Maybe not known enough, but you can run a python script inside PowerQuery in the desktop, and deploy it to PowerBI service using a personal gateway.
it is just a POC that showcase you can do a lot; just using a decent laptop and python.
let’s say, you have a folder with 100 GB of parquet files, and you want to aggregate some results for further analysis in PowerBI, Obviously importing 100 GB maybe not be a great idea, in this scenario, from what I can see, people recommend stuff Like PySpark or Dask , which I guess are great option, but if you want a lightweight option with a simple pip install then DuckDB is amazing !!
For testing, first write your SQL Query using only 1 parquet file, when you are happy with the results, change the path from “folder/x.parquet” to “folder/*.parquet”
In this example I have a folder of 100 GB of Parquet files.

in PowerQuery you need just to insert a python script, you don’t need to know anything about python, it is just a standard SQL Query, PowerQuery is smart enough to know that df is a dataframe, and it will show the result in the next step.

import duckdb
con = duckdb.connect()
df =con.execute('''
select L_RETURNFLAG,L_LINESTATUS,count(*) from
'C:/xxxxx/parquet/lineitem/*.parquet'
group by 1,2
''').df()
And here is the final results.
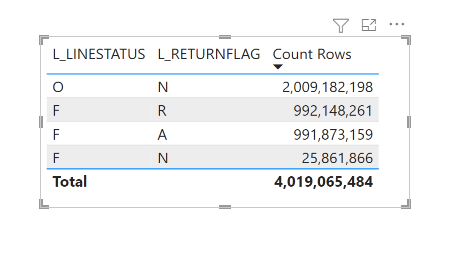
The duration will depend mainly on your CPU and SSD speed, DuckDB consume little memory, in that example less than 2 GB, the secret sauce is parallel scan of Parquet files.
Traditionally Big Data means; Data that don’t fit into RAM, nowadays, Big Data is how much Data can fit in your SSD, and that’s a welcome change.

So what was the running time of this on your system?
LikeLike
around 4 minutes
LikeLike