
Google made BigQuery BI engine available in a public preview , you need to enroll first here, for the last two years it was available only for Google Data Studio, and I had use it extensively for this Project, so I was really curious how it will work with PowerBI.
I don’t think I know enough to even try to reproduce a benchmark, Instead I am interested in only one Question, how much value I can get using the lowest tier of BI Engine and can PowerBI works smooth enough t make Direct Query a realistic option.
BigQuery team was nice enough for the preview period to have 100 GB reservation free of charge, just to keep it realistic, I kept reservation to 1 GB with a cost of $30 per month, I built a couple of reports in PowerBI and tried to observe how BI engine behave and observe the Query statistic , The report is located here, The Data is using Direct Query Mode, the Query statistics update every 1 hour.
How BI Engine Works
it is extremely easy to setup just select how much memory you want to reserve by Project, and that’s all, you pay by GB reserved per hour.
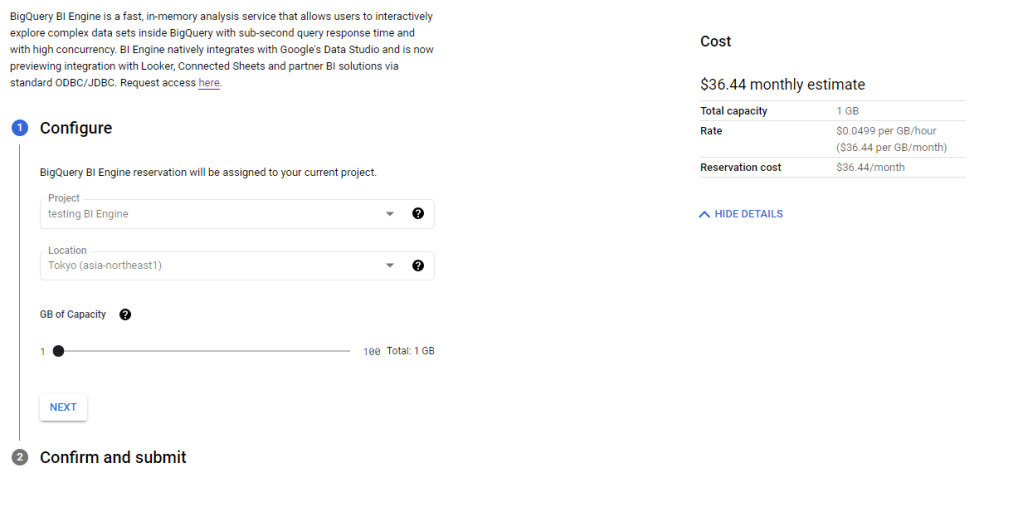
Keep in mind the Project used for reservation can Query any other projects as long as it is in the same region, in PowerBI, you can define which project you use for the Query

After you wait a couple of minutes for BI engine to start, this is more or less how it works
1-Query received by BigQuery, based on columns used in the Query, BI engine will load only those columns and partition into the Memory, the First Query will be always slower as it has to scan the data from BigQuery Storage and compress it in memory in my case usually between 1-2 second
2-Second Query arrive, the data is already in Memory, very Fast 100 ms to 500 ms
3- Same Query arrive as 2, BigQuery will just hit the cache, that’s the sweet spot, less than 100 ms
4- A new Query arrive that target different table, that’s the interesting part, BI Engine based on the size of the scanned column, and the available reservation, either evict the old table from memory or decide that there is not enough Reservation then it will fall back to the default BI Engine, where you pay how much data is scanned
5- A Query arrive that contains feature not supported by BI Engine , it will fall back to the default engine
6- Data appended to the Base table or Table changed, BI Engine will invalidate the cache , it will load the delta to memory or load everything again if the table was truncated
Obviously it is much more complex behind the scene, But I find it fascinating that BI engine in a fraction of a second decide what’s the best way to serve the Query ( cache, Memory or Storage)
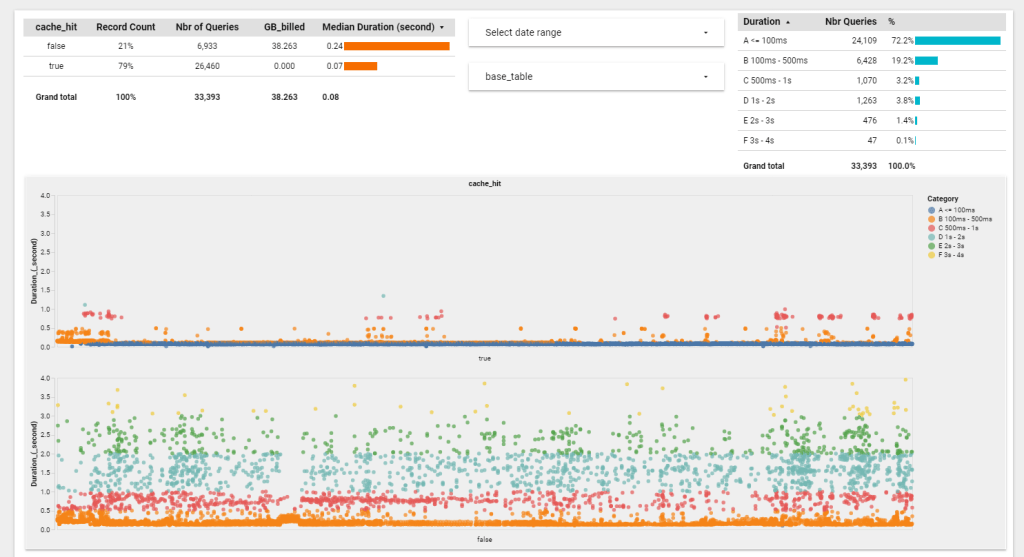
Personally I am very interested in Case 4, obviously if I reserve a Memory I want to minimize scanned storage to the lowest possible, here is the result for the last 10 days, I think that’s a great result, my ” Big Table is 6 GB, 50 Million rows” other tables are smaller , the dev team said they are working on improving even more how BI Engine algorithm deals with smaller tables, so far happy with that. ( it is fixed now, the memory consumption is extremely low now )
I appreciate other users with flat rate pricing would not care that much about file scanned , for user with usage based pricing, it is a very important factor

Query Performance
Again the results is based on my usage, the only way to know is to try it yourself, nearly 72 % of Queries render in less than 100 ms, I think it is fair to say, we are into a different kind of data warehouse architecture
PowerBI Performance
The Query Performance is only a portion of the whole story, you need to add network latency and PowerBI overhead ( DAX calculation, Viz rendering etc), my data is in Tokyo Region and PowerBI Service is located in Melbourne, a bit of distance I would say and using Publish to web add an extra latency.
The good thing, using Direct Query on a 51 Million Fact table with 5 dimensions is an achievement in itself, I feel I can use that in a Production, at the same time, using other report, it seems I am hitting a bug in the ODBC driver, and the performance is not good.
but to be totally Honest, it seems PowerBI driver for BigQuery is far from being optimized, it seems they are using SIMBA ODBC , other BI tools are using the native API and it is substantially faster, but I have reason to believe the PowerBI team will invest more in better Integration ( PowerBI parameter in SQL Query is coming for example)
I Think it is extremely interesting new development, specially if you have Big Fact tables or data that change very frequently, Direct Query mode have a lot of advantages, it is very simple to setup, the data is always fresh and there is no data movement. and BI Engine is fast, extremely Fast, and Cheap !!!, I am using a state of the art data warehouse for $30 per month !!!!, now it is up to The PowerBI Team to take advantage of that.

Nice article, thank you.
Power BI now offers a native BQ driver (since octobre afair).
LikeLike
I don’t think so, it is still using ODBC not the native API
LikeLike
Dear mim
Congrats for your great post
I confirm Microsoft use SIMBA ODBC technology for its power query connector
It’s called Biquery native connector
You can see information here :
for PowerBI Desktop: Download Center:C:\Program Files\Microsoft Power BI Desktop\bin\ODBC Drivers\“
for Windows Store:C:\Program Files\WindowsApps\Microsoft.MicrosoftPowerBIDesktop_“{=html}\bin\ODBC Drivers\“
Every body (data architect) would like a great technology improvement here !!! avoid “old” ODBC
MS is tested a SSO directquery version of connector (RLS on BQ side will be possible)
Sorry mim , do you know if GCP BI engine can reduce power bi direct query data processed cost ?
and improve performances
I guess yes
Sorry I didn’t read well – But to GCP test bi engine (over bigquery) on pbi desktop do we need a new connector .. or we can use BQ native connector ?
LikeLike