale factor of 10 with the main table lineitem has 60 million records.
The test is run in Google Colab using the free compute ( 2 vCPU), I did try it with a paid VM ( 8 CPU) but strangely, Pyspark had a memory error ( although it did work fine with low memory, go figure)
I tried too to install in my laptop, but it did complain about some java compatibility, I have no time for this kind of shenanigans , I use to love it when I was much younger but now, I want just stuff to work.
The Data is first download to the local Disk, so all Queries are pretty much CPU bound, I used DuckDB as a reference as it has an excellent Single Node performance.
The Beauty of SQL
Pyspark has an excellent support for SQL, actually the same SQL is run both for Spark and DuckDB, we are talking 22 Queries with nearly 900 line of code, that impressive that it just works without modification for both Engine.
The Results
I used a Python Function to run every Query, and show duration and results

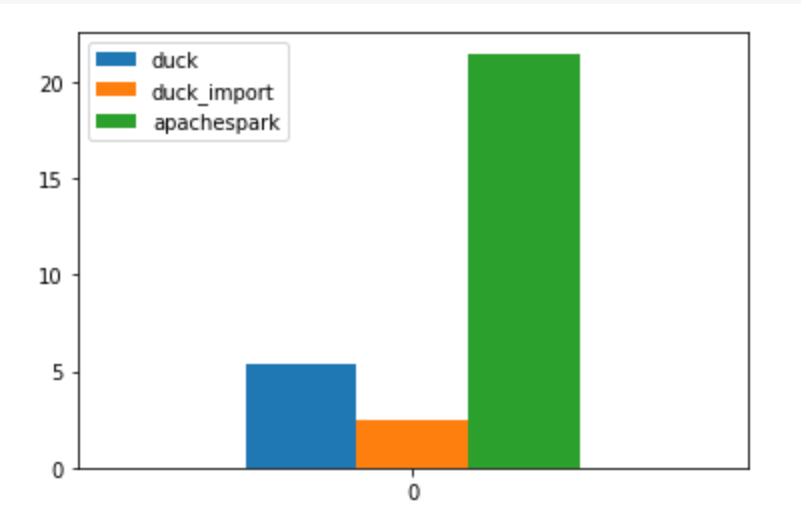
And here is the results, Using PySpark, DuckDB running Queries Directly from Parquet and just for reference DuckDB running from a DuckDB file
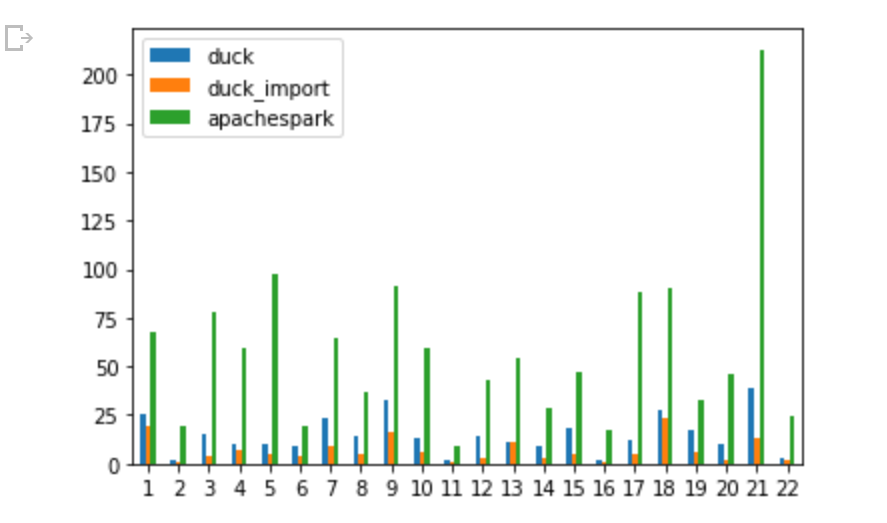
DuckDB around 5 minutes
Spark around 21 minutes
DuckDB using Duckdb file format : 2 minutes ( it take 3 minutes to import)
Take away
For Smaller Dataset that don’t fit in Memory which is a problem for Pandas, it is useful to look around for alternative before jumping to a distributed system, you don’t want to be paying for expensive computer overhead, tools like DuckDB and Polars can do wonder these days, there is a lot to like about Spark, but performance in a single node is not one of them.
Having said that, those new Engines have a lot of work to reach feature parity with Spark when doing Data Engineering jobs, for example support for Table Format like Iceberg and Delta is still experimental.
