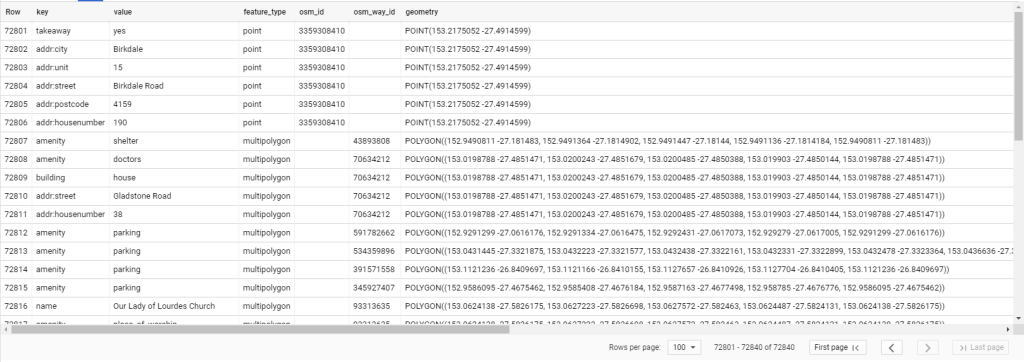
whenever I need to join Primavera Activity id to the quantity measurement system, I use this pattern, it did serve me well all those years, recently I started a new project where for the first time, I don’t get an extract using Excel but a proper live connection to SQL server 🙂
To get something quickly running, I started using the same approach, load Primavera export, unpivot the date and normalize it, every activity has a spread from 0 to 100 % then merge it to a Table from SQL server, all working as expected.
Although it works well, it is a bit clunky , specially that the export from Primavera does not change frequently, for the baseline maybe once a year and the forecast once a month, so instead of merging the data using Powerquery, I loaded the Primavera data as a separate table, here what the model looks like
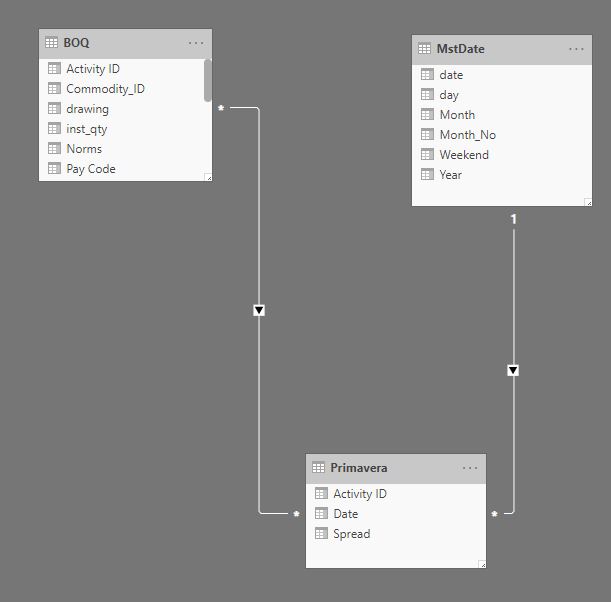
As you have guessed the Activity id is duplicated in both tables

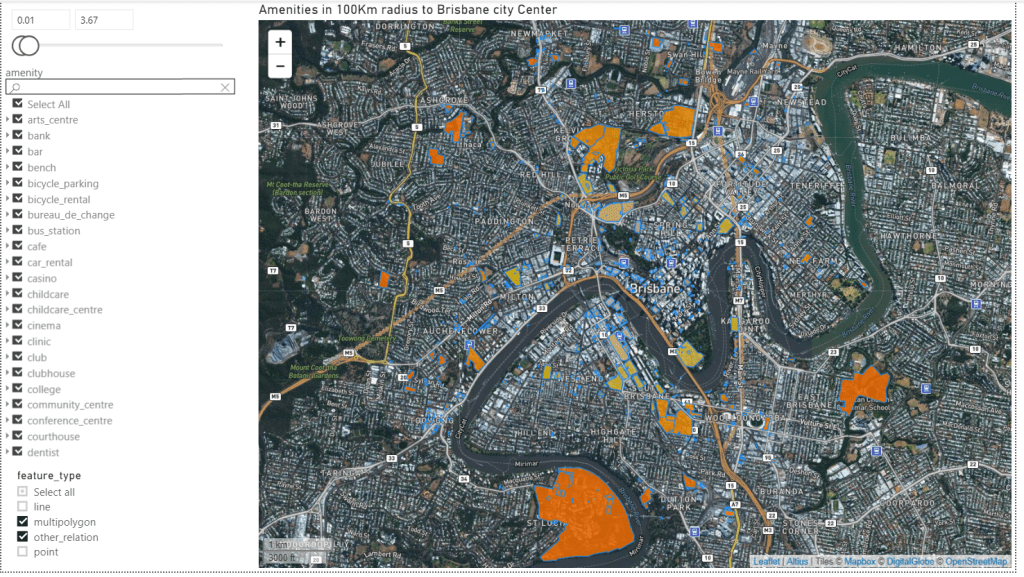
Now the Metric I am looking for is how to spread the budget hours from the table BOQ using the spread ( 0-100 %) from Primavera, let’s say I filter 1 row from the BOQ the result should be something like this

As it is multiple to multiple if you simply multiply the hours X spread you get duplicate values
Planned_Hours_no_filter = sumx(Primavera, [remaining_hrs]*Primavera[Spread]) = 950K hours
Obviously, it is the wrong, the total remaining hours is 49K only, the maximum spread should be 49K (or less if some activities ID are not mapped.)
The solution is to create an explicit filter and get the hours only for the specific activiy ID
Planned_Hours = sumx(Primavera, CALCULATE([remaining_hrs],filter(BOQ,BOQ[Activity ID]=Primavera[Activity ID]))*Primavera[Spread])
And here is the result

I checked with the old model and all the results match, to be honest I am not a huge fan of multiple to multiple but in this case, it is worth it, less refresh time and got rid of two big tables.
you can download the pbix here