While experimenting with different access modes in Power BI, I thought it is maybe worth sharing as a short blog to show why the Lakehouse architecture offers versatile options for Power BI developers. Even when they use Only Import Mode.
And Instead of sharing a conceptual piece, perhaps focus on presenting some dollar figures 🙂
Scenario: A Small Consultancy
According to local regulations, a small enterprise is defined as having fewer than 15 employees. Let’s consider this setup:
- Data Storage: The data resides in Microsoft OneLake, utilizing an F2 SKU.
- Number of Users: 15 employees.
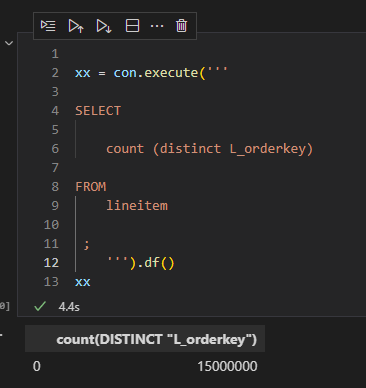
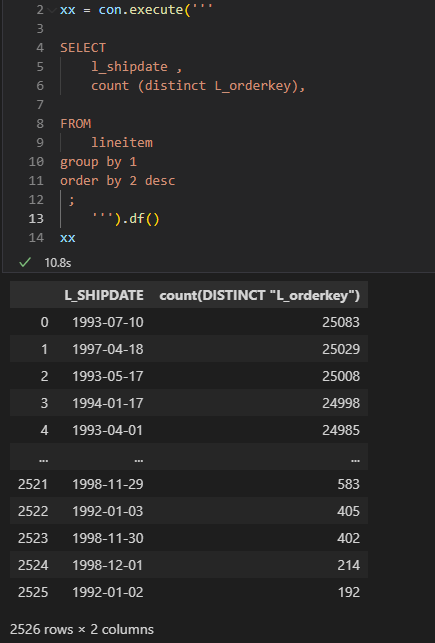
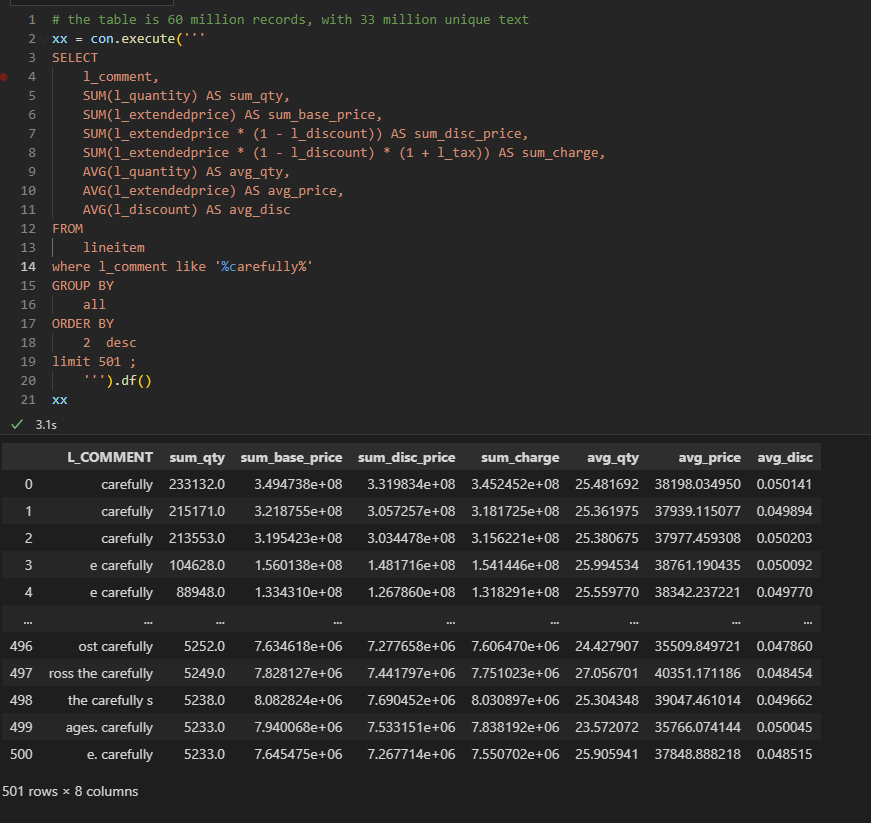
- Data Size: Approximately 94 million rows.
- Pricing Model: For simplicity, assume the F2 SKU uses a reserved pricing model.
Monthly Costs:
- Power BI Licensing: 15 users × 15 AUD = 225 AUD.
- F2 SKU Reserved Pricing: 293 AUD.
- Total Cost: 518 AUD per month.
ETL Workload
Currently, the ETL workload consumes approximately 50% of the available capacity.

For comparison, I ran the same workload on another Lakehouse vendor. To minimize costs, the schedule was adjusted to operate only from 8 AM to 6 PM. Despite this adjustment, the cost amounted to:
- Daily Cost: 40 AUD.
- Monthly Cost: 1,200 AUD.

In contrast, the F2 SKU’s reserved price of 293 AUD per month is significantly more economical. Even the pay-as-you-go model, which costs 500 AUD per month, remains competitive.
Key Insight:
While serverless billing is attractive, what matter is how much you end up paying per month.
For smaller workloads (less than 100 GB of data), data transformation becomes commoditized, and charging a premium for it is increasingly challenging.
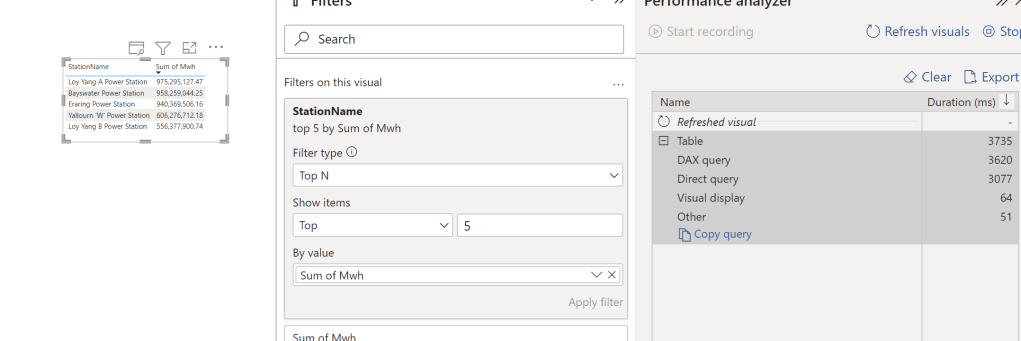
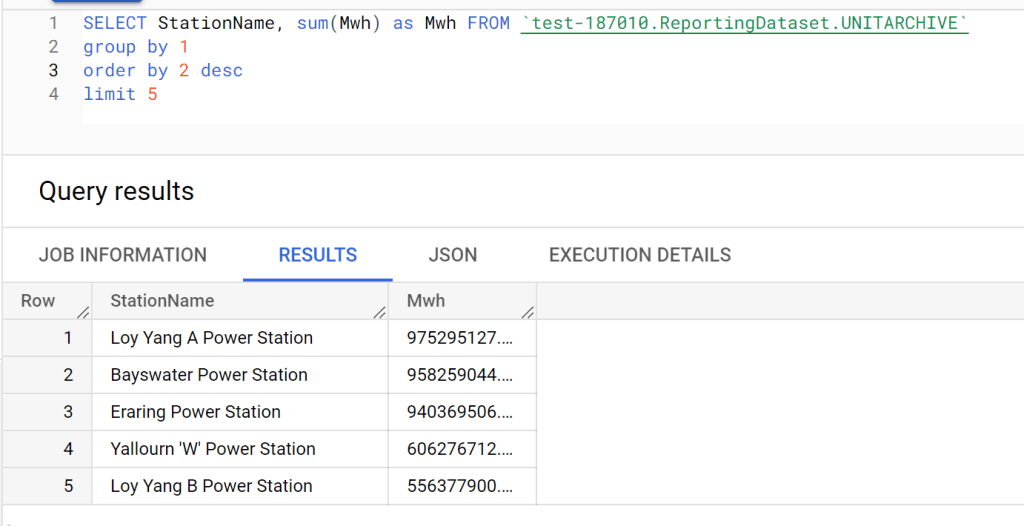
Analytics in Power BI
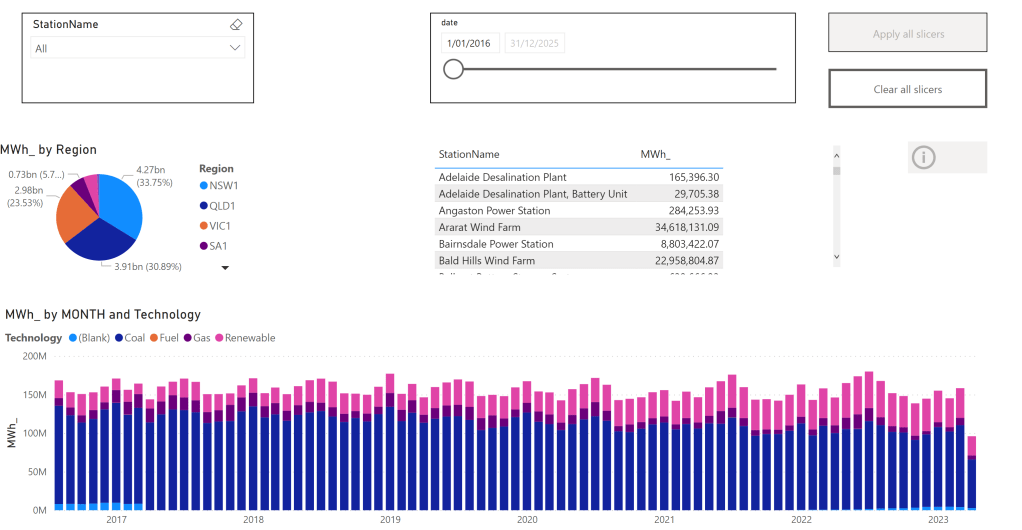
I prefer to separate Power BI reports from the workspace used for data transformation. End users care primarily about clean, well-structured tables—not the underlying complexities.
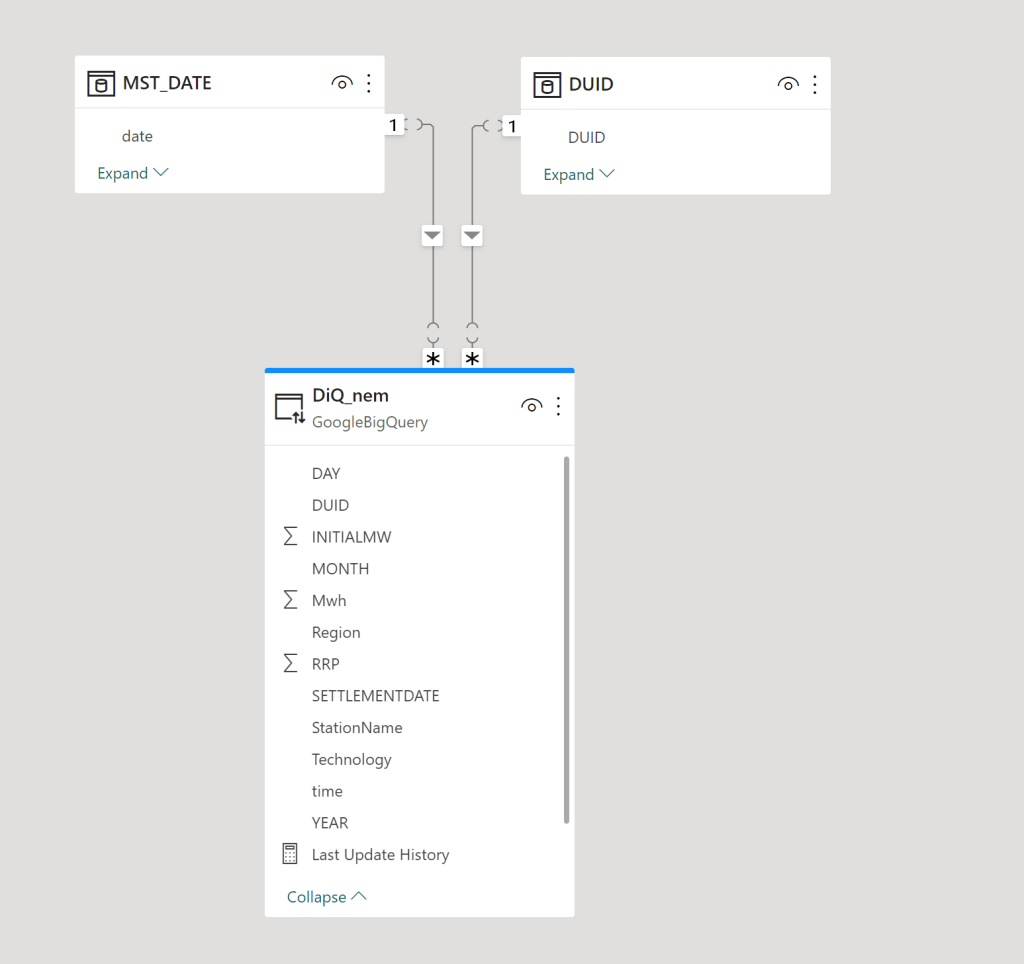
With OneLake, there are multiple ways to access the stored data:
- Import Mode: Directly import data from OneLake.
- DirectQuery: Use the Fabric SQL Endpoint for querying.
- Direct Lake Model: Access data with minimal latency.
- Composite Models: All the above ( this is me trying to be funny)
All the Semantic Models and reports are hosted in the Pro license workspace, Notice that an import model works even when the capacity is suspended ( if you are using pay as you go pricing)

The Trade-Off Triangle

In analytical databases, including Power BI, there is always a trade-off between cost, freshness, and query latency. Here’s a breakdown:
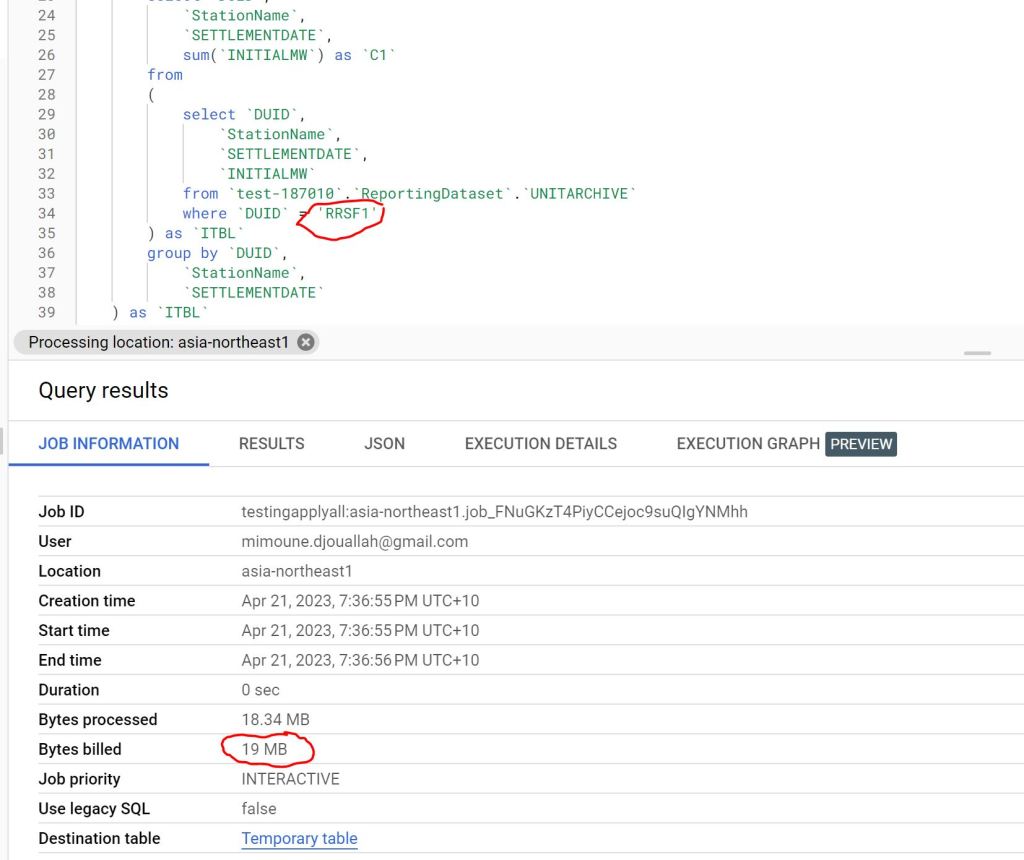
- Import Mode: Ideal if eight refreshes per day suffice and the model size is small. Reports won’t consume Fabric capacity (Onelake Transactions cost are insignificant for small data import)
- Direct Lake Model: Provides excellent freshness and latency but will probably impacts F2 capacity, in other words, it will cost more.
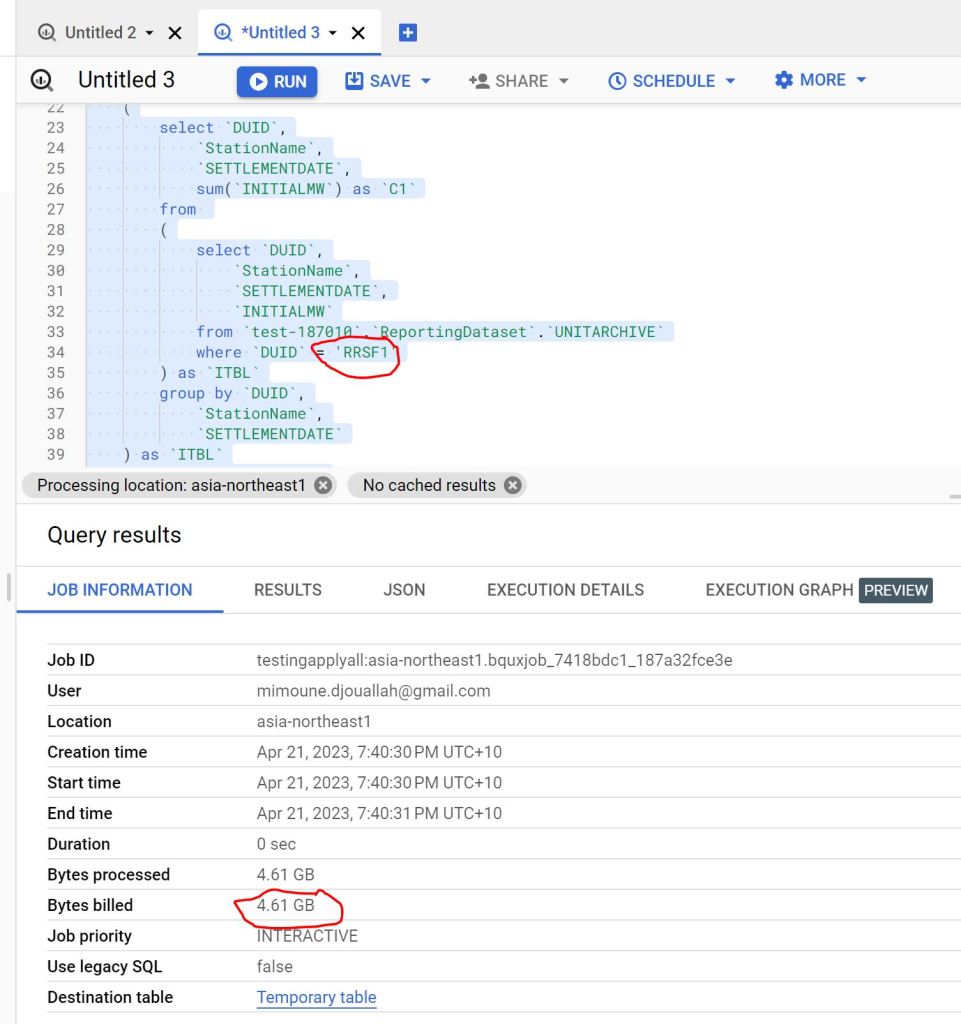
- DirectQuery: Balances freshness and latency (seconds rather than milliseconds) while consuming less capacity. This approach is particularly efficient as Fabric treats those Queries as background operations, with low consumption rates in many cases. Looking forward to the release of Fabric DWH result cache.
Key Takeaways
- Cost-Effectiveness: Reserved pricing for smaller Fabric F SKUs combined with Power BI Pro license offers a compelling value proposition for small enterprises.
- Versatility: OneLake provides flexible options for ETL workflows, even when using import mode exclusively.
The Lakehouse architecture and Power BI’s diverse access modes make it possible to efficiently handle analytics, even for smaller enterprises with limited budgets.