A couple of days ago, Thoughtspot released a new tier tailored for Small and medium enterprise, see the pricing here, The big surprise, unlimited users is a standard offering even for the entry level tier which cost 95 $/Month, yes there are some limitation, but you can add any number of users !!!!
One may ask, how they can afford it? Thoughtspot is not a charity and they have a margin to maintain !!! and why a bigger player Like Microsoft can’t do that, the hypothesis of this blog is, it is mainly an engineering problem , which bring us to the semantic Model Architecture for Both product.
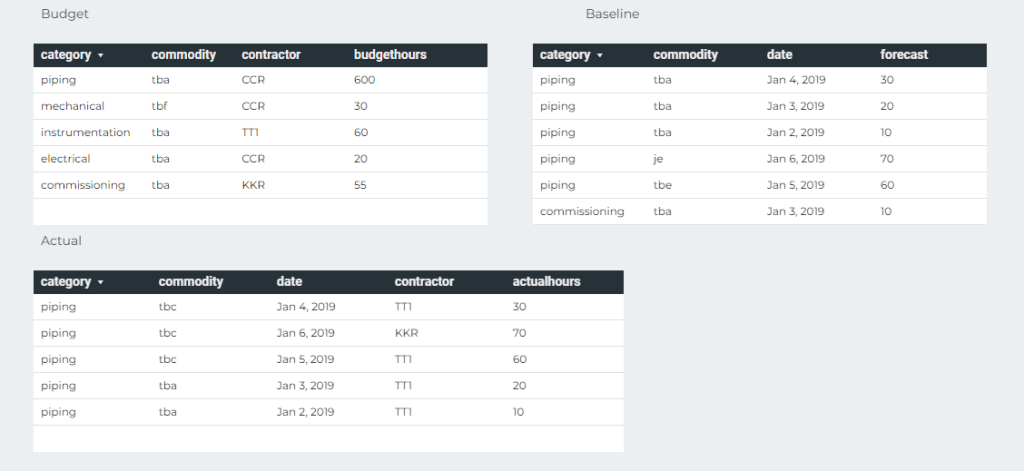
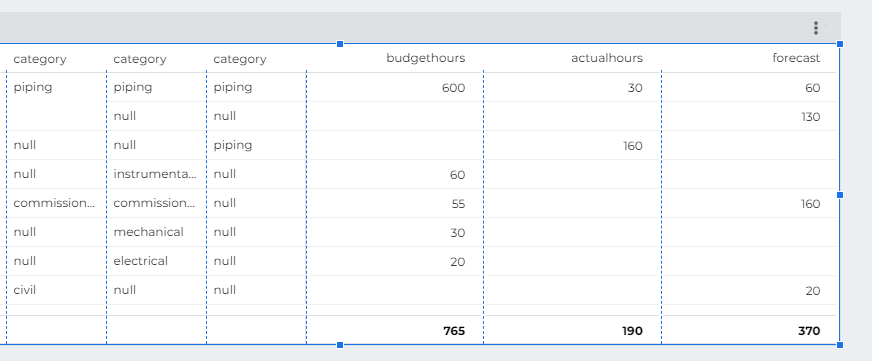
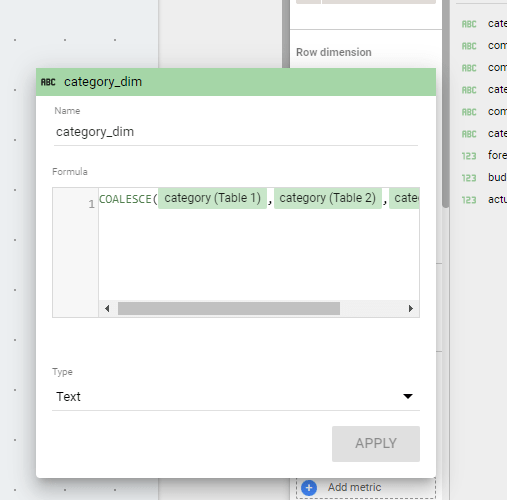
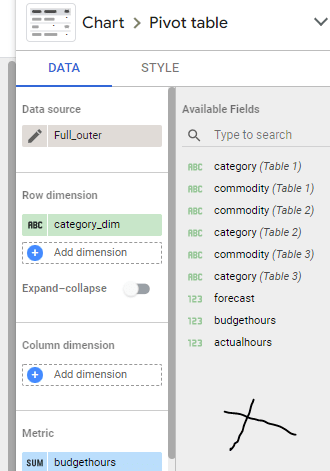
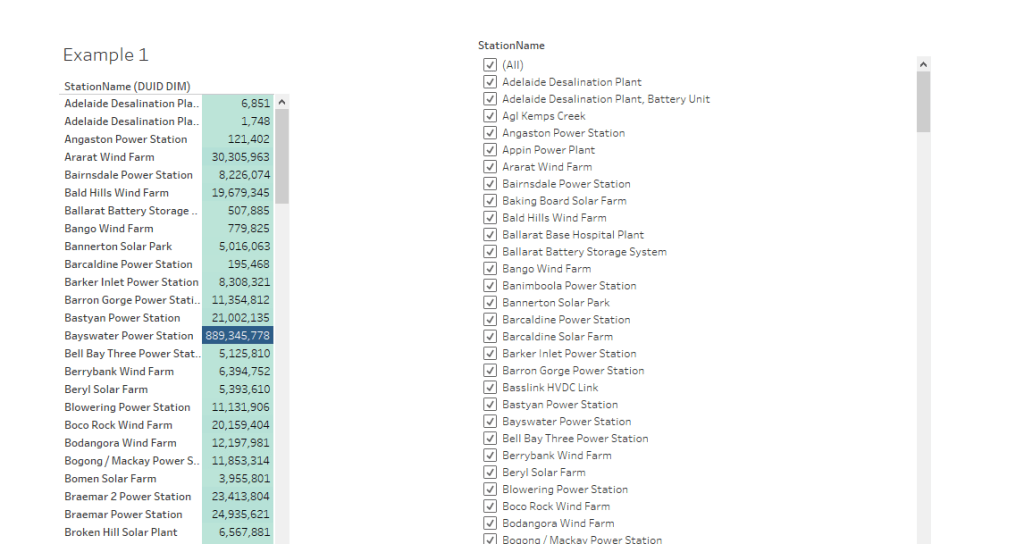
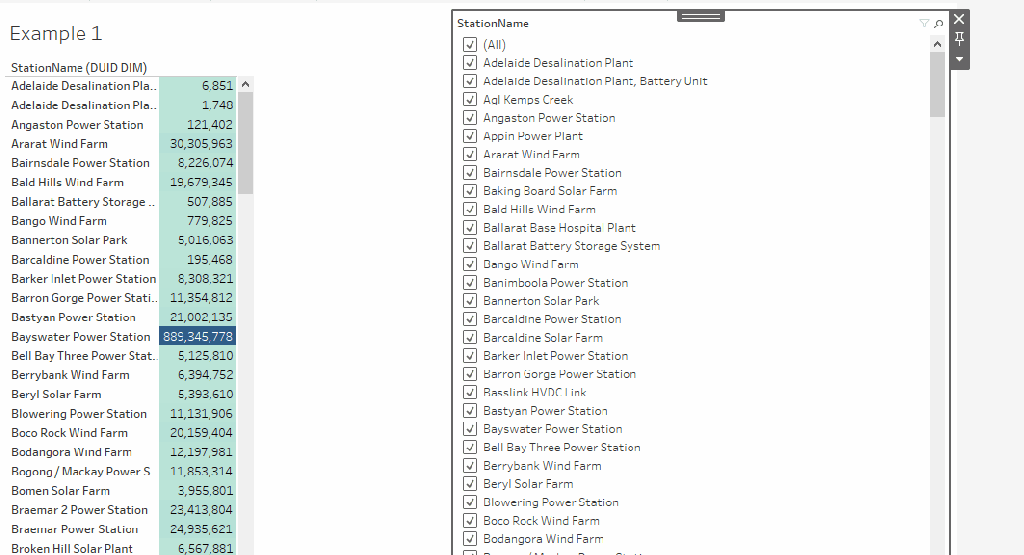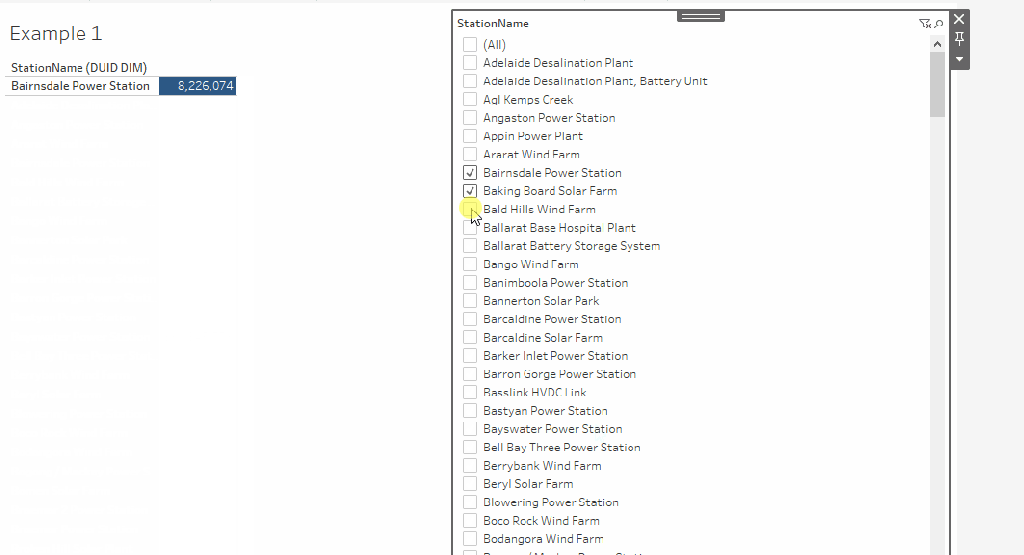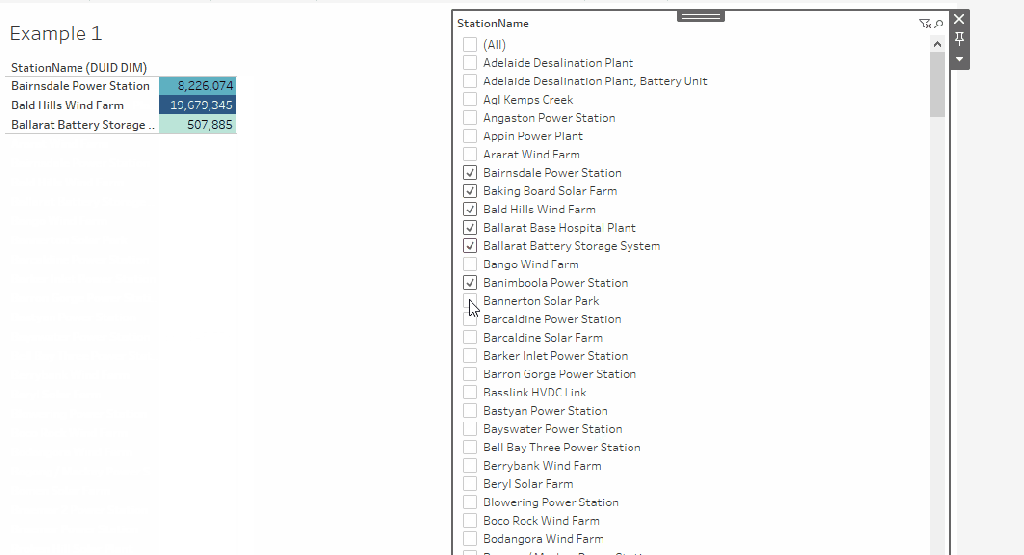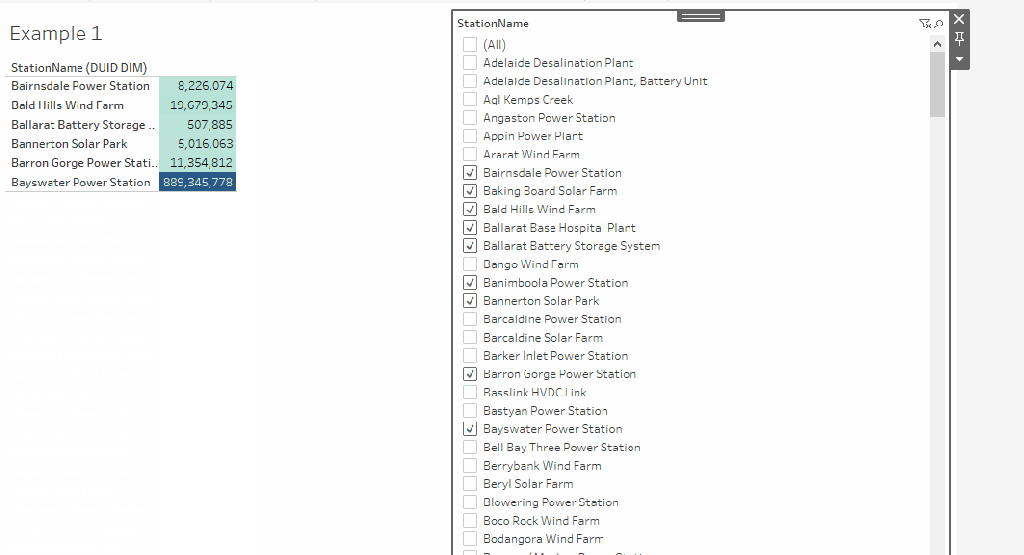
Let’s build a very simple Semantic Model in PowerBI and Thoughtspot, two fact tables with one common dimension, Both Data is hosted in BigQuery
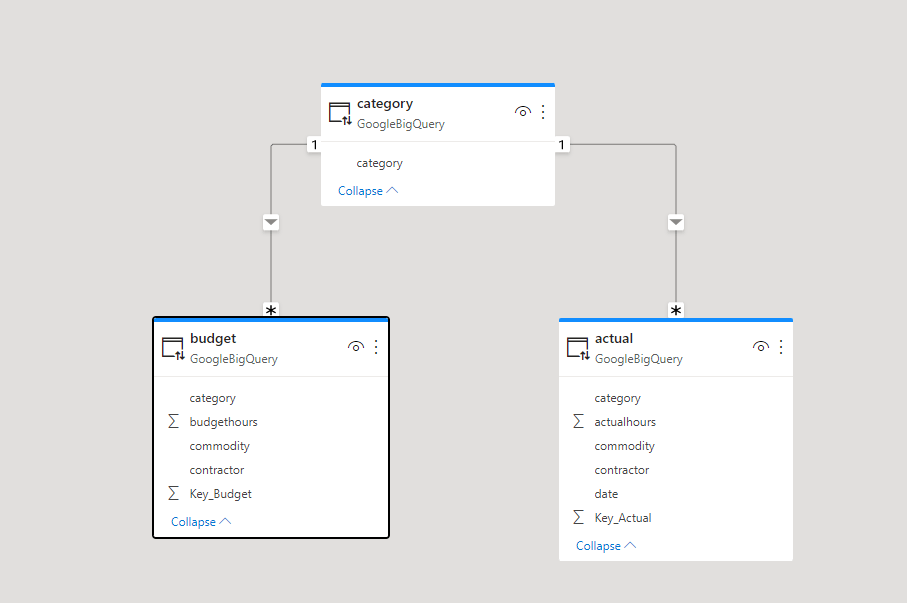
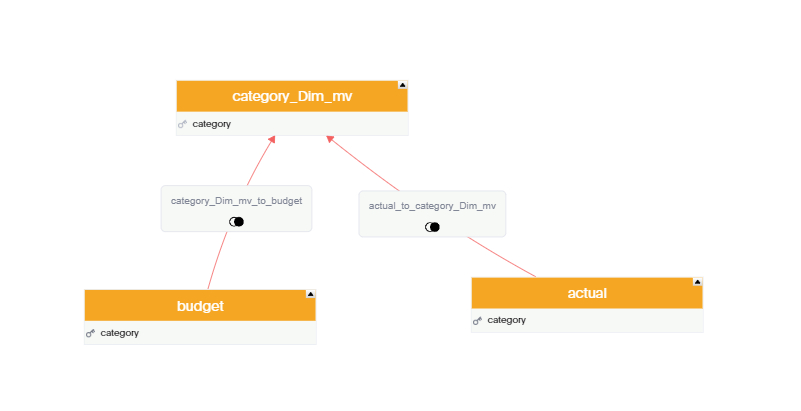
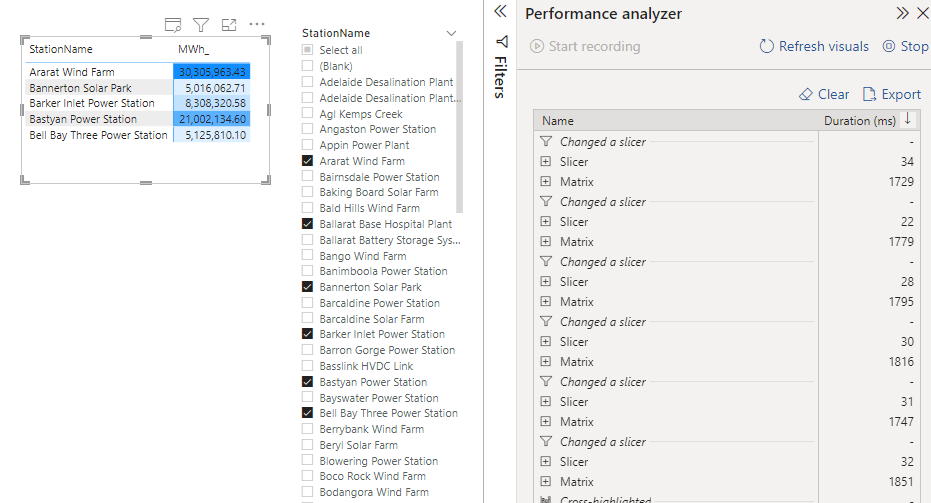
now let’s have a simple report, in both PowerBI and Thoughtspot
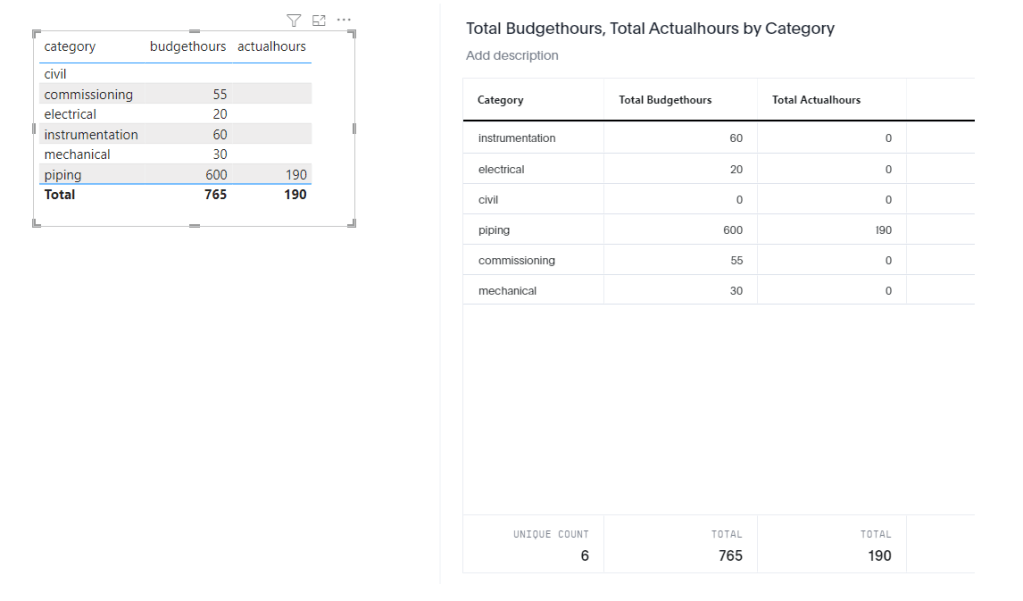
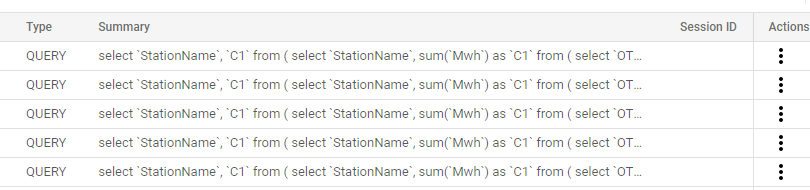
Now let’s check the Queries sent to BigQuery.
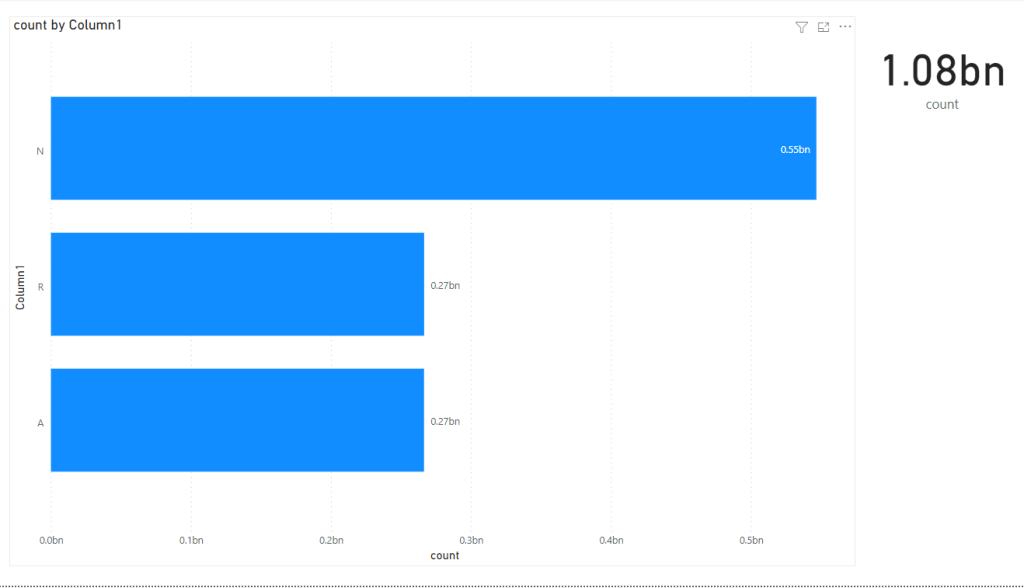
PowerBI send three Queries

Thoughtspot Send one Query that return the results exactly as the visual

Why PowerBI needs three SQL Queries ?
That’s the key Question in this Blog, PowerBI was designed to have two tiers, a first tier to scan data either from the internal Database Vertipaq ( or external DB in live more) and the second tier to do ” result merge” and more complex calculation, it is a very clever design decision as it works with less sophisticated DB, after all , all External DB needs to provide is a simple scan and inner & left join, all the complexity is handled by the Formula Engine. ( Tableau has more or less the same architecture)
Thoughtspot made different design decisions, all the calculations are done by the external Database, The “Front End” job is to generate SQL based on the relationship between tables and the definition of measures, this was made possible because Cloud Data warehouse are fast and can do complex calculation. ( I know it is more complex than that like indexing and AI stuff but that the general idea )
My speculation is Thoughtspot Semantic Model require less compute resources, which made unlimited users possible even for the small tier.
I would argue even if thoughtspot decide to add an internal Database later, it will be still cheaper as the Storage/ compute can be shared and it is separated anyway from the Logical Data Model.
To be very Clear, I have no Idea how vendors decide their pricing, but my speculation is architectural design have consequences, and paying per user pricing model is archaic, and hopefully will be history.