I recently had a conversation about this topic and realized that it’s not widely known that Snowflake can read Delta tables hosted in OneLake. So, I thought I’d share this in a blog post.
Fundamentally, this process is similar to how XTable in Fabric works, but in reverse—it converts a Delta table to Iceberg by translating the table metadata ( AFAIK, Snowflake don’t use Xtable but an internal tool)

Recommended Documentation
For detailed information, I strongly recommend reading the official Snowflake documentation:
🔗 Create Iceberg Table from Delta
How It Works
External Volume and File Section
When creating an external volume in Snowflake that points to OneLake, only the Files section is supported. This isn’t an issue because you can simply add a shortcut that points to a schema.

SQL Code to Set Up External Volume and Map an Existing Table
CREATE OR REPLACE EXTERNAL VOLUME onelake_personal_tenant_delta
STORAGE_LOCATIONS =
(
(
NAME = 'onelake_personal_tenant_delta',
STORAGE_PROVIDER = 'AZURE',
STORAGE_BASE_URL = 'azure://onelake.dfs.fabric.microsoft.com/python/data.Lakehouse/Files',
AZURE_TENANT_ID = 'xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx'
)
);
DESC EXTERNAL VOLUME onelake_personal_tenant_delta;
One-Time Setup: Authentication
You’ll need to complete a one-time authentication step:
- Copy the AZURE_CONSENT_URL from the output.
- Open it in your browser:
"AZURE_CONSENT_URL":"https://login.microsoftonline.com/xx/oauth2/authorize?client_id=yy&response_type=code" - Ensure you select the correct email address that has access to your tenant.
- This will create an Azure multi-tenant app with a service principal.
- Add this service principal to your workspace so that Snowflake can access the data.
Setting Up the Iceberg Table
CREATE OR REPLACE CATALOG INTEGRATION delta_catalog_integration
CATALOG_SOURCE = OBJECT_STORE
TABLE_FORMAT = DELTA
ENABLED = TRUE;
CREATE DATABASE IF NOT EXISTS ONELAKE;
CREATE SCHEMA IF NOT EXISTS delta;
CREATE ICEBERG TABLE ONELAKE.delta.test
CATALOG='delta_catalog_integration'
EXTERNAL_VOLUME = 'onelake_personal_tenant_delta'
BASE_LOCATION = 'aemo/test/';
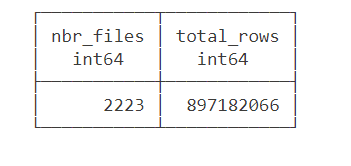
SELECT COUNT(*) FROM ONELAKE.delta.test;
and here is the result

Limitations
- Deletion Vectors Are Not Supported:
If your table contains deletion vectors, make sure to runOPTIMIZEto handle them properly.