Using PowerBI Dataflow to share data between departments is increasingly getting more popular, with the rise of managed self service offering, it is not unusual to find a non centralised Data warehouse but rather every department managing it is own data, I don’t know enough to say anything useful on which model works better in the long term.
this blog is about one use case I encountered recently, and thought it maybe worth sharing and to be very clear it is always good practise to share the data from the upstream Data source , but in this case, there was a non trivial business logic applied inside PowerBI dataset.
Usually we have two options.
- A user can just create a new thin report assuming he has build permission
- With Direct Query on composite model, a user can mix between live connection to a dataset and import different sources.
Both approach are fine, but in this case, the data consumer from another departement is just interested in 1 table (a couple of dimension and some measures) and because there is a non trivial logic in the Model, we can’t get the data from the source system, and it is rather important not to provide Build permission.
In my humble opinion sometimes giving access to a whole Data model with a lot of tables, relationship etc does seems an overkill and potentially confusing , instead I am suggesting an easier approach, sharing a dataflow that run a DAX Query against the model, and return exactly the agreed schema,basically a flat table which will not change even if the structure of Model change.
it is very straightforward and works with both Pro and premium ( Premium works better with large models, the timeout duration is more generous, and anyway PPU is very cheap)
Build a visual that show the required data
I will use a random dataset as an example, let’s say the data consumer wants this data updated daily ( real life example is substantially more complex)
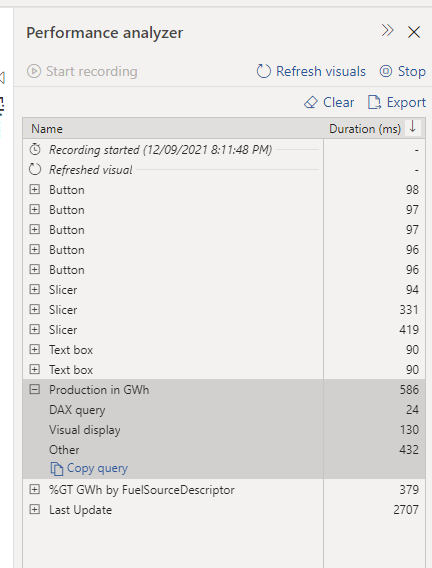
click on performance analyzer , refresh visual then copy the Query
Clean the Query in DAX Studio
Paste the Query in DAX studio, don’t get intimidated by the apparent complexity , The main Query start by VAR __DS0Core

Now in a simplified format
// DAX Query
EVALUATE
SUMMARIZECOLUMNS(
'MstDate'[SETTLEMENTDATE],
'REGION'[REGION],
TREATAS({"QLD"}, 'REGION'[REGION]),
TREATAS({"5 Minutes"}, 'unit'[description]),
"average_Price", '00-Measures'[average_Price],
"INITIALMW_Sum", '00-Measures'[INITIALMW_Sum]
)
Alternatively you can build The Query straight in DAX Studio using the Query Builder

Connect to PowerBI service endpoint using PowerBI Desktop
you can read the documentation here, basically you connect to SQL Server Analysis Services which is the Engine of PowerBI,
Note : I am using my personal tenant.

Copy PowerQuery code to Dataflow
Dataflow don’t have a connector to Analysis Services at least in the UI, but coping the Query just works ( notice the double Quotes in QLD)
let
Query1 = AnalysisServices.Database("powerbi://api.powerbi.com/v1.0/myorg/aemo_data", "aemo_data",
[Query=
"
// DAX Query
EVALUATE
SUMMARIZECOLUMNS(
'MstDate'[SETTLEMENTDATE],
'REGION'[REGION],
TREATAS({""QLD""}, 'REGION'[REGION]),
TREATAS({""5 Minutes""}, 'unit'[description]),
""average_Price"", '00-Measures'[average_Price],
""INITIALMW_Sum"", '00-Measures'[INITIALMW_Sum]
)
"
,Implementation="2.0"])
in
Query1
I am not suggesting it is a good practise, in an ideal world everything is in a nice Cloud DWH with business logic and all, and the BI tool is just a front end to run aggregation and show nice charts, but real life is not perfect and it is useful to have the option when you need it.
Edit : The original title of this blog was using Dataflow as Poor Man’s Data mesh, but I had to be realistic as of this writing Dataflow can only be consumed by a PowerBI Client, not even Excel is supported and I know about Azure Storage, but with the current paranoia about security, it is extremely hard to have that option on for a lot of companies , Hopefully Dataflow product team open up a little bit for other Client too.