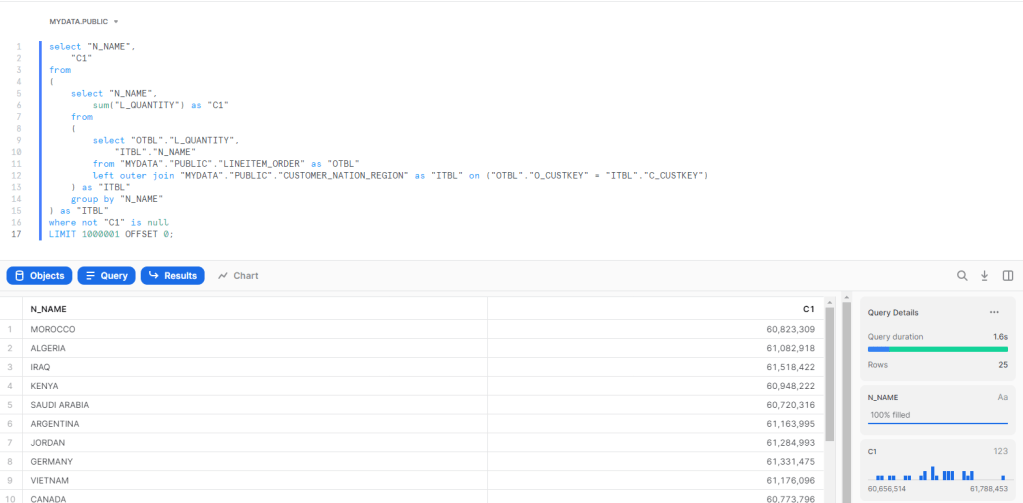
Hybrid table is a Clever technical solution to a very fundamental problem in Data Analytics, How to keep Data fresh and at the same time fast, PowerBI , Tableau, Qlik solved this problem by importing data to a local Cache, this solution work for most of the use cases, but as with any solution it has limitation.
- If the Data Source is too big, you can’t simply keep importing to the local cache.
- If the Data Source change very frequently, like every couple of minutes or second, importing become just not practical or very hard.
PowerBI Engine team came up with a very simple Idea, you can have both Mode in the same table, Historical data that don’t change is cached and today data is queried live as it changed very quickly, Patrick from Guy in the Cube has a great video , Andy has another Video but specific to Synapse Serverless
This functionality was released in the December 2021 edition of PowerBI , but unfortunately when I test it with BigQuery, it did not work, I reported the issue and I have to say, I was really impressed by the Product team, (Kudos to Christian Wade and Krystian Sakowski ), yesterday they released an updated version and it fixed the issue. (it works with Snowflake, Databricks etc)
Setup
it is literary just an extra box to click compared to the Previous incremental refresh User interface
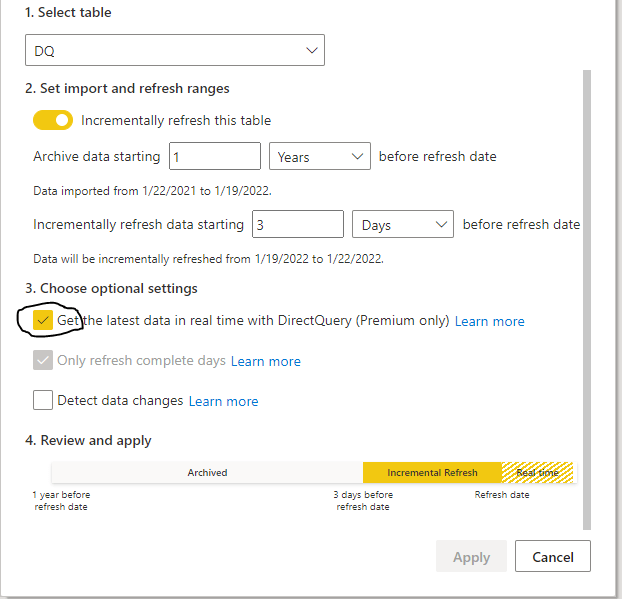
Yes, Just like that, The Engine will generate table partitions behind the scene, if you want to know why PowerBI is so successful, it is because of stuff like this, take a very hard problem and make it extremely easy for Non Tech people to use.
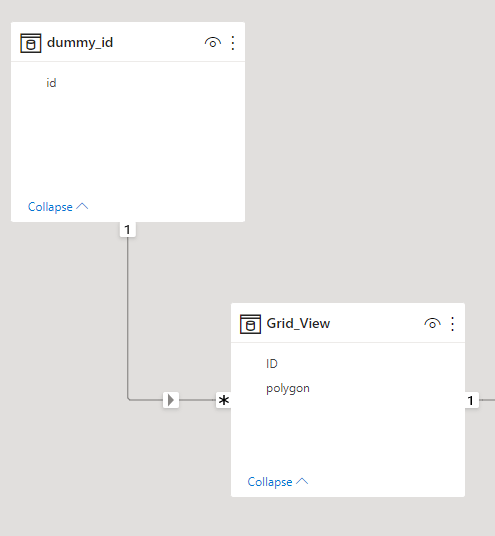
The Data Model is very simple; one fact table with Data that change every couple of minutes, and a Date dimension in a Mixed mode, ( watch Patrick Video, he explain why)

Premium Only
Yes, it is a premium only feature, and obviously it works with Premium per User, I am not going to complain, someone needs to pay for those R&D cost, but it will be really nice if they release it to the PRO license too, it just feels Odd that a core feature of the Engine is tied to a particular license, we had this situation before with incremental refresh and they did release it even for the free license, I hope the same will happen with Hybrid Table.
Mixed Partitions
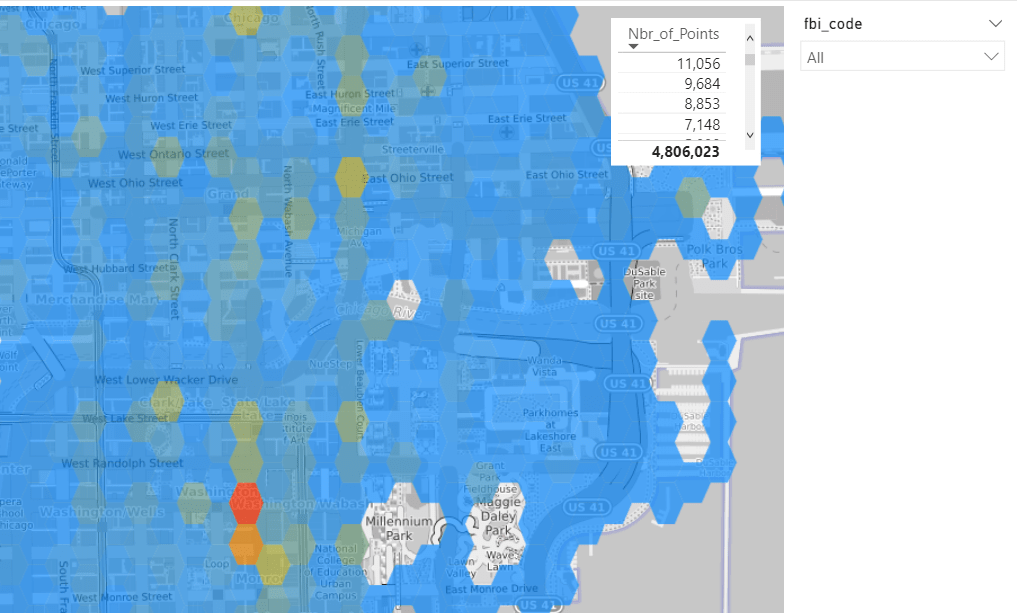
I published the report to the service, and used Tabular Editor to see what’s going on behind the scene (make sure you download the latest version of Tabular Editor, works with the free version too)
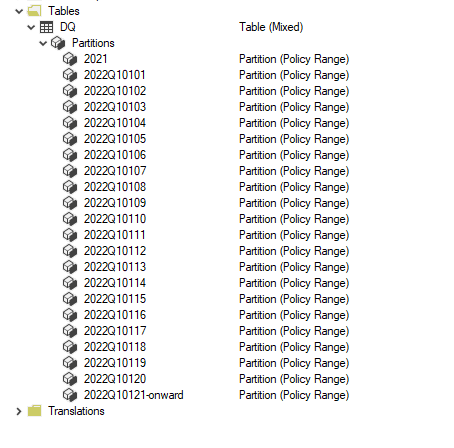
As expected the Last Partition is Live Mode, and everything else is cached in PowerBI.
How it Works
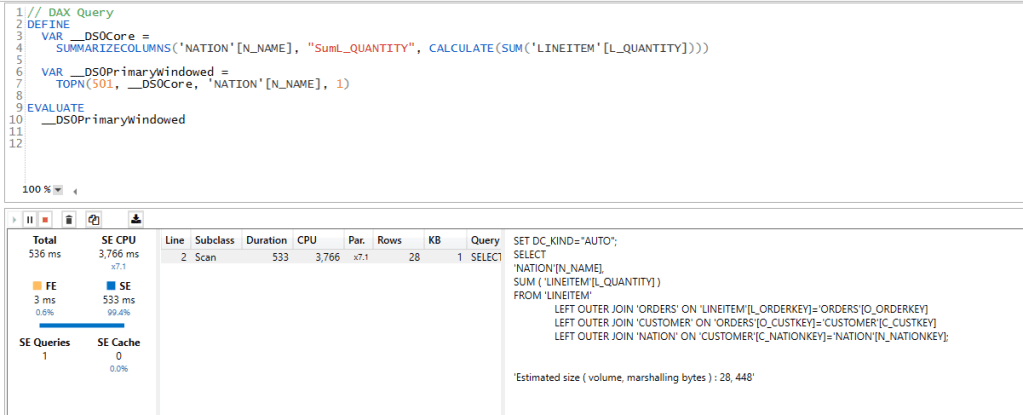
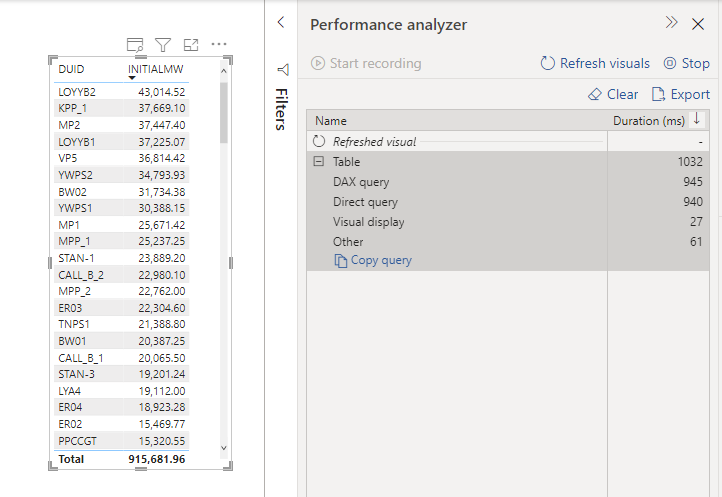
I used DAX Studio to capture what the engine is doing when you run a Query
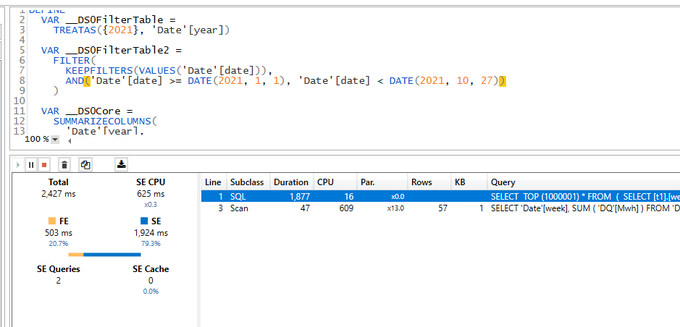
PowerBI formula engine send two Queries one to the remote DB in my case BigQuery and the local Storage, you can clearly see the difference in speed
1 Day using DQ : 2 second ( the Query take 400 ms at the end point, But BigQuery has a very substandard ODBC driver)
13 Months worth of Data Cached : 47 ms
The Point is, if you can just import, do it, you will get the best performance and user experience
( At Work we have a sub 5 minute pipeline end to end from the Source DB to PowerBI).
The Devil is in the details
As far as I can tell, Formula Engine keep sending two Queries every time, even when the required data is cached already, obviously the Query from the external DB will return null results, in Theory , it should not be a big deal, Modern DW are fast specially with partitioning pruning.
Unfortunately no, only some Database can return a sub second null result set to PowerBI ( yes the Quality of the Driver is as important as the DB Engine itself)
Take Away
It is a very interesting solution worth testing for specific scenarios, but if you can get away with Importing data only, then it is still the best way, yes Hybrid Table reduce the Workload on the remote Database, but still you need a solid Database, getting a sub second Query from end to end is still a hard problem even for 1 day worth of data ( just test it, don’t forget concurrency )
I heard a different use cases, which I find very intriguing, some users want the other way around, recent Data as Import and historical Data as Direct Query, I guess it is useful if you have a real big fact Table.
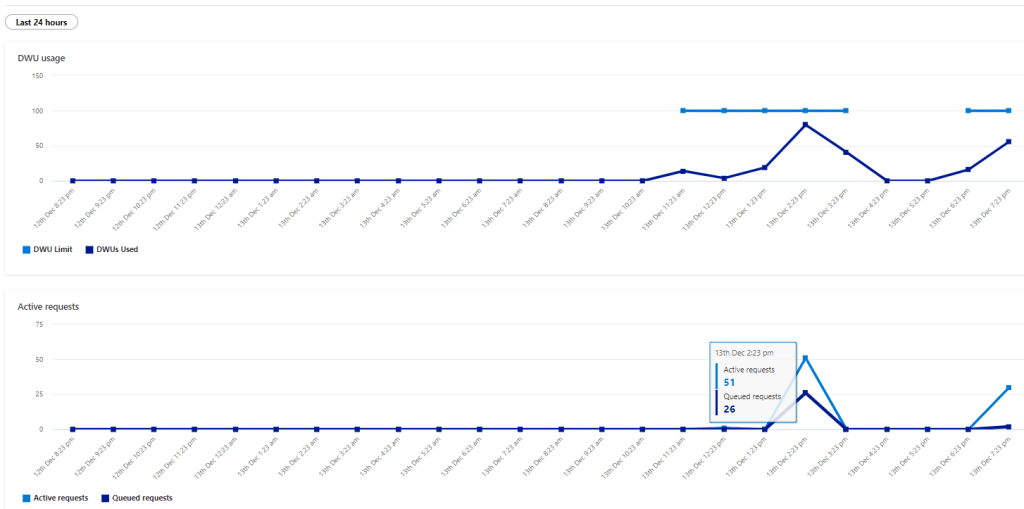
A Surprising side effect of PowerBI Hybrid table,( maybe it was planned, who knows) Synapse Serverless in Direct Query mode looks now like a very good candidate to use, scanning one day of data is faster and an order of magnitude cheaper !!!
I still Hope that the Vetipaq Engine team surprise us in a future update and somehow let the Formula engine generate only 1 Query when all Data needed is in the Local cache.