I could have written a nice paragraph why I got interested in SingleStore but to be honest the reason is very simple and has nothing about the tech, Jordan Tigani one of the founding Engineers of BigQuery is now their Chief Product Officer, so I became very curious 🙂
Again, I am only interested in Small Interactive BI Workload, contrary to the usual Suspects ( BigQuery, Snowflake etc), SingleStore is not a pure Data warehouse but rather a multi purpose database, it does OLTP Workloads but has an excellent support for OLAP Workload, I am only interested in Analytical Workloads.
Setup
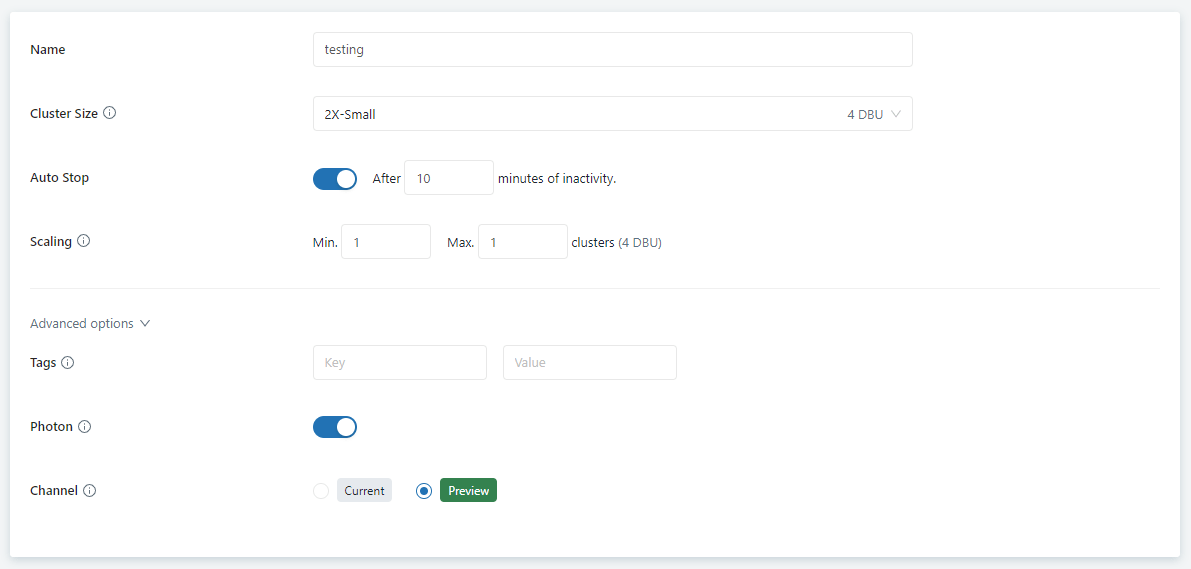
There is a free trial with $500, the setup was very intuitive, I really liked the way you create a new Cluster, notice I don’t have an account with AWS, but it is a software as a service Experience, SingleStore manage everything on behalf of the user, I chose AWS as they support the Sydney Region.
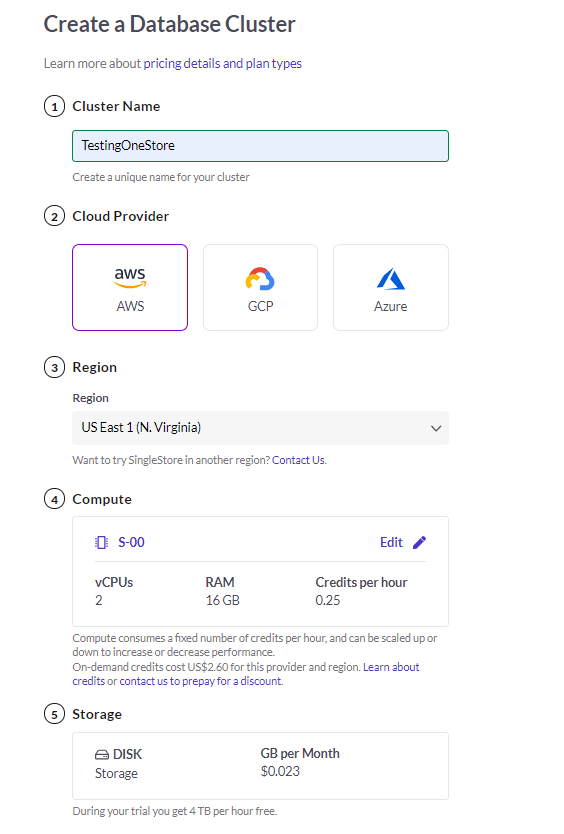
The smallest tier start at 0.25 Credit/hour, which cost 0.65 $/Hour, Unlike Snowlake and Databricks there is no auto suspend and auto start, you have to do it manually.

For some reason Suspend a Cluster is not available in Google Cloud !!!
The Console has the bare minimum but functional, there is no multiple tab, if you run a Query, you need to wait till it is done before running another one

There is an odd choice in the UI, when you want to monitor the Cluster you need to open a new page called SingleStore Studio

It is not the end of the world, but a bit annoying when you are new to the product
Loading Data
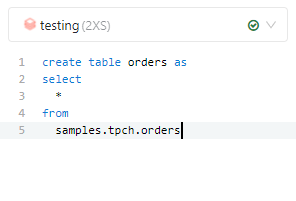
There is sample Data you can quickly load to start running Queries, but I wanted to test only my own dataset (TPC-H- SF10) ( nice surprise it was added this week)
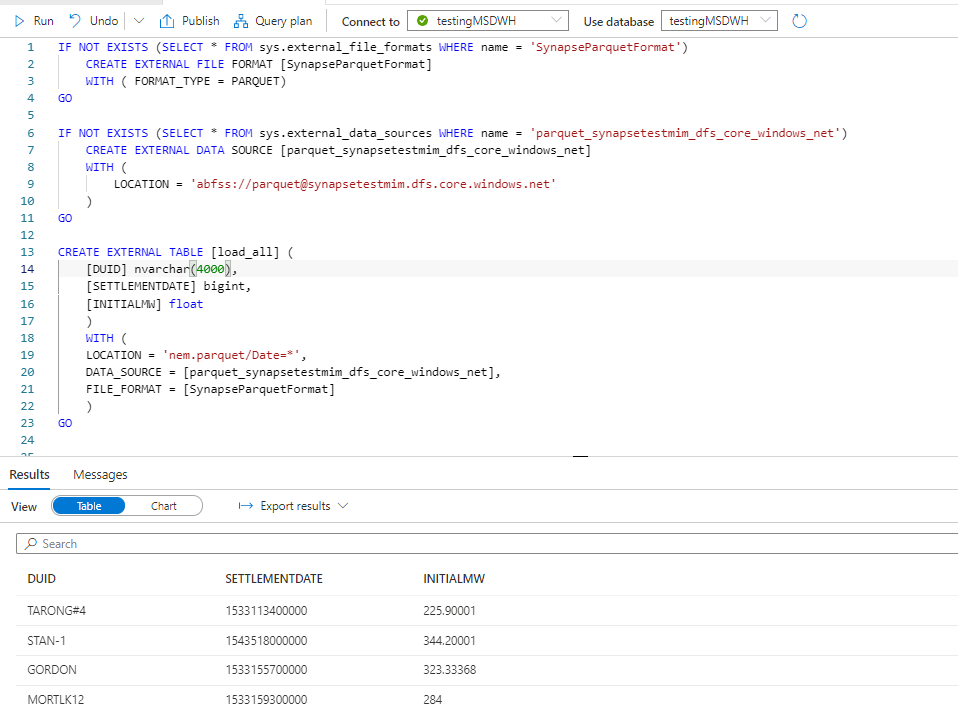
Although my Cluster is in AWS, loading files from Google Cloud was trivial, all I had to do is setup a new pipeline
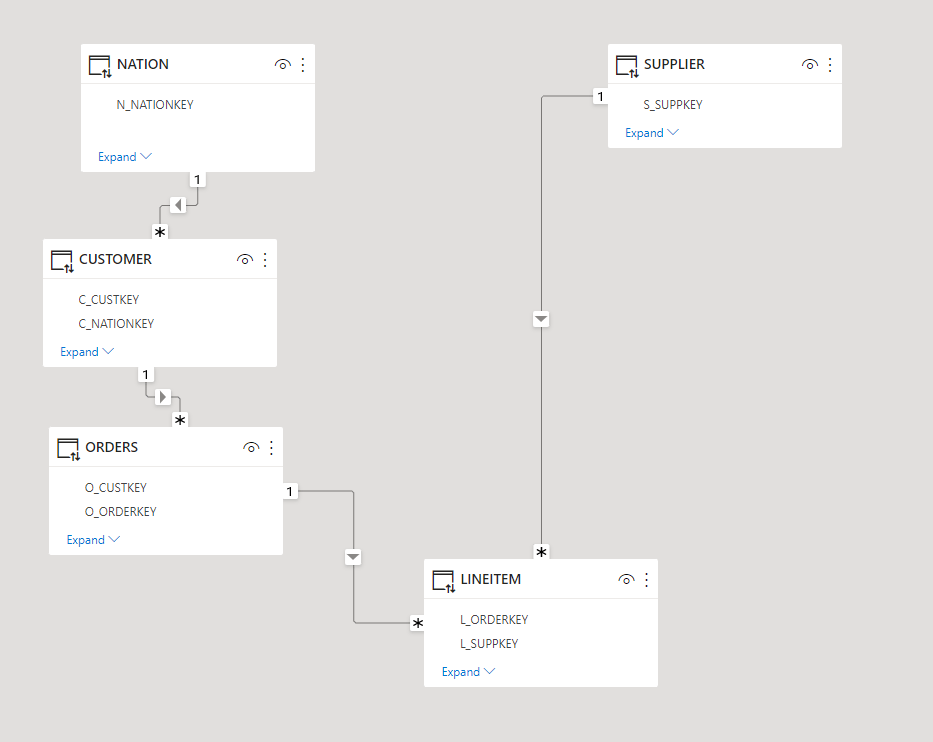
first define the table, notice the Clustered Columnstore key
CREATE TABLE `orders` ( `o_orderkey` bigint(11) NOT NULL, `o_custkey` int(11) NOT NULL, `o_orderstatus` char(1) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL, `o_totalprice` decimal(15,2) NOT NULL, `o_orderdate` date NOT NULL, `o_orderpriority` char(15) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL, `o_clerk` char(15) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL, `o_shippriority` int(11) NOT NULL, `o_comment` varchar(79) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL, SHARD KEY (`o_orderkey`) USING CLUSTERED COLUMNSTORE );
Define a new pipeline
CREATE or REPLACE PIPELINE `LoadGCPorders`
AS LOAD DATA GCS 'xxxxxxxxxxxxx'
CREDENTIALS '{"access_id": "xxx", "secret_key": "xxxxxx"}'
INTO TABLE tpch.orders
(`O_ORDERKEY` <- `O_ORDERKEY`,
`O_CUSTKEY` <- `O_CUSTKEY`,
`O_ORDERSTATUS` <- `O_ORDERSTATUS`,
O_TOTALPRICE <- O_TOTALPRICE
, O_ORDERDATE <- O_ORDERDATE
, O_ORDERPRIORITY <- O_ORDERPRIORITY
, O_CLERK <- O_CLERK
, O_SHIPPRIORITY <- O_SHIPPRIORITY
, O_COMMENT <- O_COMMENT
)
FORMAT PARQUET
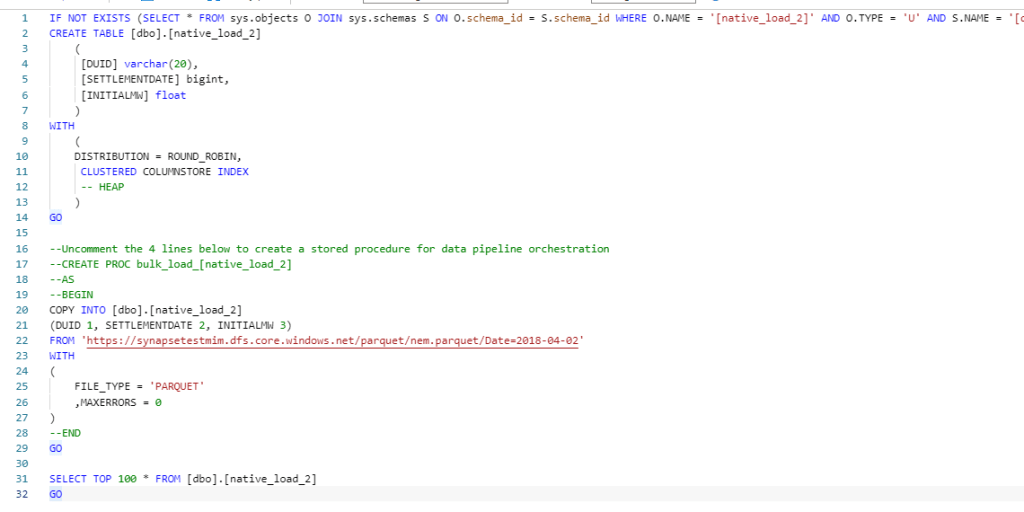
Then Run the pipeline and the data is automatically loaded, very nice
START PIPELINE LoadGCPorders FOREGROUND;
Testing using TPC-H SF10 Benchmark
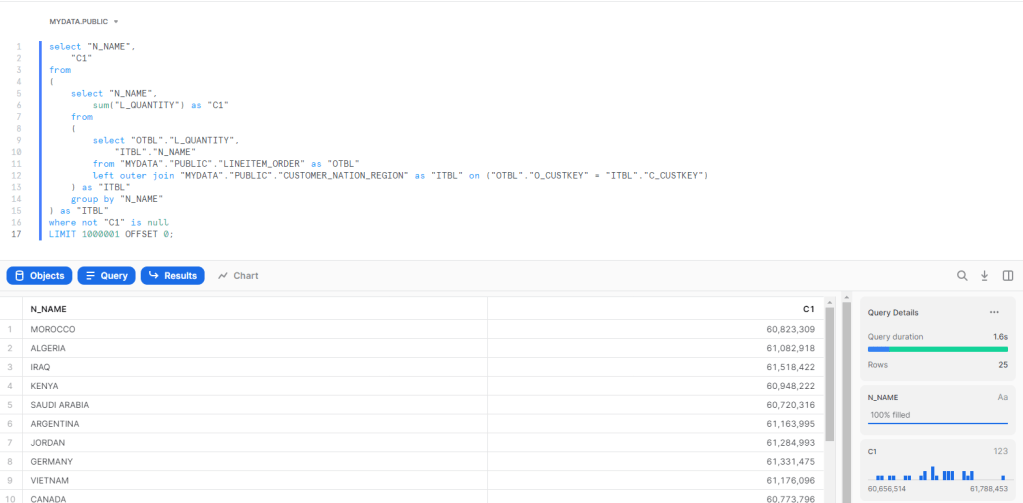
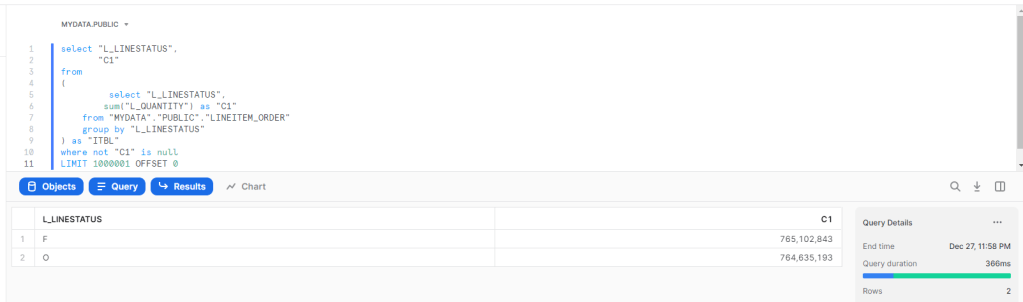
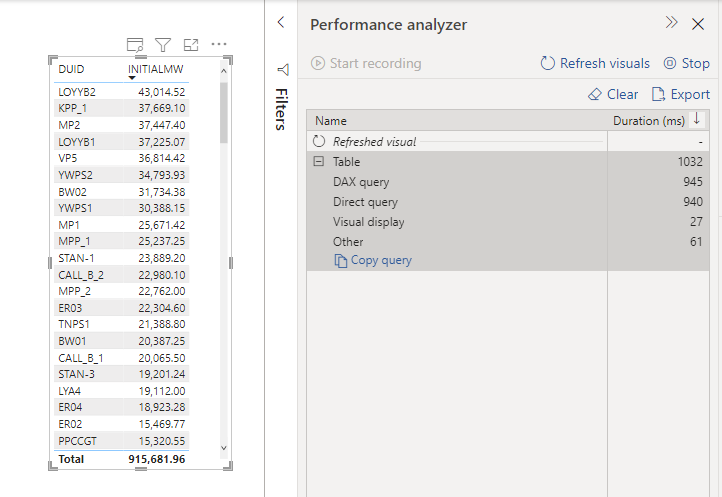
to test all the 22 Queries of the benchmark I used the same script for BI Engine, here is the results after 10 runs using the Dataset Provided by Singlestore ( Using S-0 Cluster, see pricing here)

A lot of Queries are already under a second even when using a lower tier !!! Queries 13 result is a bit odd.
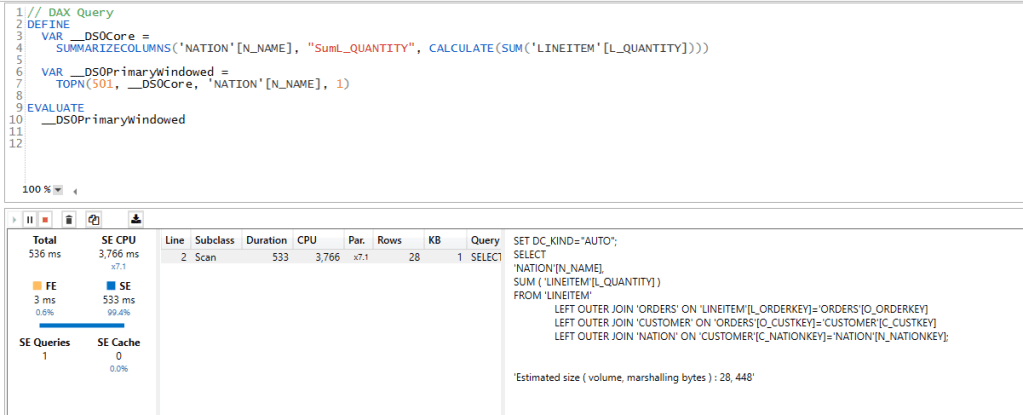
if I understood correctly, SingleStore does not have a results cache when you run the same Query again, SingleStore store the Query plan but scan the data again, although the data is stored on Disk, metadata on the tables is stored In-Memory ( tables for OLTP workload are always In-Memory)
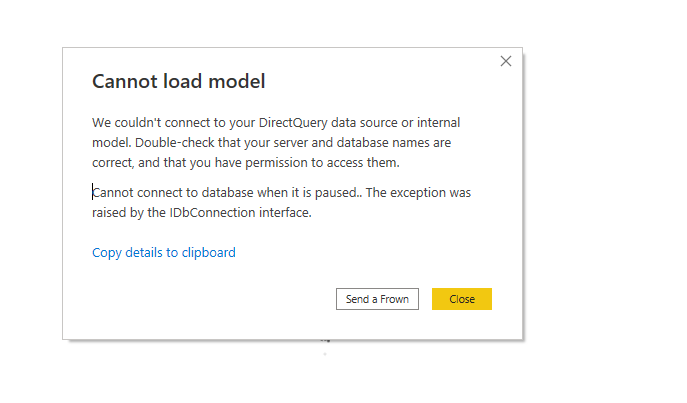
The Previous chart was built using Google Data Studio, as of this writing, PowerBI does not have a native connector, you need to download a custom connector which means you need a gateway, not sure if Direct Query is supported at all, I quickly used MySQL connector which works fine but import mode only (SingleStore is compatible with MySQL tools)
Take Away
I was really impressed by the Product, we all hear about this operational analytics and it seems SingleStore has a good solution, there are missing functionalities though, Auto suspend and resume is not available yet and no native connector for PowerBI is very problematic, but it is really Fast and do write workload too.