Looker was always a bit of mystery for me, as there was no trial version to test, and they have high profile customers, luckily Google recently start providing trial version without asking too much Questions, I registered 2 months ago, and recently got an email with a trial offer.
it is just an impression, I just used it a couple of times in the weekend with no training
You get an URL instance with the name of your company, I used a dummy name.
The user interface is rather streamlined, nothing unusual which a good thing , as expected it is hosted in Google Cloud, but you can’t see anything from the console ( Looker is available in AWS, Azure and GCP)
Looker by default has two modes, development and production, everything you build is linked to Git repository

let’s say you want to build a new Dashboard , first thing to do is to create a new LookML Project, setting up GitHub was straightforward, I made the repo public
Probably you are asking where is the data preparation the Likes of PowerQuery or Tableau Dataprep, there is none, Looker connect only to Databases, it assume you have already a Data Warehouse, Looker Provide Just the Semantic Model using LookML code and the Viz, and the API which you can call from any Clients.
There is no Import mode, all connections are live, there is a cache though that save the result caches which you can adjust by Project or you can turn it off by using cache = 0 second.
There are aggregation Table , which you can use to speed up Queries but again you need to store them in the source database.
Looker use an internal Database ( I think MySQL), but is only to store internal Metadata ( users names, SQL Queries etc), all calculation depends on the source system
To my surprise at least for simple Semantic Models, LookML is not too hard, I connected to a dataset in BigQuery and Looker imported the Table Schema, all I had to do is to define relationship between Tables, and add Measures using SQL
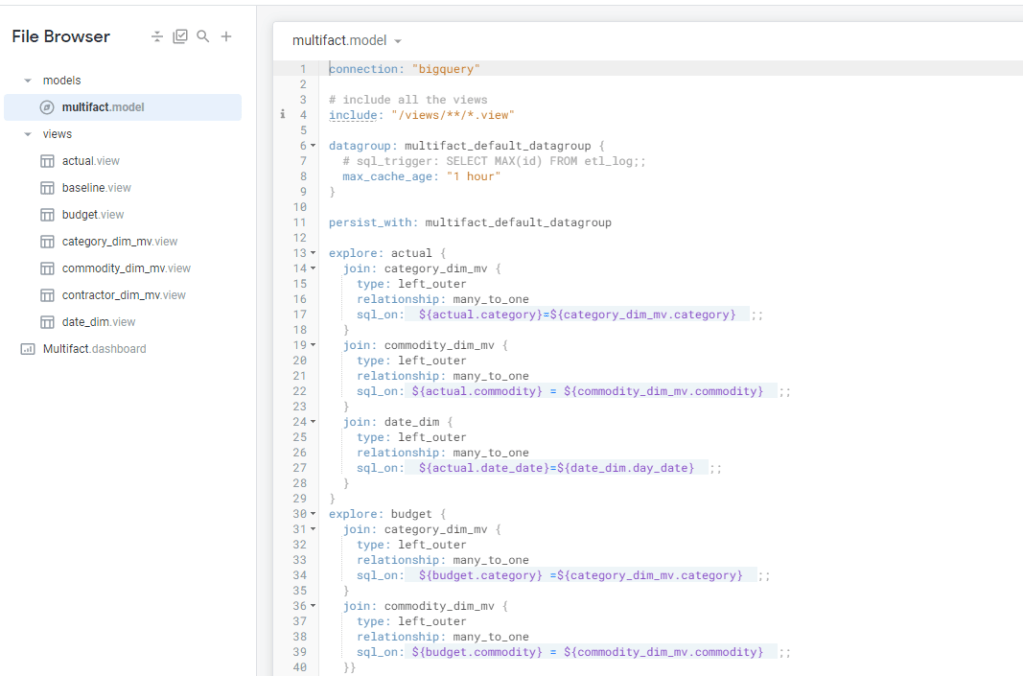
funnily enough the most confusing Part; Looker does not use standard technical Terms:
Views means Table
Explore is a semantic Model
Model is a group of Explores and Views
Look is a chart
at any time you can View the Diagram View
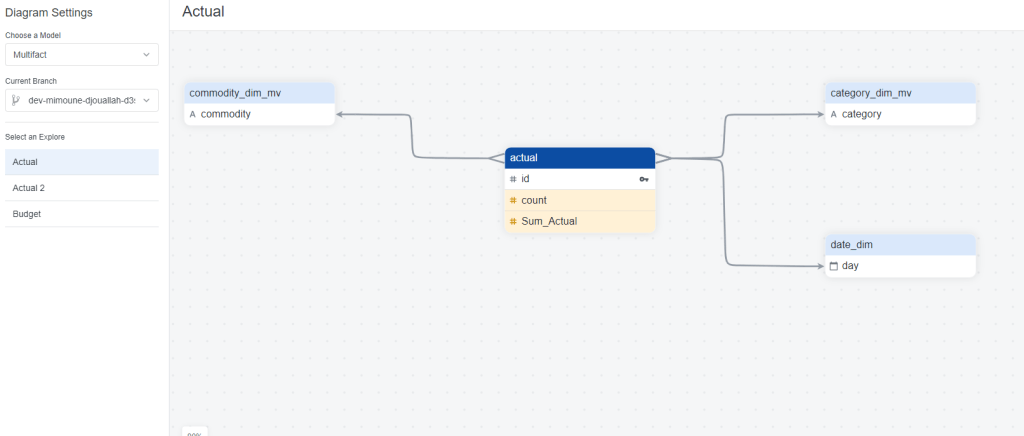
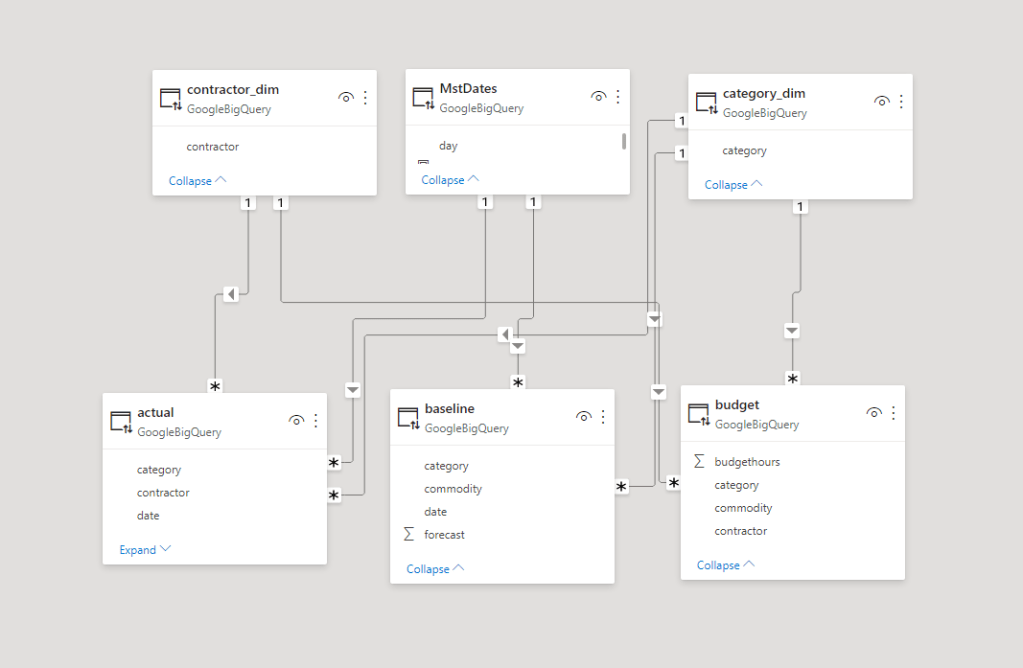
One interesting aspect of Looker Modeling compared to PowerBI, you can have Multiple Models that join the same tables in different ways !!! but at the same time, I could not reproduce a typical Multi Fact Tables easily (Example from PowerBI, I am not saying it is not possible, but I did not know how to do it)
Once the Model is completed you can start exploration using “Explore”, I guess this is the core Concept of Looker , every time you add a metric and dimension, Looker automatically generate the Correct SQL, and because the Model are defined Enterprise wide , the metric definitions and dimensions are consistent regardless of the users.
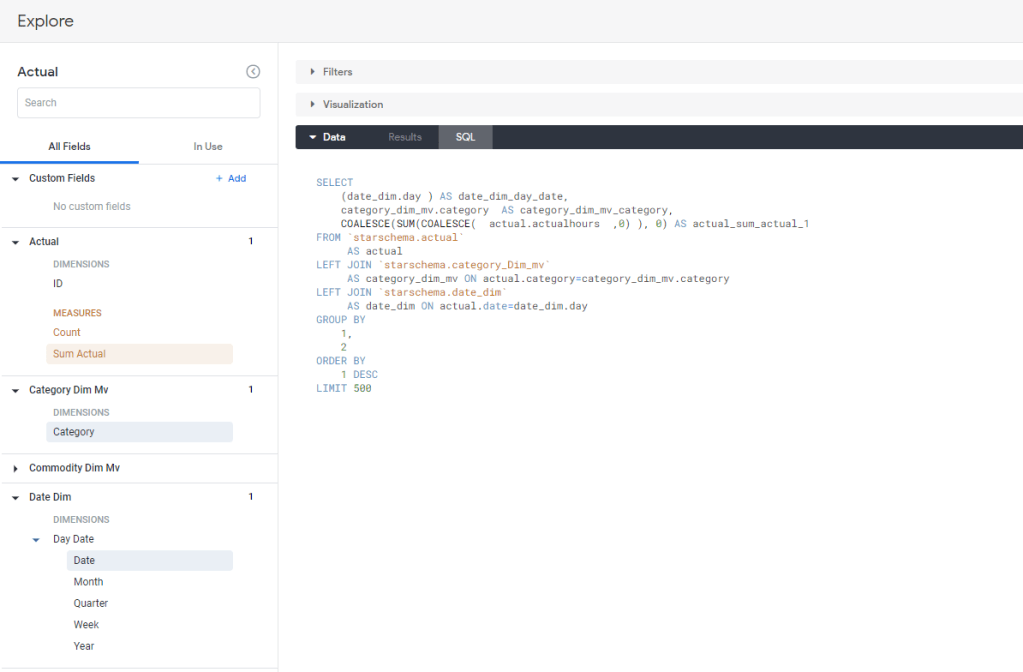
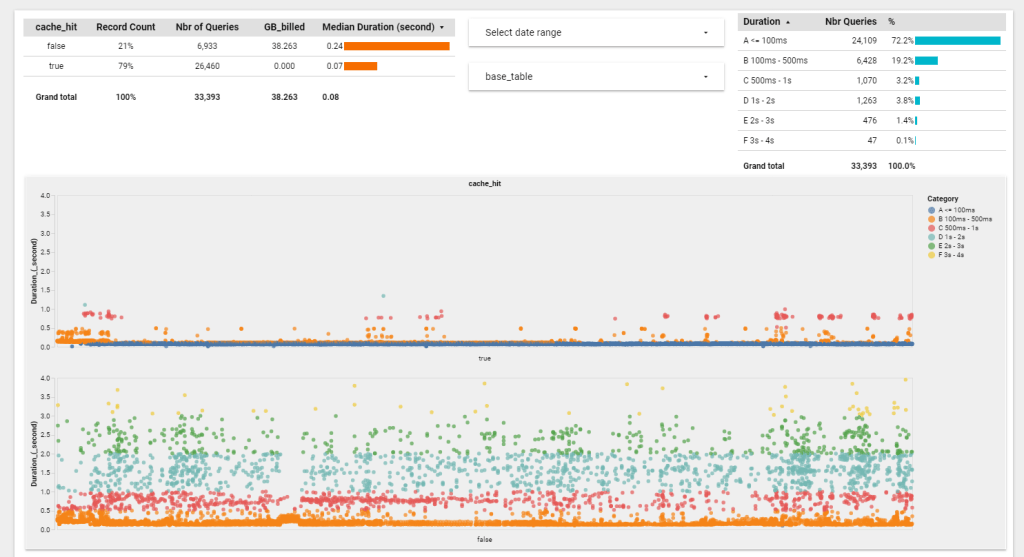
Notice here, the first thing you get is the data in a tabular Form, then you define the Visual, there is a saying that PowerBI is 80 % Data and 20 % Viz, I would say Looker is 99 % Data and 1 % Viz :), OK I am a bit exaggerating but don’t expect a Tableau Level Customization
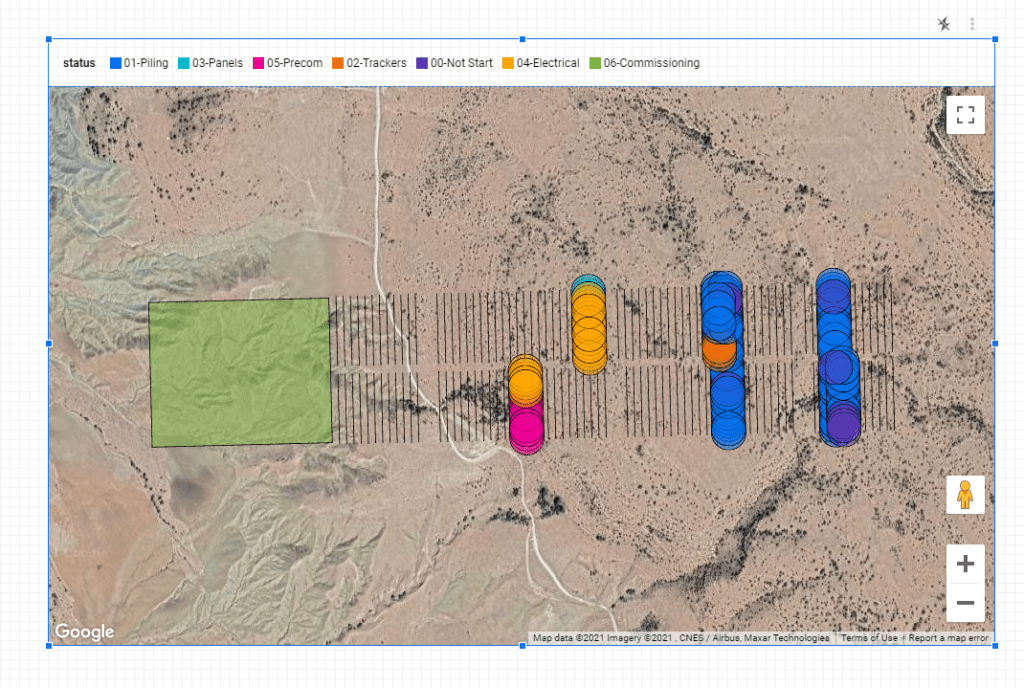
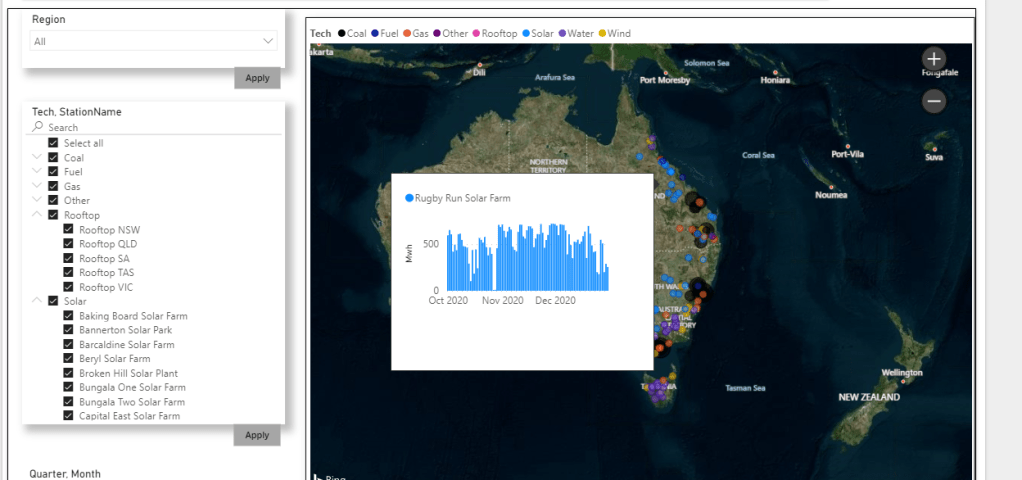
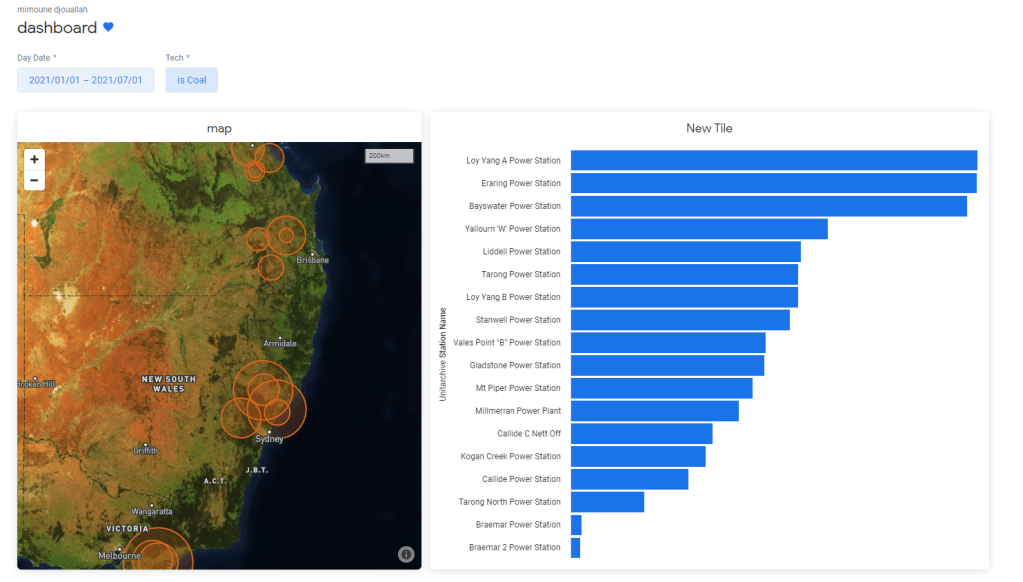
When you are happy with your explore you can save it as a Look which is basically an individual Chart which you can pin to a Dashboard like this one
Another very nice functionality is Roles, in PowerBI you can customize what a user can do , build new content, sharing etc, But in Looker it is very granular, you can customize any option , you can even authorize who can and can’t download data !!
Sharing is very trivial, you can share with external users with different email address, even users with gmail and hotmail.
Tracking performance is simple, you can see the history of all SQL Queries and identify any issues
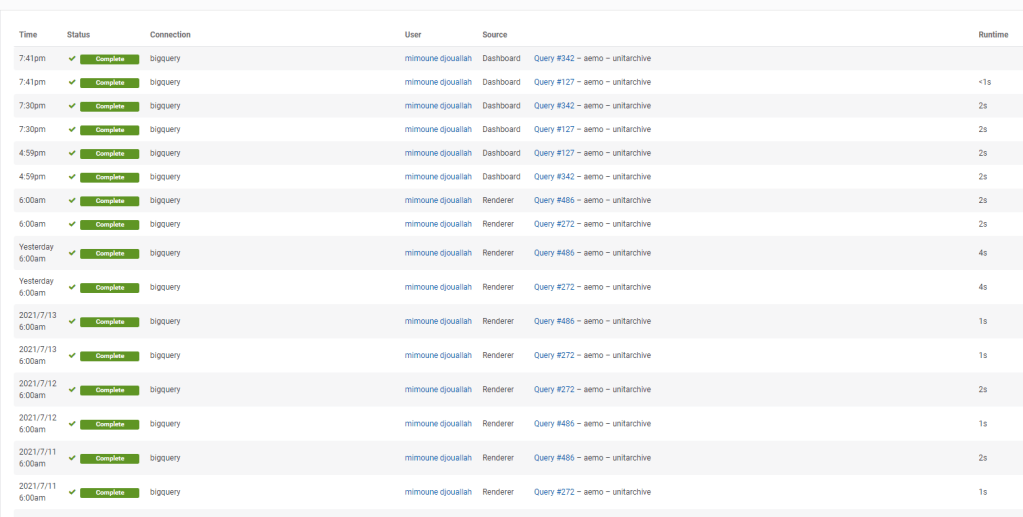
and a nice overall Performance of your Instance
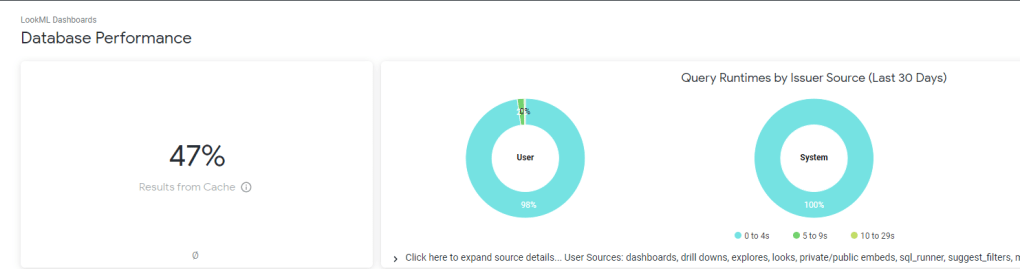
Regarding Performance, I think Looker will perform Better compared to PowerBI in Direct Query mode , simply because there is less moving parts, in PowerBI, the viz generate a DAX Query against the Model which call the engine which call PowerQuery that convert to SQL, Looker Just Generate SQL Queries based on the Data Model that’s all
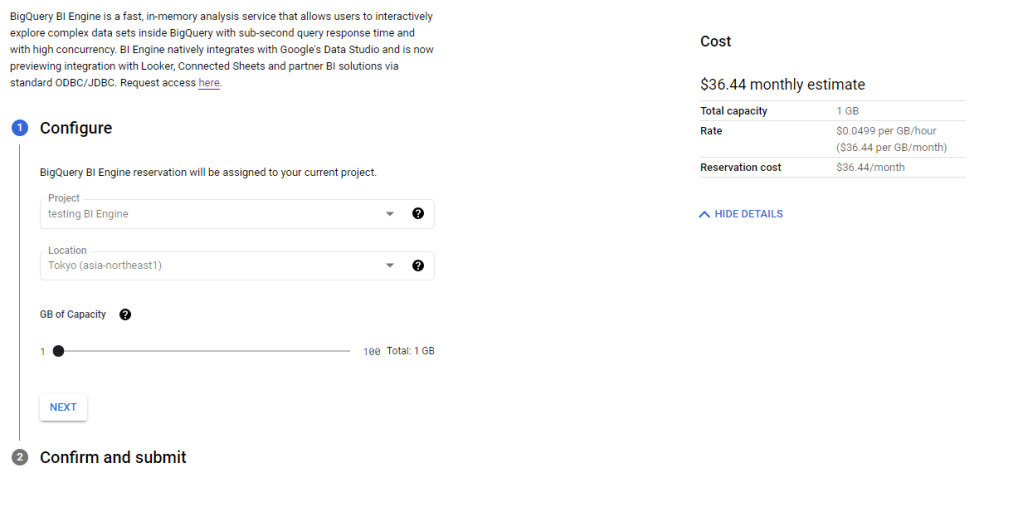
You can’t really Talk about Looker without talking pricing, here is a screenshot from Google Cloud Pricing
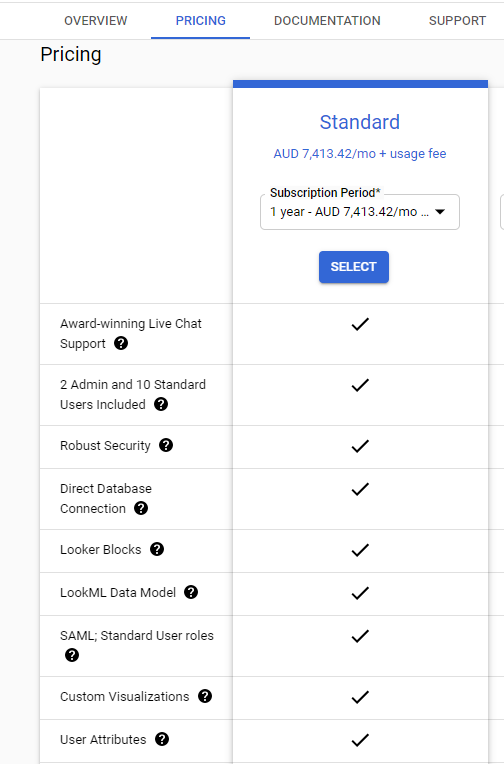
yes, there is no typo, 5000 $/Month get you 12 users and you need to pay 30 $/Month for any extra user !!!
apparently Looker is very popular with High scale embedded scenarios but it require some JavaScript skills which is out of my scope.
Take Away
as Far as I can see the target Market of Looker is Large Enterprises with Mature Data infrastructure and deep pockets, I can see the attraction of code based solutions with version control and centralized Semantic Models, no wonder BI professional with Software engineering background love it.
Apparently in the short term a lot of Data is moving to the cloud and Cloud Data warehouse are getting really Fast and cheap ( See BigQuery BI Engine), the concept of Live connection using a centralized Semantic Model is very attractive and according to some industry commentators it is the next big thing in Business intelligence.
Personally I am not sold, I think every Business users should be able to build his own analysis without waiting on a central BI team( not all reports are equals, some are strategic which require governance other less ), on the bright side LookML is not as hard as I thought at least for simple Models, but with the current Pricing, it is fair to say it is not a threat to PowerBI at least for smaller Installation
edit : got a feedback that a self service user can add custom measures and dimension that did not exist in the original Model , see documentation , but still if you want to use new data, it has to be imported first in the Source Database.
edit : Google shut down my trial instance after three weeks, unfortunately I can’t write any more about Looker, if someone from google is reading this , you’re not helping yourself.