
TL;DR :
in a previous blog, I did benchmark some database using TPCH-SF100, one of the main complaint was that the data was originally from snowflake although I did rewrite the parquet files using DuckDB, it did not feel right as Snowflake performance using the lowest tier was exceptionally good, in this blog, I am using Data generated independently, and yes Snowflake is very fast.
Reproducibility
Since that blog, DuckDB released a new update where you can generate any TPCH data using low resource computer (like my laptop), I thought it is a good opportunity to validate the previous results, this time though, I published the full pipeline so, it can be reproduced independently.
I used the following steps
- Generate the dataset in my laptop using this code
- Upload the parquet files to an Azure storage, the total size of the parquet files is 38 GB
- Create an external tables in Snowflake, using this SQL script
- Import the data from Azure Storage to Snowflake native table using create table as select from external table, the import took around 10 minutes ( that was rather slow to be honest), the data is imported as it is, no sorting, and no table distribution shenanigans.
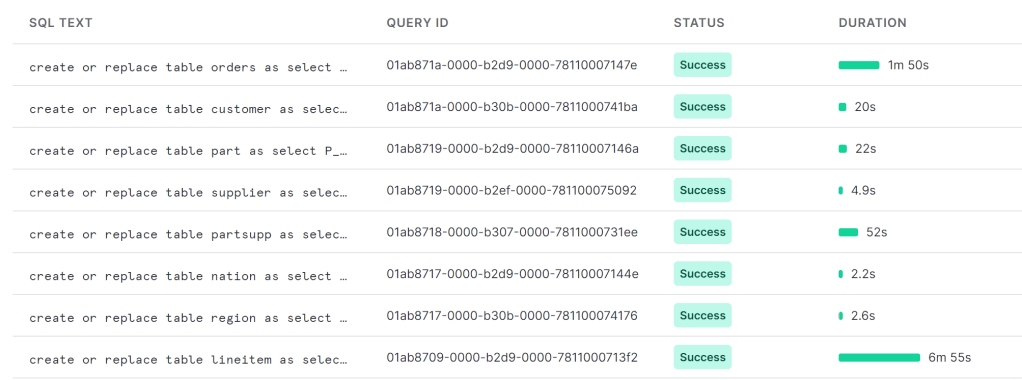
- I did noticed Snowflake has a better compression ratio than Parquet, for example the table “lineitem” size in Parquet is 25 GB, in Snowflake file format is 13.8 GB
- Run TPCH benchmarks 2 times then do it again 1 hour later (I wanted to be sure that the disk cache was expired) obviously keeping the result cache off
The Results
Run 1 and 3 are querying data directly from Azure Storage you can see that from the local disk cache in Query 1, subsequent Queries use the data cached in the local SSD, notice the cache is temporary, if you suspend your Compute, you may lose it, Although Snowflake tries to give you back the same VM if available.
I plotted the results in PowerBI using the Query history table, The numbers are impressive, I think it is the combination of excellent features working together, great compression, extreme pruning, great Query plan, exact statistics, the whole thing make an extremely efficient engine.

Take away
Database performance is a very complex subject and vary based on the workload, but I wanted to have a simple heuristic, a number that I can reference, I think I have that magic Number 🙂 if your Database can Run TPCH-SF100 around 2 minutes and cost you around 2 $, you can say it is fast.
