BigQuery team recently released a fantastic new functionality, when using BI engine, all the statistics are saved in the INFORMATION_SCHEMA.
When using BI Engine one major pain was it was not very clear why sometimes the Query is not accelerated, yes you can see the the result in the console, but it not very sustainable when you run a lot of queries.
Here is a query I use to tack the workload in a particular region
SELECT job_id, (case when bi_engine_statistics.bi_engine_mode is null then "BigQuery" else bi_engine_statistics.bi_engine_mode end) as Engine_Mode , user_email, xx.project_id, query, creation_time, start_time, cache_hit, TIMESTAMP_DIFF(end_time,start_time,MILLISECOND)/1000 AS duration, SUM(total_bytes_processed/1000000000) AS GB, SUM(total_bytes_billed/1000000000) AS GB_billed, STRING_AGG(t.message) AS reason FROM `region-asia-northeast1`.INFORMATION_SCHEMA.JOBS_BY_PROJECT xx LEFT JOIN UNNEST(bi_engine_statistics.bi_engine_reasons) AS t WHERE creation_time >= '2022-01-01' GROUP BY 1, 2, 3, 4, 5, 6, 7, 8, 9
And to make the results easy to explore, I load the query results in Google Data Studio.
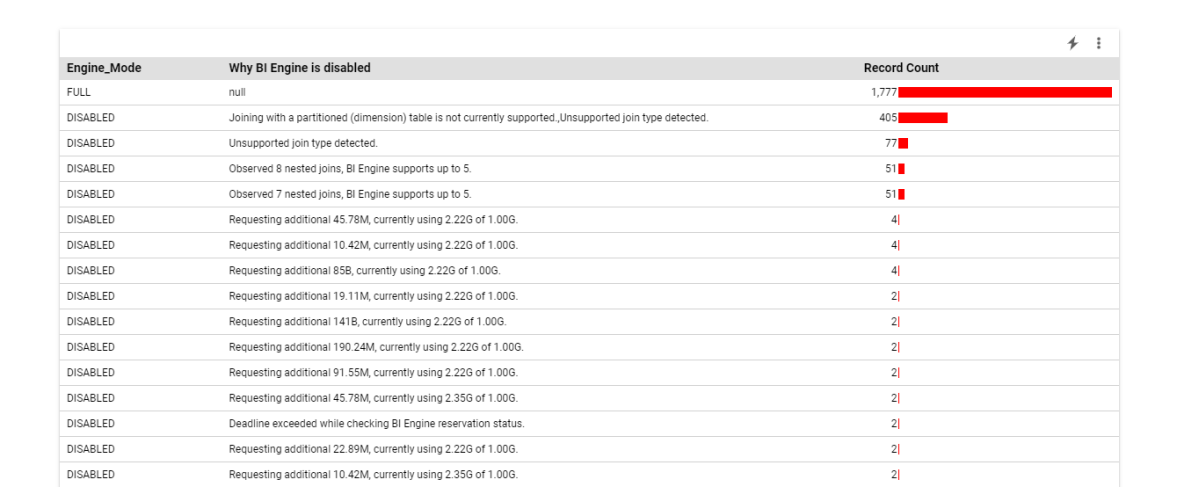
For example, I aggregate the reason why the Query was not accelerated by BI Engine
Based on the results, you can decide for a some mitigation, The Obvious one is to increase the reservation, or if you hit some current limitation of BI Engine change the Data Model.
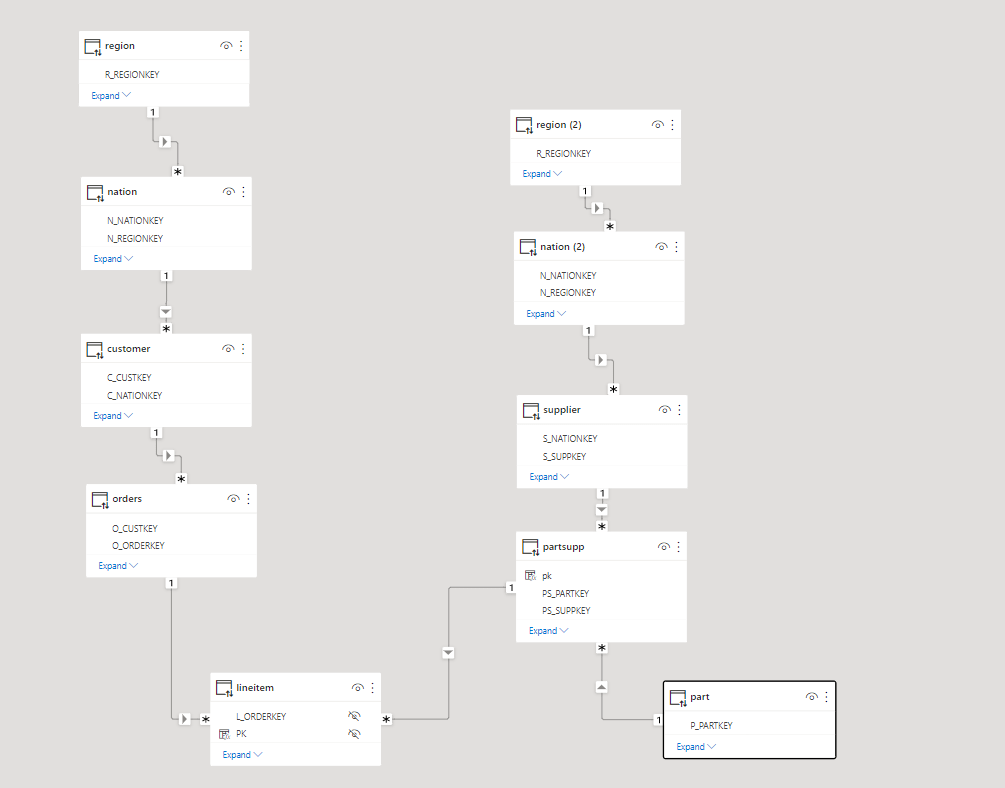
In this particular case I am using TPC-H Data Model as an example, although it is very useful for benchmark, it is not really optimized for a BI Workload, joins are expensive.
Star Schema for the Win
As of this writing ( it may change anytime though), BI Engine support a Star Schema with up to 5 unpartitioned dimension tables.
You can denormalize the tables supplier and customer by merging nation and region, and orders and lineitem to get rid of join to a partitioned table.
Alternatively if the data don’t change much, you can go rogue and Build a giant flat table.
Or use Nested Data Model, although I did find it very complex to understand just conceptually, and there are no easy to use front end tool to take advantage of it.
Usually Data Modeling can be bring some strong arguments, Star vs Flat vs Snowflake, I think it does not really matter, what is important in the Case of BigQuery, any interactive Workload has to be accelerated by BI Engine, the extra boost in speed and specially the cost is very hard to ignore, so Model any Schema you want as long as BI Engine support it.
I am keeping the stats in the public report
