While preparing for a presentation about the FabCon announcement, one item was about OneLake Diagnostics. all ll I knew was that it had something to do with security and logs. As a Power BI user, that’s not exactly the kind of topic that gets me excited, but I needed to know at least the basic, so I can answer questions if someone ask 🙂
Luckily, we have a tradition at work , whenever something security-related comes up, we just ping Amnjeet🙂
He showed me how it works , and I have to say, I loved it. It’s refreshingly simple.
You just select a folder in your Lakehouse and turn it on.
That’s it , the system automatically starts generating JSON files, neatly organized using Hive-style partitions, By default, user identity and IP tracking are turned off unless an admin explicitly enables them. You can find more details about the schema and setup here.
What the Logs Look Like
Currently, the logs are aggregated at the hourly level, but the folder structure also includes a partition for minutes (even though they’re all grouped at 00 right now).
Parsing the JSON Logs
Once the logs were available, I wanted to do some quick analysis , not necessarily about security, just exploring what’s inside.
There are probably half a dozen ways to do this in Fabric ; Shortcut Transform, RTI, Dataflow Gen2, DWH, Spark, and probably some AI tools too, Honestly, that’s a good problem to have.
But since I like Python notebooks and the data is relatively small, I went with DuckDB (as usual), but Instead of using plain DuckDB and delta_rs to store the results, I used my little helper library, duckrun, to make things simpler ( Self Promotion alert).
Then I asked Copilot to generate a bit of code for registering existing functions to look up the workspace name and lakehouse name from their GUIDs in DuckDB, using SQL to call python is cool 🙂
The data is stored incrementally, using the file path as a key , so you end up with something like this:
Then I added only the new logs with this SQL script:
try:
con.sql(f"""
CREATE VIEW IF NOT EXISTS logs(file) AS SELECT 'dummy';
SET VARIABLE list_of_files =
(
WITH new_files AS (
SELECT file
FROM glob('{onelake_logs_path}')
WHERE file NOT IN (SELECT DISTINCT file FROM logs)
ORDER BY file
)
SELECT list(file) FROM new_files
);
SELECT * EXCLUDE(data), data.*, filename AS file
FROM read_json_auto(
GETVARIABLE('list_of_files'),
hive_partitioning = true,
union_by_name = 1,
FILENAME = 1
)
""").write.mode("append").option("mergeSchema", "true").saveAsTable('logs')
except Exception as e:
print(f"An error occurred: {e}")
1- Using glob() to collect file names means you don’t open any files unnecessarily , a small but nice performance win.
2- DuckDB expand the struct using this expression data.*
3- union_by_name = 1 in case the json has different schemas
4- option(“mergeSchema”, “true”) for schema evolution in Delta table
Exploring the Data
Once the logs are in a Delta table, you can query them like any denormalize table.
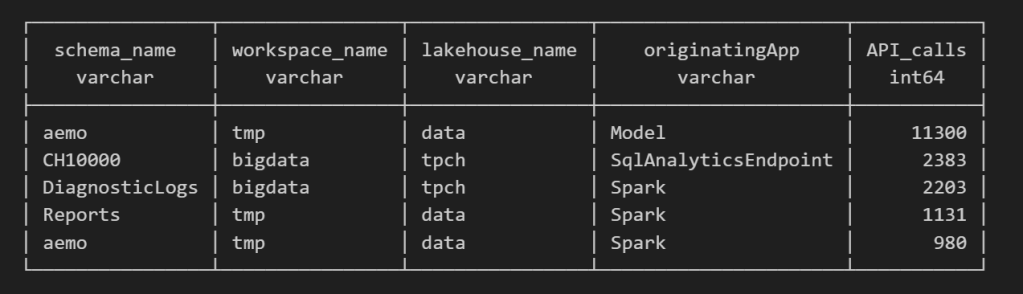
For example, here’s a simple query showing API calls per engine:
Note : using AI to get working regex is maybe the best thing ever 🙂
SELECT
regexp_extract(resource, '([^&/]+)/([^&/]+)/(Tables|Files)(?:/([^&/]+))?(?:/([^&/]+))?', 4) AS schema_name,
get_workspace_name(workspaceid) AS workspace_name,
get_lakehouse_name(workspaceid, itemId) AS lakehouse_name,
originatingApp,
COUNT(*) AS API_calls
FROM logs
GROUP BY ALL
ORDER BY API_calls DESC
LIMIT 5;
Fun fact: OneLake tags Python notebook as Spark. Also, I didn’t realize Lineage calls OneLake too!
as I have already register Python functions as UDFs, which is how I pulled in the workspace and lakehouse names in the query above.
Takeaway
This was just a bit of tinkering, but I’m really impressed with how easy OneLake Diagnostics is to set up and use.
I still remember the horrors of trying to connect Dataflow Gen1 to Azure Storage ,that was genuinely painful (and I never even got access from IT anyway).
It’s great to see how Microsoft Fabric is simplifying these scenarios. Not everything can always be easy, but making the first steps easy really gives the feature a very good impression.
I was giving a presentation about Microsoft Fabric Python notebooks and someone asked if they scale. The short answer is yes. You can download the notebook and try it for yourself. For the long answer, keep reading.
The dataset I used contains the last seven years of Australian electricity market data. Although it’s public, the government agency only keeps archives for two months. I had saved the data during a previous job and kept it around as a hobby. It’s a great real-world workload with realistic data distribution. The CSV files are messy. Technically, they’re more like reports, with different sections stacked on top of each other and varying numbers of columns. That’s often what you encounter in real projects, not the neat, well-structured datasets you see in demos.
For example, being able to read a CSV file with a variable number of columns is a critical feature. Yet this rarely gets mentioned in synthetic benchmarks.
To create a clean environment for testing, I copied the data from one Lakehouse in onelake to a brand-new workspace. I could have used a shortcut, but I wanted to start from scratch. The binary copy took just 2 minutes, with no transformations, which gives a throughput of 1.4 GB per second. That’s pretty good for a 150 GB uncompressed dataset.
The default configuration for Fabric Python notebooks includes 2 cores and 16 GB of RAM. That’s roughly the same size as Google Colab. But you can easily increase the number of cores to 4, 8, 16, 32, or even 64. At 64 cores, you get nearly half a terabyte of RAM. That’s a serious machine.
The job itself is simple. Ingest and process the data using several Python engines, then save the result as a Delta table. The raw data has around one billion records, and you end up extracting 311 million. If your engine cannot push down filters to the CSV level, you’re going to have a hard time. The trick here is not to be fast, but to avoid doing unnecessary work.
I used the following engines: DuckDB, Daft, Polars, CHDB (basically ClickHouse for Python), DataFusion, PyArrow, and Pandas. Technically, Pandas is not ideal here because you can’t pass a list of files without using a loop. But I had used it for nearly seven years, so I kept it for sentimental reasons.
I’m fairly confident using all of these engines except PyArrow and DataFusion. Their syntax is very intimidating, and I probably missed some configuration settings. I couldn’t get them to use more than a single thread, so CPU utilization stayed very low.
Results
Polars support streaming writes, but doesn’t allow exporting a record batch. This means the Delta writer has to load all data into memory. It works fine with 32 cores and 256 GB of RAM, but you’ll run into out-of-memory issues with 16 cores and below.
Chdb 3.5 added a user friendly way to export arrow record batch, it is the first release so still some bugs, for example got an error with 2 cores, I am sure it will get fixed soon
Daft is the only engine that supports native writing to Delta. It uses the Deltalake package only to commit the transaction log. The actual Parquet write is handled by the engine itself.
DuckDB preserves the sort order of the input files. it is trick to appeal to Pandas users who care about index ordering. For best performance though, you should turn this off. (Honestly, I think it should be off by default)
DuckDB exports Arrow tables by default. You need to explicitly use record_batch(). I’ve lost count of how many out-of-memory issues I’ve solved just by changing the export format.
Overall, DuckDB delivered the best performance, especially considering it’s not even writing Parquet files directly. It simply streams Arrow data to the writer.
When I first ran the test with DuckDB and saw it finish in under 4 minutes, I thought I made a mistake. It wasn’t until CHDB finished in under 5 minutes that I realized these engines are seriously impressive.
We’re talking about 625 MB per second for processing and ingestion on a single node.
Another key observation: using DuckDB and Daft, even with just 16 GB of RAM, the data was processed correctly. It took about an hour, but it worked without errors, that’s 10 X the size of the RAM
To verify correctness, I simply checked the total sum of a column and the number of records. Everything checked out.
Choosing the Right Size
Now that I know these notebooks work, choosing the right size becomes more nuanced. Surprisingly, the cheapest configuration in term of capacity usage was the 2 cores 🙂
In practice though, using more compute makes sense. A single node has no concept of fault tolerance. If something goes wrong, you need to restart the entire job. Personally, I’m not a fan of long-running jobs. Too many things can go wrong. I used 2 cores just to make a point. That said, using 64 cores doesn’t make much sense either. You’re doubling your compute cost to save 30 seconds.
One more thing: while Daft scales down very well, it doesn’t seem to scale up as efficiently as I had hoped. Ideally, you want a flat performance curve. The total amount of work is fixed, so adding more cores should just reduce execution time. I know the reality is more complex. It’s not easy to keep all processors busy at higher scales.
What This Means
As you may have guessed, I’m a big fan of single-node setups and DuckDB. But I don’t want just one engine to dominate every benchmark or deliver results that no other engine in its class can match. That’s why I was genuinely excited by Daft’s performance. I’m also looking forward to seeing Polars and CHDB add Arrow streaming support.
To be honest, I look at the world from a storage perspective. More competition between engines is a good thing. All of these tools are open source under the MIT license. Most of them can write to Delta in one form or another. and as a user you can choose any engine you want, I think that’s a fantastic thing to have.
So yes, Python notebooks do scale. The experience is far from being perfect, and there’s still room for improvement. But scalability is not something you should worry about, unless of course you are really doing real big data, then you go distributed 🙂 DWH and Spark are robust options in Fabric.
Edit : tested with chdb 3.5 which has support for arrow streaming
This is not an official Microsoft benchmark, just my personal experience.
Last week, I came across a new TPCH generator written in Rust. Luckily, someone ported it to Python, which makes generating large datasets possible even with a small amount of RAM. For example, it took 2 hours and 30 minutes to generate a 1 TB scale dataset using the smallest Fabric Python notebook (2 cores and 16 GB of RAM).
Having the data handy, I tested Fabric DWH and SQL Endpoint. I also tested DuckDB as a sanity check. To be honest, I wasn’t sure what to expect.
I ran the test 30 times over three days, I think I have enough data to say something useful,In this blog, I will focus only on the results for the cold and warm runs, along with some observations.
For readers unfamiliar with Fabric, DWH and SQL Endpoint refer to the same distributed SQL engine. With DWH, you ingest data that is stored as a Delta table (which can be read by any Delta reader). With SQL Endpoint, you query external Delta tables written by Spark and other writers (this is called a Lakehouse table). Both use Delta tables.
Notes:
All the runs are using a Python notebook
to send queries to DWH/SQL Endpoint, all you need is conn = notebookutils.data.connect_to_artifact("data") conn.query("select 42")
I did not include the cost of ingestion for the DWH
The cost include compute and storage transaction and assume pay as you go rate of 0.18 $/Cu(hour)
For extracting Capacity usage, I used this excellent blog
Cold Run
The first-ever run on SQL Endpoint incurs an overhead, apparently the system build statistics. This overhead happened only once across all tests.
Point 2 is an outlier but an interesting one 🙂
The number of dots displayed is less than the number of tests runs as some tests perfectly match, which is a good sign that the system is predictable !!!
vorderimproves performance for both SQL Endpoint and DuckDB. The data was generated by Rust and rewritten using Spark; it seems to be worth the effort.
Costs are roughly the same for DWH and SQL Endpoint when the Delta is optimized by vorder, but DWH is still faster.
DuckDB, running in a Python notebook with 64 cores, is the cheapest (but the slowest). Query 17 did not run , so that result is moot. ,Still, it’s a testament to the OneLake architecture: third-party engines can perform well without any additional Microsoft integration. Lakehouse for the win.
Warm Run
vorder is better than vanilla Parquet.
DWH is faster and a bit cheaper than SQL Endpoint.
DuckDB behavior is a bit surprising, was expecting better performance , considering the data is already loaded into RAM.
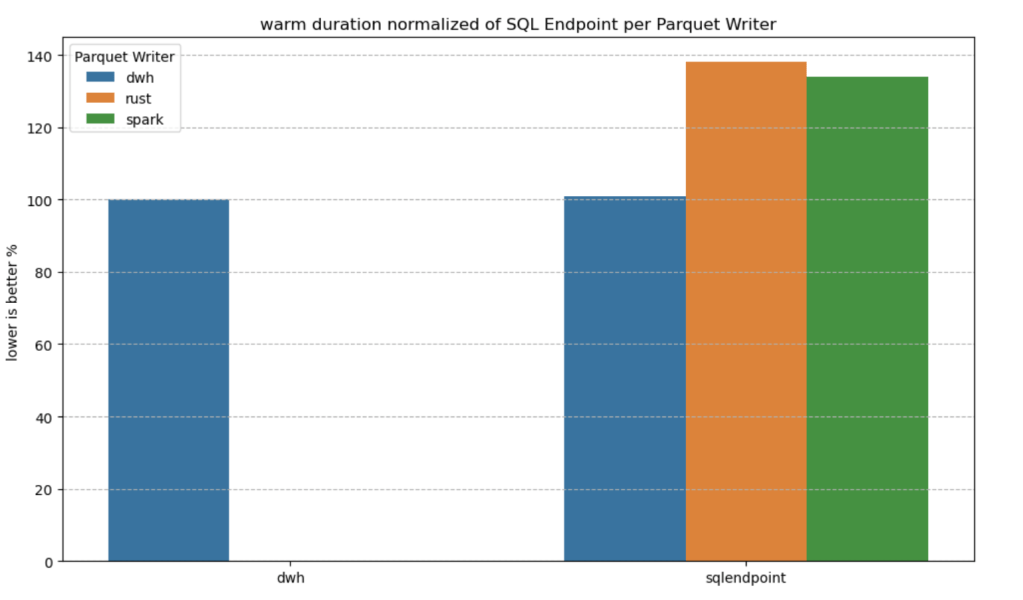
Impact on the Parquet Writer
I added a chat showing the impact of using different writers on the read performance, I use only warm run to remove the impact of the first run ever as it does not happen in the DWH ( as the data was ingested)
given the same table layout, DWH and SQL Endpoint perform the same, it is expected as it is the same engine
surprisingly using the initial raw delta table vs spark optimize write gave more or less the same performance at least for this particular workload.
Final Thoughts
Running the test was a very enjoyable experience, and for me, that’s the most important thing. I particularly enjoyed using Python notebooks to interact with Fabric DWH. It makes a lot of sense to combine a client-server distributed system with a lightweight client that costs very little.
There are new features coming that will make the experience working with DWH even more streamlined.
Edit :
update the figures for Dcukdb as Query 17 runs but you need to limit the memory manually set memory_limit='500GB'
added a graph on the impact of the parquet layout.
Note: The blog and especially the code were written with the assistance of an LLM.
TL;DR
I built a simple Fabric Python notebook to orchestrate sequential SQL transformation tasks in OneLake using DuckDB and delta-rs. It handles task order, stops on failure, fetches SQL from external sources (like GitHub or a Onelake folder), manages Delta Lake writes, and uses Arrow recordbacth for efficient data transfer, even for large datasets. This approach helps separate SQL logic from Python code and simulates external table behavior in DuckDB. Check out the code on GitHub: https://github.com/djouallah/duckrun
pip install duckrun
Introduction
Inspired by tools like dbt and sqlmesh, I started thinking about building a simple SQL orchestrator directly within a Python notebook. I was showing a colleague a Fabric notebook doing a non-trivial transformation, and although it worked perfectly, I noticed that the SQL logic and Python code were mixed together – clear to me, but spaghetti code to anyone else. With Fabric’s release of the user data function, I saw the perfect opportunity to restructure my workflow:
Data ingestion using a User-Defined Function (UDF), which runs in a separate workspace.
Data transformation in another workspace, reading data from the ingestion workspace as read-only.
All transformations are done in pure SQL, there 8 tables, every table has a sql file, I used DuckDB, but feel free to use anything else that understands SQL and output arrow (datafusion, chdb, etc).
Built Python code to orchestrate the transformation steps.
PowerBI reports are in another workspace
I think this is much easier to present 🙂
I did try yato, which is a very interesting orchestrator, but it does not support parquet materialization
How It Works
The logic is pretty simple, inspired by the need for reliable steps:
Your Task List: You provide the function with a list (tasks_list). Each item has table_name (same SQL filename, table_name.sql) and how to materilize the data in OneLake (‘append’ , ‘overwrite’,ignore and None)
Going Down the List: The function loops through your tasks_list, taking one task at a time.
Checking Progress: It keeps track of whether the last task worked out using a flag (like previous_task_successful). This flag starts optimistically as True.
Do or Don’t: Before tackling the current task, it checks that flag.
If the flag is True, it retrieves the table_name and mode from the current task entry and passes them to another function, likely called run_sql. This function performs the actual work of running your transformation SQL and writing to OneLake.
If the flag is False, it knows something went wrong earlier, prints a quick “skipping” message, and importantly, uses a break statement to exit the loop immediately. No more tasks are run after a failure.
Updating the Status: After run_sql finishes, run_sql_sequence checks if run_sql returned 1 (our signal for success). If it returns 1, the previous_task_successful flag stays True. If not, the flag flips to False.
Wrap Up: When the loop is done (either having completed all tasks or broken early), it prints a final message letting you know if everything went smoothly or if there was a hiccup.
The run_sql function is the workhorse called by run_sql_sequence. It’s responsible for fetching your actual transformation SQL (that SELECT … FROM raw_table). A neat part here is that your SQL files don’t have to live right next to your notebook; they can be stored anywhere accessible, like a GitHub repository, and the run_sql function can fetch them. It then sends the SQL to your DuckDB connection and handles the writing part to your target OneLake table using write_deltalake for those specific modes. It also includes basic error checks built in for file reading, network stuff, and database errors, returning 1 if it succeeds and something else if it doesn’t.
You’ll notice the line con.sql(f””” CREATE or replace SECRET onelake … “””) inside run_sql; this is intentionally placed there to ensure a fresh access token for OneLake is obtained with every call, as these tokens typically have a limited validity period (around 1 hour), keeping your connection authorized throughout the sequence.
When using the overwrite mode, you might notice a line that drops DuckDB view (con.sql(f’drop VIEW if exists {table_name}’)). This is done because while DuckDB can query the latest state of the Delta Lake files, the view definition in the current session needs to be refreshed after the underlying data is completely replaced by write_deltalake in overwrite mode. Dropping and recreating the view ensures that subsequent queries against this view name correctly point to the newly overwritten data.
The reason we do this kind of hacks is, duckdb does not support external table yet, so we are just simulating the same behavior by combining duckdb and delta rs, spark obviousely has native support
Handling Materialization in Python
One design choice here is handling the materialization strategy (whether to overwrite or append data) within the Python code (run_sql function) rather than embedding that logic directly into the SQL scripts.
Why do it this way?
Consider a table like summary. You might have a nightly job that completely recalculates and overwrites the summary table, but an intraday job that just appends the latest data. If the overwrite or append command was inside the SQL script itself, you’d need two separate SQL files for the exact same transformation logic – one with CREATE OR REPLACE TABLE … AS SELECT … and another with INSERT INTO … SELECT ….
By keeping the materialization mode in the Python run_sql function and passing it to write_deltalake, you can use the same core SQL transformation script for the summary table in both your nightly and intraday pipelines. The Python code dictates how the results of that SQL query are written to the Delta Lake table in OneLake. This keeps your SQL scripts cleaner, more focused on the transformation logic itself, and allows for greater flexibility in how you materialize the results depending on the context of your pipeline run.
Efficient Data Transfer with Arrow Record batch
A key efficiency point is how data moves from DuckDB to Delta Lake. When DuckDB executes the transformation SQL, it returns the results as an Apache Arrow RecordBatch. Arrow’s columnar format is highly efficient for analytical processing. Since both DuckDB and the deltalake library understand Arrow, data transfers with minimal overhead. This “zero-copy” capability is especially powerful for handling datasets larger than your notebook’s available RAM, allowing write_deltalake to process and write data efficiently without loading everything into memory at once.
Example:
you pass Onelake location, schema and the number of files before doing any compaction
first it will load all the existing Delta table
Here’s an example showing how you might define and run different task lists for different scenarios:
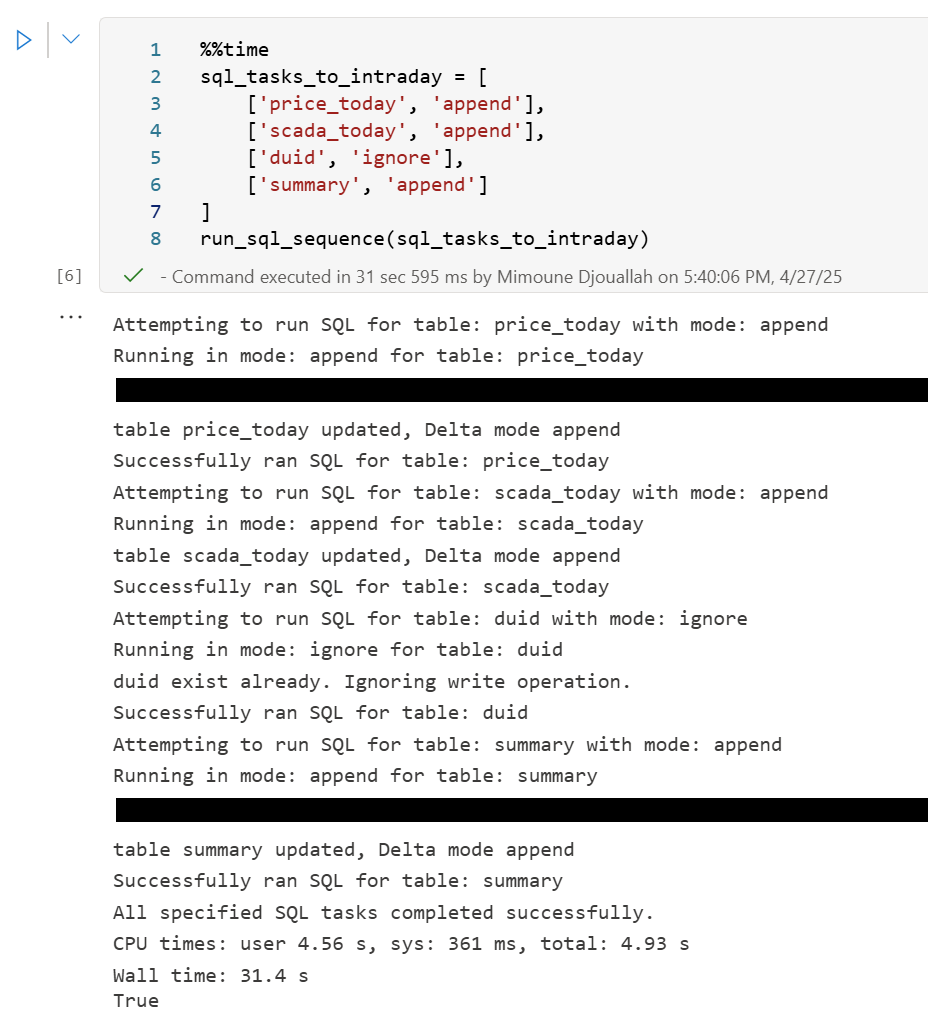
sql_tasks_to_intraday = [ ['price_today', 'append'], ['scada_today', 'append'], ['duid', 'ignore'], ['summary', 'append'] # Append to summary intraday using the *same* SQL script ]
You can then use Python logic to decide which pipeline to run based on conditions, like the time of day:
start = time(4, 0)
end = time(5, 30)
if start <= now_brisbane <= end:
run_sql_sequence(sql_tasks_to_run_nightly)
Here’s an example of an error I encountered during a run, it will automatically stop the remaining tasks:
Attempting to run SQL for table: price_today with mode: append
Running in mode: append for table: price_today
Error writing to delta table price_today in mode append: Parser Error: read_csv cannot take NULL list as parameter
Error updating data or creating view in append mode for price_today: Parser Error: read_csv cannot take NULL list as parameter
Failed to run SQL for table: price_today. Stopping sequence.
One or more SQL tasks failed.
here is some screenshots from actual runs
as it is a delta table, I can use SQL endpoints to get some stats
For example the table scada has nearly 300 Million rows, the raw data is around 1 billion of gz.csv
It took nearly 50 minutes to process using 2 cpu and 16 GB of RAM, notice although arrow is supposed to be zero copy, writing parquet directly from Duckdb is substantially faster !!! but anyway, the fact it works at all is a miracle 🙂
in the summary table we remove empty rows and other business logic, which reduce the total size to 119 Million rows.
here is an example report using PowerBI direct lake mode, basically reading delta directly from storage
In this run, it did detect that the the night batch table has changed
Conclusion
To be clear, I am not suggesting that I did anything novel, it is a very naive orchestrator, but the point is I could not have done it before, somehow the combination of open table table format, robust query engines and an easy to use platform to run it make it possible and for that’s progress !!!
I am very bad at remembering python libraries syntax but with those coding assistants, I can just focus on the business logic and let the machine do the coding. I think that’s good news for business users.