TL;DR
Using materialized view to create a different sort order of the base table can reduce cost substantially, in this example up to 200 X for some queries.
The Problem : You can’t have multiple sort order.
One of most effective technique in columnar database to improve speed is to sort the table which will help the engine scan less data, but what if you have some queries that works better with different sorting, obviously you can’t have independent column sorted in the same table , turn out BigQuery has a very nice functionality, Materialized views which are used mainly to aggregate Data, see example here, can also works fine without aggregation and you can even change the sort order of the base table.
Example using PowerBI
In this report, which show analyze Electricity production for the Australian Market, the base table is sorted by day, that make perfect sense as most uses will want to see only a specific time period then aggregate by some attribute like region, technology etc
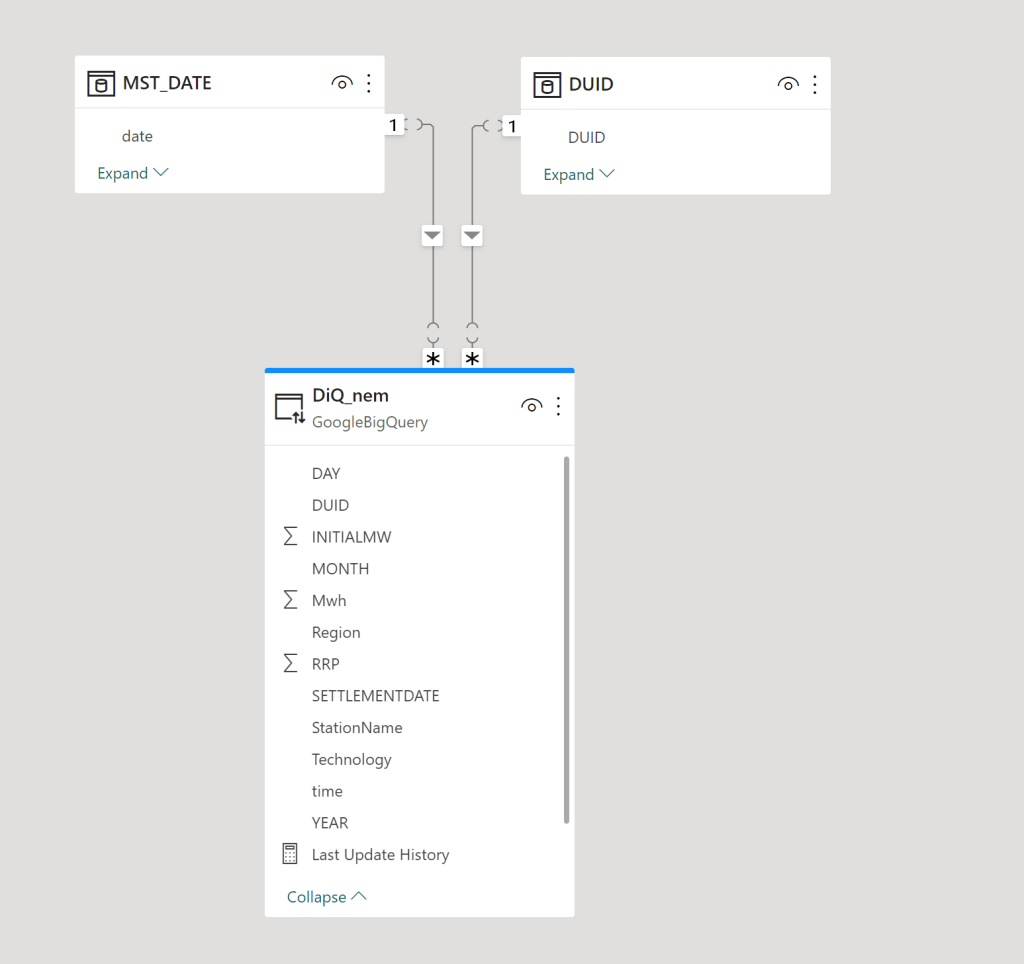
The Model is very simple , a fact table in Direct Query mode, and two dimensions in Import mode, a very simple star schema
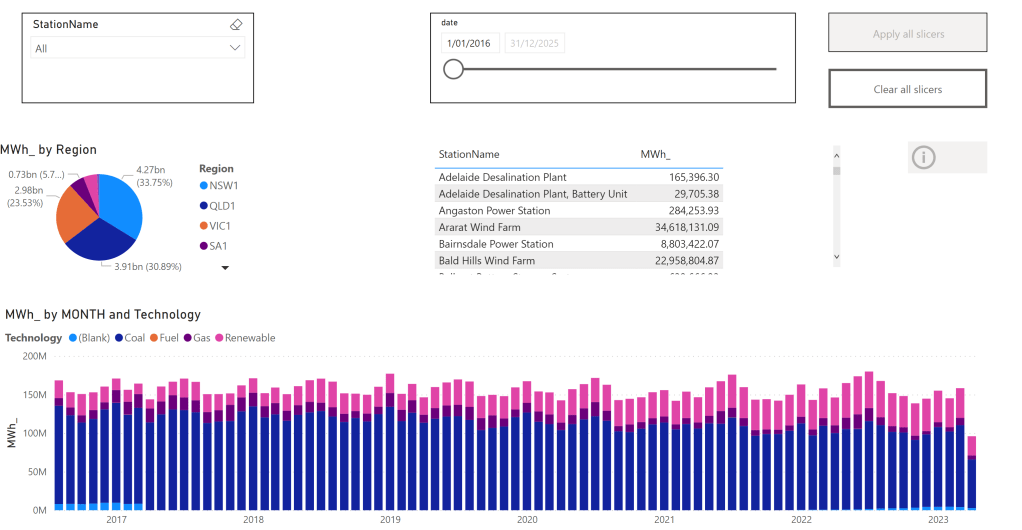
The main report is a couple of charts using some aggregation, nothing particularly interesting, the queries use the Materialized view as we are aggregating per day, the base table is by minutes.
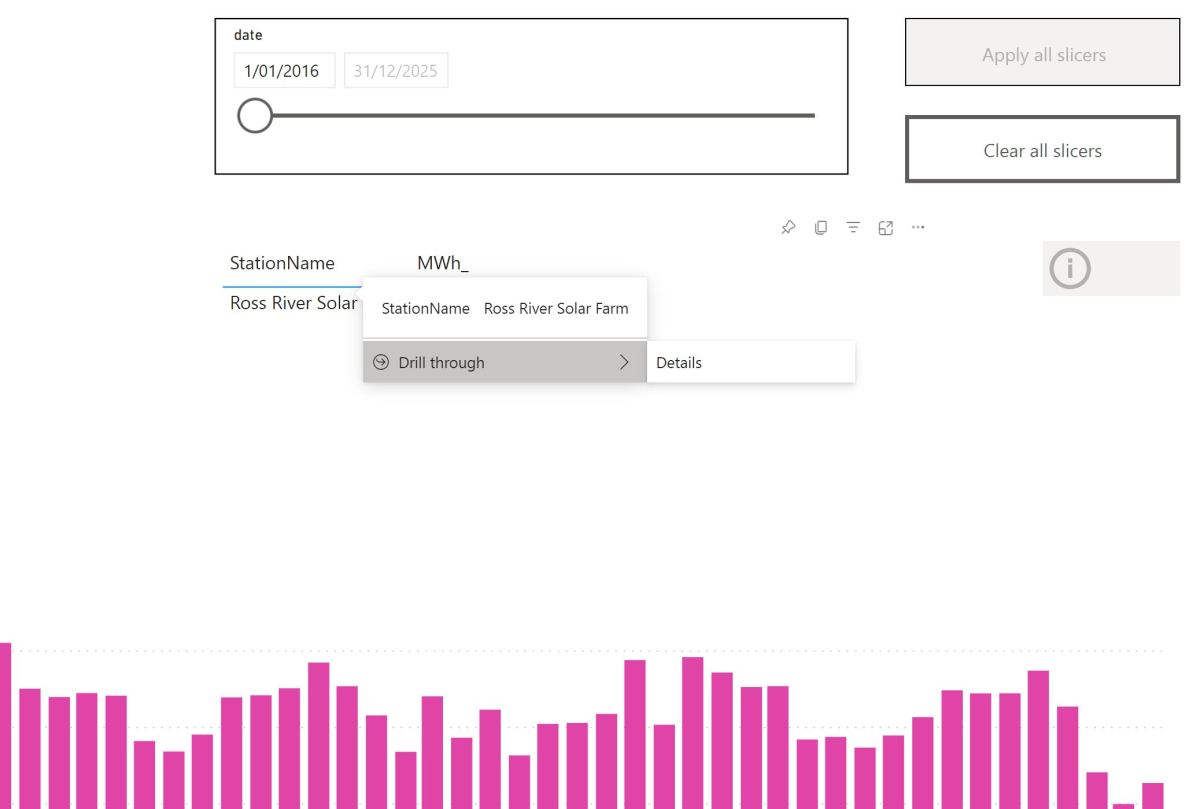
Drill Down to details
The trouble start here, let’s say a user want to see all the data for one particular Station name to the lowest level of details.
The Engine will have to scan the full table, as the table was sorted by date not by Station name
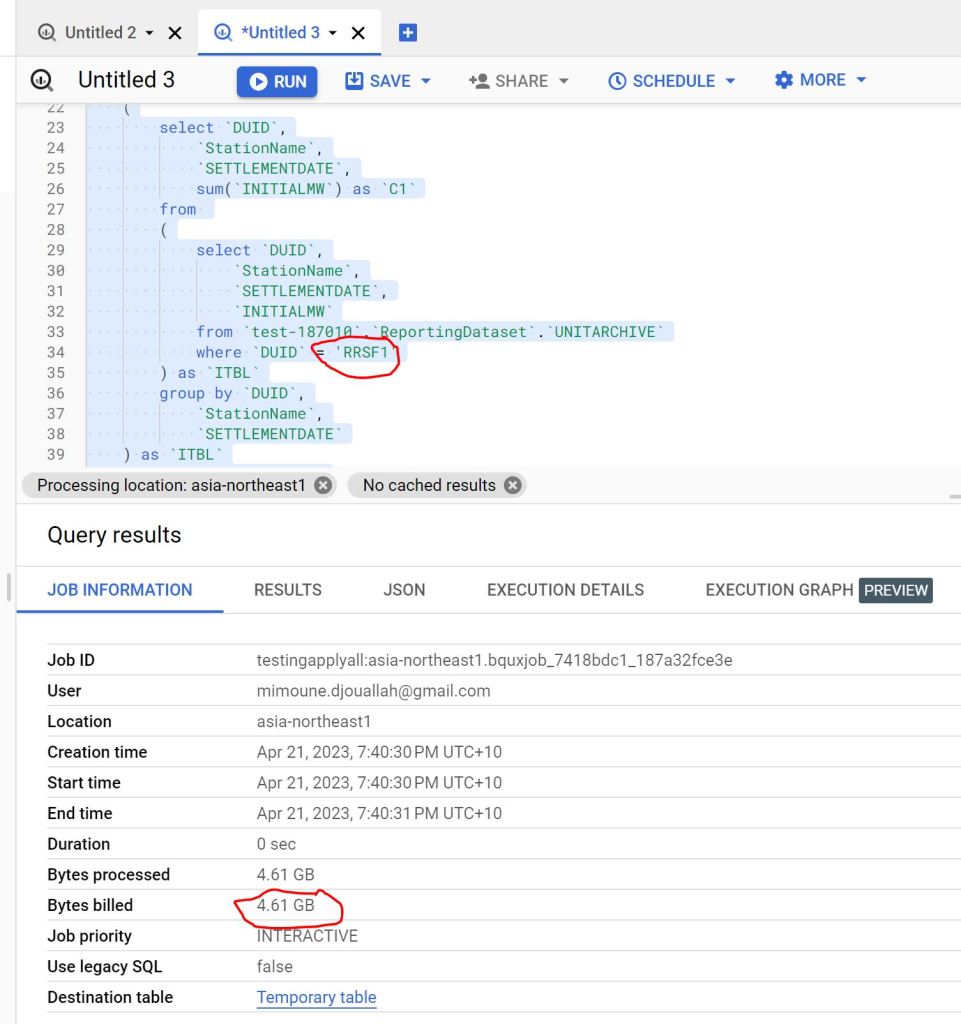
as you can see 4.61 GB is a lot of data scanned just to see one station name.
Non Aggregation Materialized View
let’s create a new MV with a different sort order, notice there is no group by, it is the same number of rows as the base table and you can’t have different partitions, only sort can be changed.
create materialized view `XXX_MV_Sort` cluster by DUID,DAY as SELECT * FROM BASE_Table
The Same Query is substantially cheaper 🙂 from 4.6 GB to 19 MB, that’s 230 times cheaper.
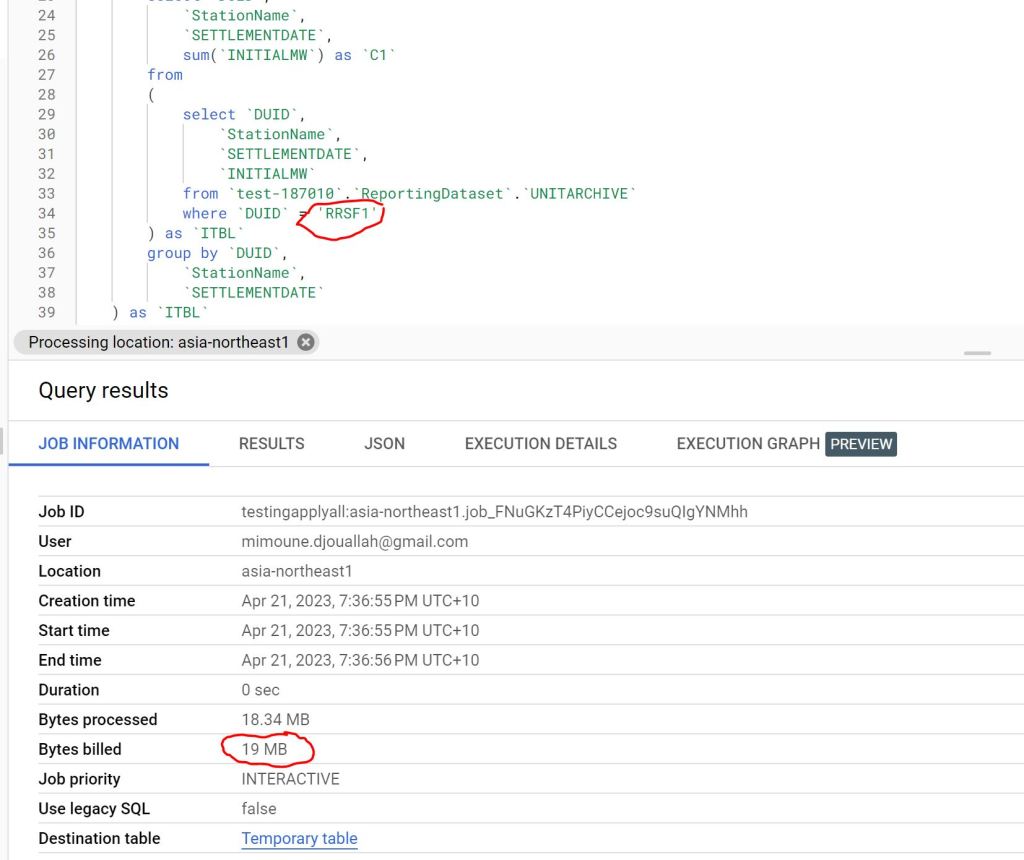
you can see the two Query Plan, one scanning 101 Millions rows vs 404000 rows

Take away
Because BigQuery already knows about all the queries, it may be useful to have some kind of service that give suggestions, like changing sort or adding a Materialized view, in the meantime, I think Modeling still matter and can save you a lot of money.
