
Note: The blog and especially the code were written with the assistance of an LLM.
TL;DR
I built a simple Fabric Python notebook to orchestrate sequential SQL transformation tasks in OneLake using DuckDB and delta-rs. It handles task order, stops on failure, fetches SQL from external sources (like GitHub or a Onelake folder), manages Delta Lake writes, and uses Arrow recordbacth for efficient data transfer, even for large datasets. This approach helps separate SQL logic from Python code and simulates external table behavior in DuckDB. Check out the code on GitHub: https://github.com/djouallah/duckrun
pip install duckrunIntroduction
Inspired by tools like dbt and sqlmesh, I started thinking about building a simple SQL orchestrator directly within a Python notebook. I was showing a colleague a Fabric notebook doing a non-trivial transformation, and although it worked perfectly, I noticed that the SQL logic and Python code were mixed together – clear to me, but spaghetti code to anyone else. With Fabric’s release of the user data function, I saw the perfect opportunity to restructure my workflow:
- Data ingestion using a User-Defined Function (UDF), which runs in a separate workspace.
- Data transformation in another workspace, reading data from the ingestion workspace as read-only.
- All transformations are done in pure SQL, there 8 tables, every table has a sql file, I used DuckDB, but feel free to use anything else that understands SQL and output arrow (datafusion, chdb, etc).
- Built Python code to orchestrate the transformation steps.
- PowerBI reports are in another workspace
I think this is much easier to present 🙂
I did try yato, which is a very interesting orchestrator, but it does not support parquet materialization
How It Works
The logic is pretty simple, inspired by the need for reliable steps:
- Your Task List: You provide the function with a list (tasks_list). Each item has table_name (same SQL filename, table_name.sql) and how to materilize the data in OneLake (‘append’ , ‘overwrite’,ignore and None)
- Going Down the List: The function loops through your tasks_list, taking one task at a time.
- Checking Progress: It keeps track of whether the last task worked out using a flag (like previous_task_successful). This flag starts optimistically as True.
- Do or Don’t: Before tackling the current task, it checks that flag.
- If the flag is True, it retrieves the table_name and mode from the current task entry and passes them to another function, likely called run_sql. This function performs the actual work of running your transformation SQL and writing to OneLake.
- If the flag is False, it knows something went wrong earlier, prints a quick “skipping” message, and importantly, uses a break statement to exit the loop immediately. No more tasks are run after a failure.
- Updating the Status: After run_sql finishes, run_sql_sequence checks if run_sql returned 1 (our signal for success). If it returns 1, the previous_task_successful flag stays True. If not, the flag flips to False.
- Wrap Up: When the loop is done (either having completed all tasks or broken early), it prints a final message letting you know if everything went smoothly or if there was a hiccup.
The run_sql function is the workhorse called by run_sql_sequence. It’s responsible for fetching your actual transformation SQL (that SELECT … FROM raw_table). A neat part here is that your SQL files don’t have to live right next to your notebook; they can be stored anywhere accessible, like a GitHub repository, and the run_sql function can fetch them. It then sends the SQL to your DuckDB connection and handles the writing part to your target OneLake table using write_deltalake for those specific modes. It also includes basic error checks built in for file reading, network stuff, and database errors, returning 1 if it succeeds and something else if it doesn’t.
You’ll notice the line con.sql(f””” CREATE or replace SECRET onelake … “””) inside run_sql; this is intentionally placed there to ensure a fresh access token for OneLake is obtained with every call, as these tokens typically have a limited validity period (around 1 hour), keeping your connection authorized throughout the sequence.
When using the overwrite mode, you might notice a line that drops DuckDB view (con.sql(f’drop VIEW if exists {table_name}’)). This is done because while DuckDB can query the latest state of the Delta Lake files, the view definition in the current session needs to be refreshed after the underlying data is completely replaced by write_deltalake in overwrite mode. Dropping and recreating the view ensures that subsequent queries against this view name correctly point to the newly overwritten data.
The reason we do this kind of hacks is, duckdb does not support external table yet, so we are just simulating the same behavior by combining duckdb and delta rs, spark obviousely has native support
Handling Materialization in Python
One design choice here is handling the materialization strategy (whether to overwrite or append data) within the Python code (run_sql function) rather than embedding that logic directly into the SQL scripts.
Why do it this way?
Consider a table like summary. You might have a nightly job that completely recalculates and overwrites the summary table, but an intraday job that just appends the latest data. If the overwrite or append command was inside the SQL script itself, you’d need two separate SQL files for the exact same transformation logic – one with CREATE OR REPLACE TABLE … AS SELECT … and another with INSERT INTO … SELECT ….
By keeping the materialization mode in the Python run_sql function and passing it to write_deltalake, you can use the same core SQL transformation script for the summary table in both your nightly and intraday pipelines. The Python code dictates how the results of that SQL query are written to the Delta Lake table in OneLake. This keeps your SQL scripts cleaner, more focused on the transformation logic itself, and allows for greater flexibility in how you materialize the results depending on the context of your pipeline run.
Efficient Data Transfer with Arrow Record batch
A key efficiency point is how data moves from DuckDB to Delta Lake. When DuckDB executes the transformation SQL, it returns the results as an Apache Arrow RecordBatch. Arrow’s columnar format is highly efficient for analytical processing. Since both DuckDB and the deltalake library understand Arrow, data transfers with minimal overhead. This “zero-copy” capability is especially powerful for handling datasets larger than your notebook’s available RAM, allowing write_deltalake to process and write data efficiently without loading everything into memory at once.
Example:
you pass Onelake location, schema and the number of files before doing any compaction

first it will load all the existing Delta table

Here’s an example showing how you might define and run different task lists for different scenarios:
sql_tasks_to_run_nightly = [
['price', 'append'],
['scada', 'append'],
['duid', 'ignore'],
['summary', 'overwrite'], # Overwrite summary nightly
['calendar', 'ignore'],
['mstdatetime', 'ignore'],
]
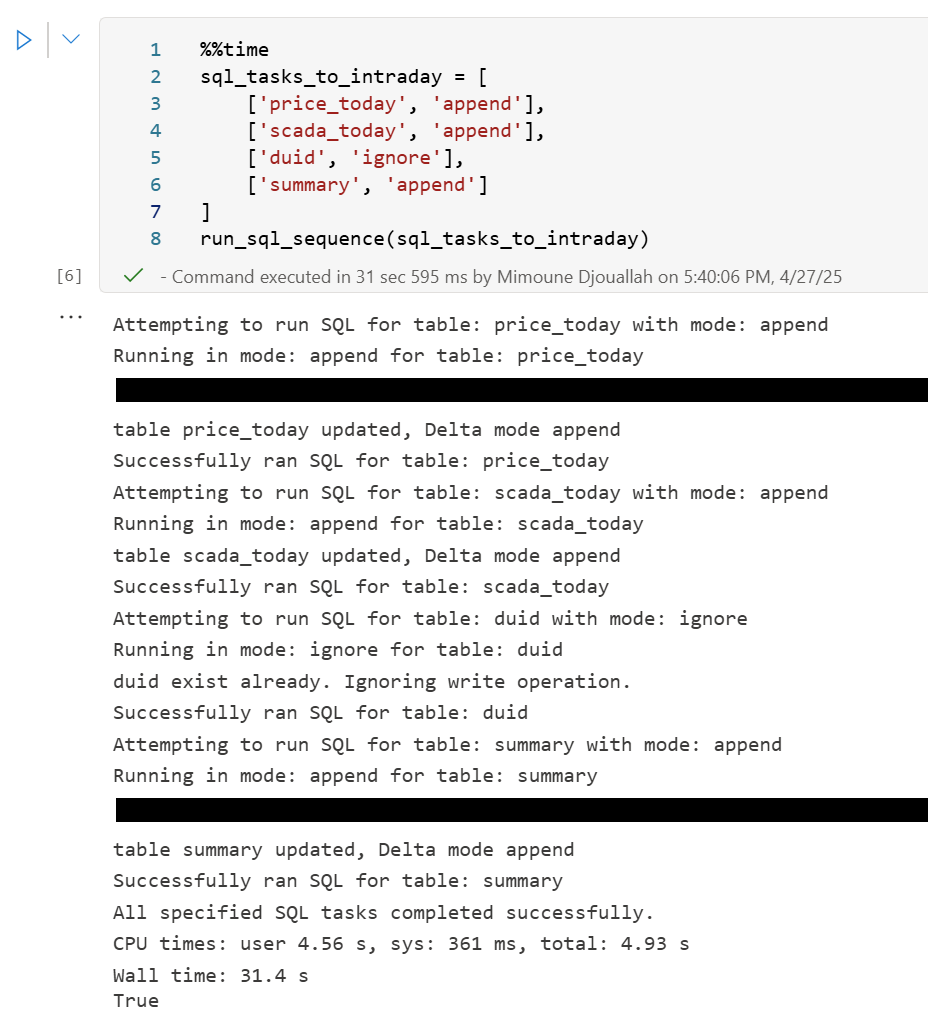
sql_tasks_to_intraday = [
['price_today', 'append'],
['scada_today', 'append'],
['duid', 'ignore'],
['summary', 'append'] # Append to summary intraday using the *same* SQL script
]
You can then use Python logic to decide which pipeline to run based on conditions, like the time of day:
start = time(4, 0)
end = time(5, 30)
if start <= now_brisbane <= end:
run_sql_sequence(sql_tasks_to_run_nightly)Here’s an example of an error I encountered during a run, it will automatically stop the remaining tasks:
Attempting to run SQL for table: price_today with mode: append
Running in mode: append for table: price_today
Error writing to delta table price_today in mode append: Parser Error: read_csv cannot take NULL list as parameter
Error updating data or creating view in append mode for price_today: Parser Error: read_csv cannot take NULL list as parameter
Failed to run SQL for table: price_today. Stopping sequence.
One or more SQL tasks failed.
here is some screenshots from actual runs
as it is a delta table, I can use SQL endpoints to get some stats
For example the table scada has nearly 300 Million rows, the raw data is around 1 billion of gz.csv

It took nearly 50 minutes to process using 2 cpu and 16 GB of RAM, notice although arrow is supposed to be zero copy, writing parquet directly from Duckdb is substantially faster !!! but anyway, the fact it works at all is a miracle 🙂
in the summary table we remove empty rows and other business logic, which reduce the total size to 119 Million rows.
here is an example report using PowerBI direct lake mode, basically reading delta directly from storage

In this run, it did detect that the the night batch table has changed

Conclusion
To be clear, I am not suggesting that I did anything novel, it is a very naive orchestrator, but the point is I could not have done it before, somehow the combination of open table table format, robust query engines and an easy to use platform to run it make it possible and for that’s progress !!!
I am very bad at remembering python libraries syntax but with those coding assistants, I can just focus on the business logic and let the machine do the coding. I think that’s good news for business users.













