was listening to this Excellent Podcast about Minerva, basically Airbnb went and built a Metrics Store which is a central tool that hold all Measures and dimensions, the idea is to have one source of truth.
The Podcast is very insightful and worth listening to, But I was very surprised that none of the participants mentioned how existent BI vendors tried to solve the same Problem ,they talked Quickly about LookML but as far as I know it is not available yet for third party tools
Metrics Store is not new, it is just another name for Semantic Model, Business Objects had one from 30 years ago.
So Just for fun, and I am not sure if it is even practical, I wanted to test if PowerBI can act like a pure Metrics Store for third party tools.
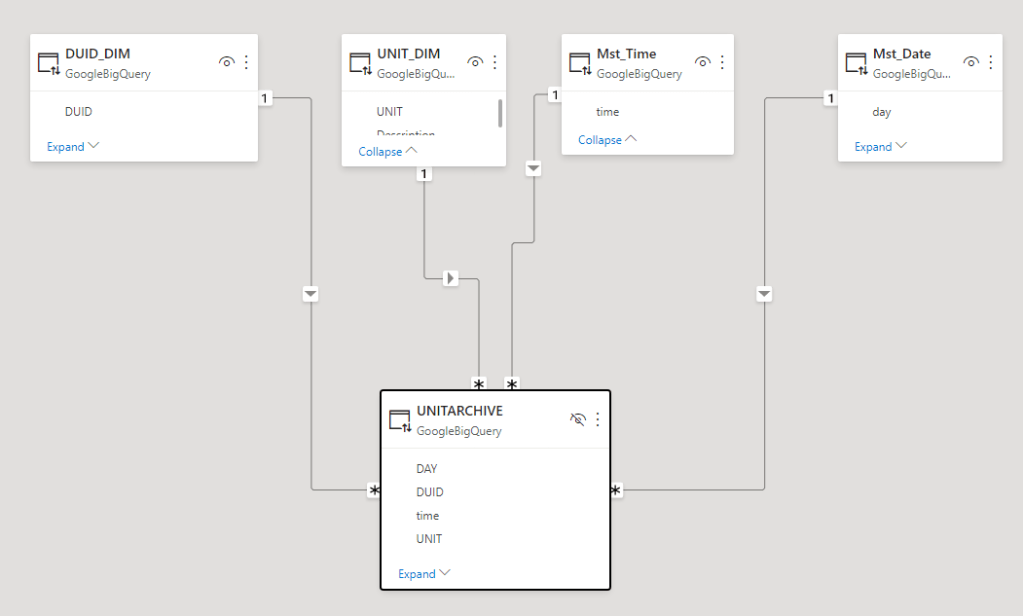
I am using BigQuery as a data source, 1 fact table 80 Million records and 5 dimension Tables all using Direct Query Mode, PowerBI is not holding any data, all it does , it receive Queries from the Viz tool in this case Excel and Tableau and translated it to SQL and serve the results back.
I publish the Model to PowerBI service, here is the catch it has to be Premium workspace, Premium per user works too
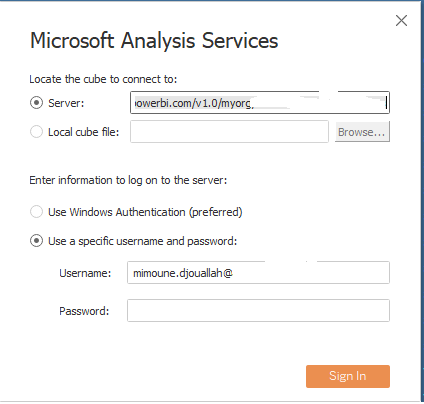
now Using Tableau, I connect to SSAS, I get the server address from Workspace setting, notice PowerBI and SSAS are using the same engine.
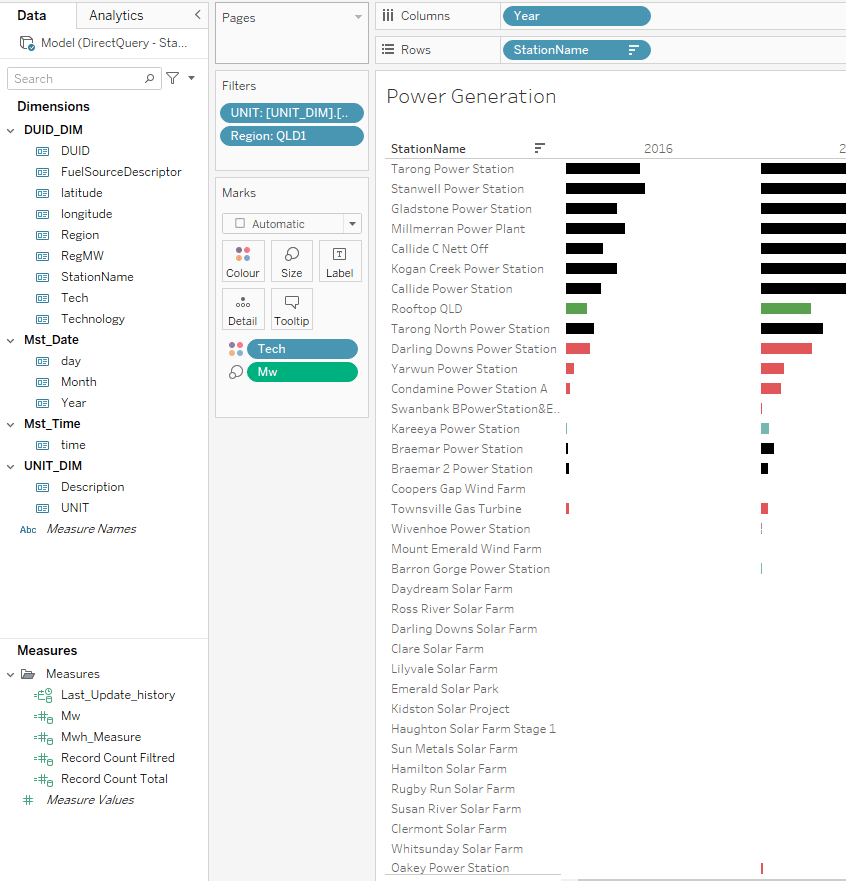
and Voila Tableau Indeed Work just fine
now trying Excel
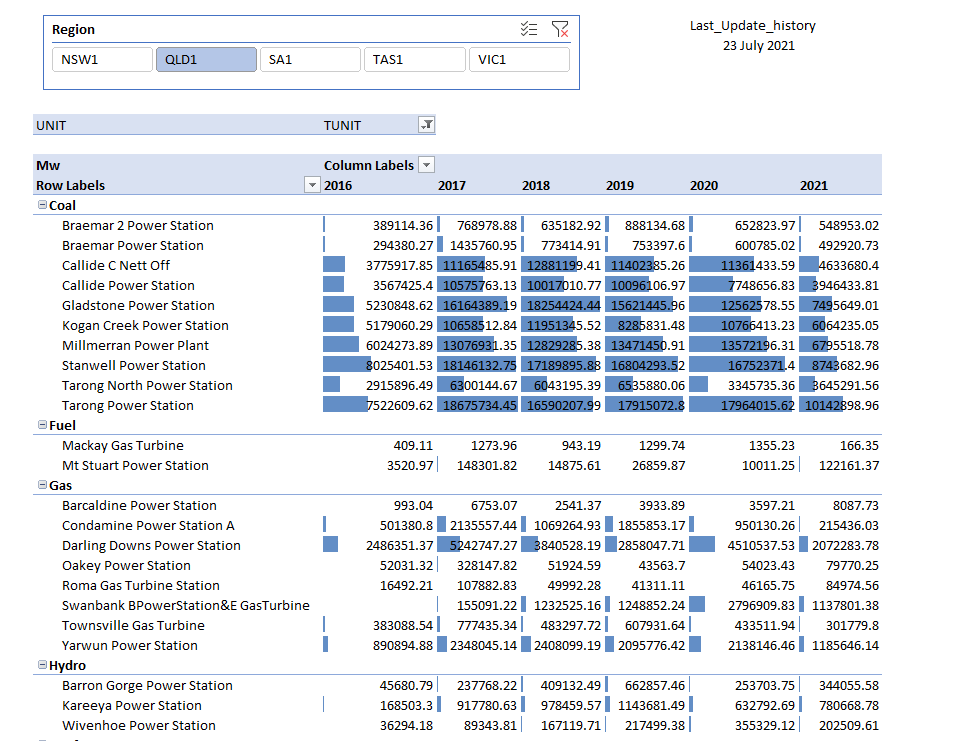
and here the SQL Queries generated by PowerBI
Notice here Tableau/Excel talk to PBI Semantic Model using MDX, which you can see here using DAX Studio where I can capture all the Queries coming to PBI
The Performance is not great but tolerable I guess, MDX Queries render from 6 to 10 seconds, But it did work which is rather amazing by itself 🙂
Metrics Store is an interesting idea on paper, but not sure in practice, it is hard to justify paying for multiple tools, if you build your semantic Model in one tool, why pay for another BI tool ? The Other challenge is self service Scenario, the user needs to be able to add extra Measures and Dimensions.
and for new vendors, it will be helpful to explain what kind of problems they are trying to solve that the existing tools couldn’t, just creating a new fancy name is not good enough.
Looker was always a bit of mystery for me, as there was no trial version to test, and they have high profile customers, luckily Google recently start providing trial version without asking too much Questions, I registered 2 months ago, and recently got an email with a trial offer.
it is just an impression, I just used it a couple of times in the weekend with no training
You get an URL instance with the name of your company, I used a dummy name.
The user interface is rather streamlined, nothing unusual which a good thing , as expected it is hosted in Google Cloud, but you can’t see anything from the console ( Looker is available in AWS, Azure and GCP)
Looker by default has two modes, development and production, everything you build is linked to Git repository
let’s say you want to build a new Dashboard , first thing to do is to create a new LookML Project, setting up GitHub was straightforward, I made the repo public
Probably you are asking where is the data preparation the Likes of PowerQuery or Tableau Dataprep, there is none, Looker connect only to Databases, it assume you have already a Data Warehouse, Looker Provide Just the Semantic Model using LookML code and the Viz, and the API which you can call from any Clients.
There is no Import mode, all connections are live, there is a cache though that save the result caches which you can adjust by Project or you can turn it off by using cache = 0 second.
There are aggregation Table , which you can use to speed up Queries but again you need to store them in the source database.
Looker use an internal Database ( I think MySQL), but is only to store internal Metadata ( users names, SQL Queries etc), all calculation depends on the source system
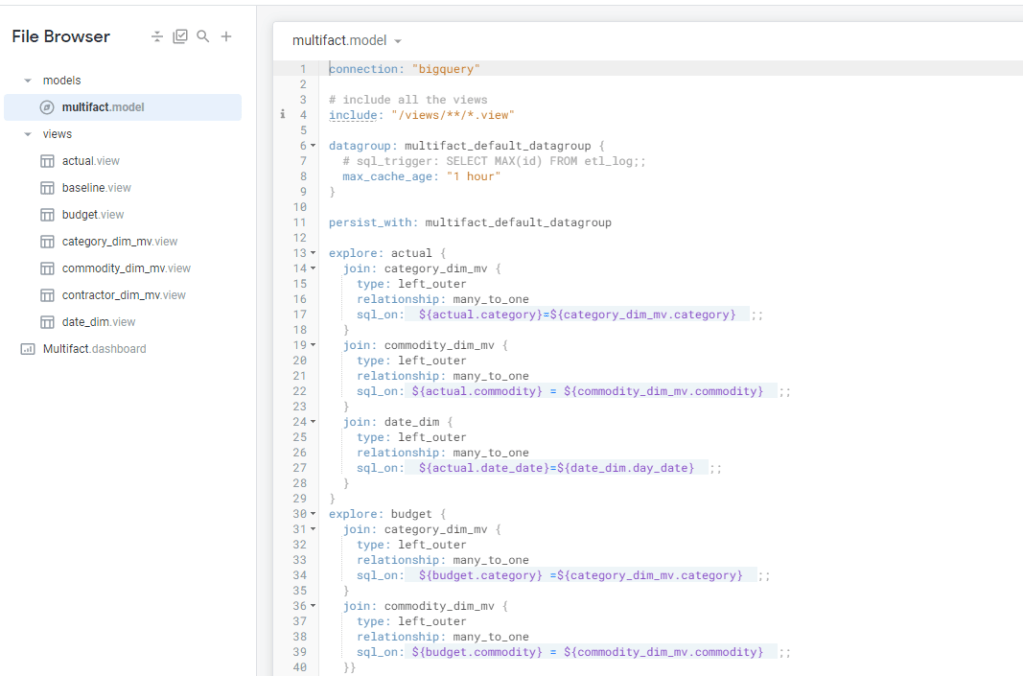
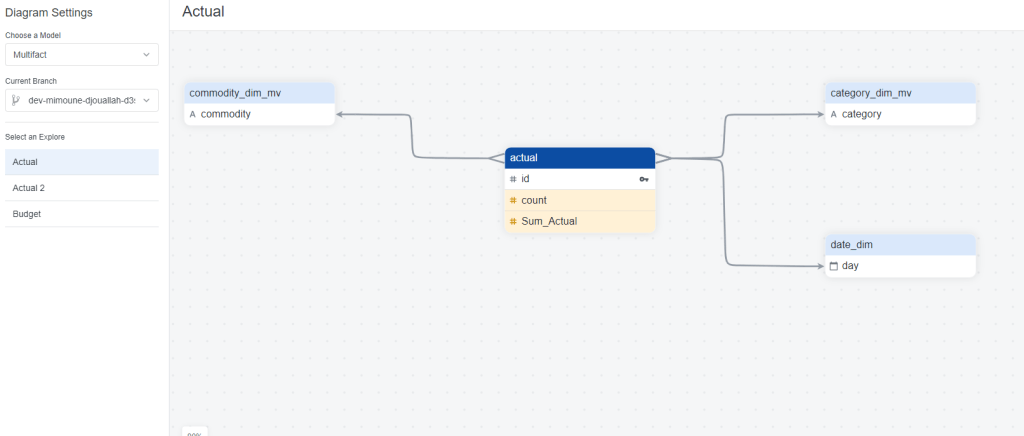
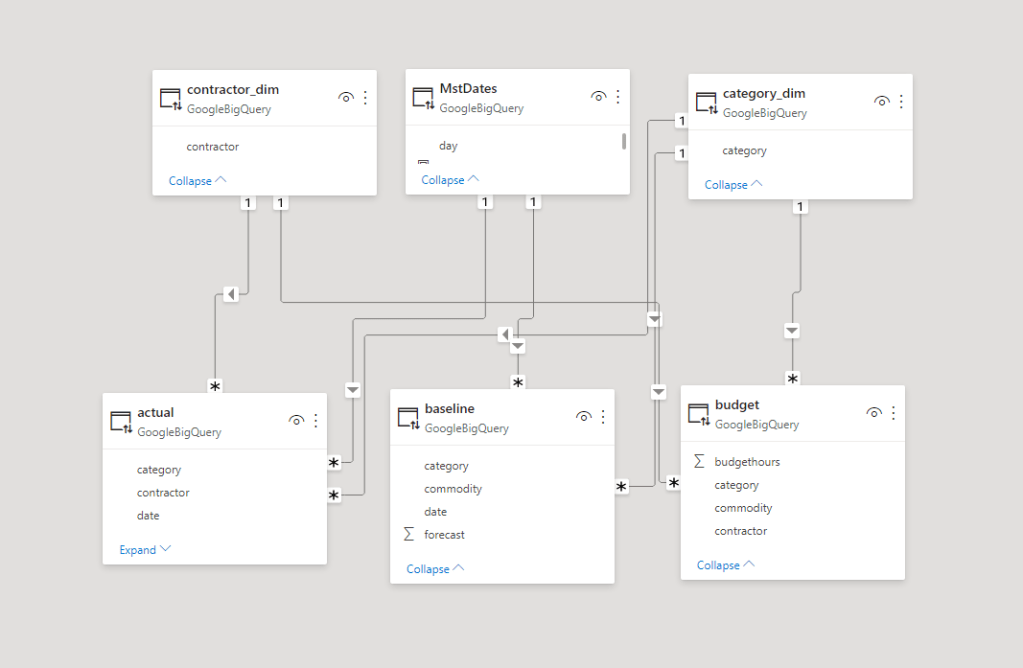
To my surprise at least for simple Semantic Models, LookML is not too hard, I connected to a dataset in BigQuery and Looker imported the Table Schema, all I had to do is to define relationship between Tables, and add Measures using SQL
funnily enough the most confusing Part; Looker does not use standard technical Terms:
Views means Table
Explore is a semantic Model
Model is a group of Explores and Views
Look is a chart
at any time you can View the Diagram View
One interesting aspect of Looker Modeling compared to PowerBI, you can have Multiple Models that join the same tables in different ways !!! but at the same time, I could not reproduce a typical Multi Fact Tables easily (Example from PowerBI, I am not saying it is not possible, but I did not know how to do it)
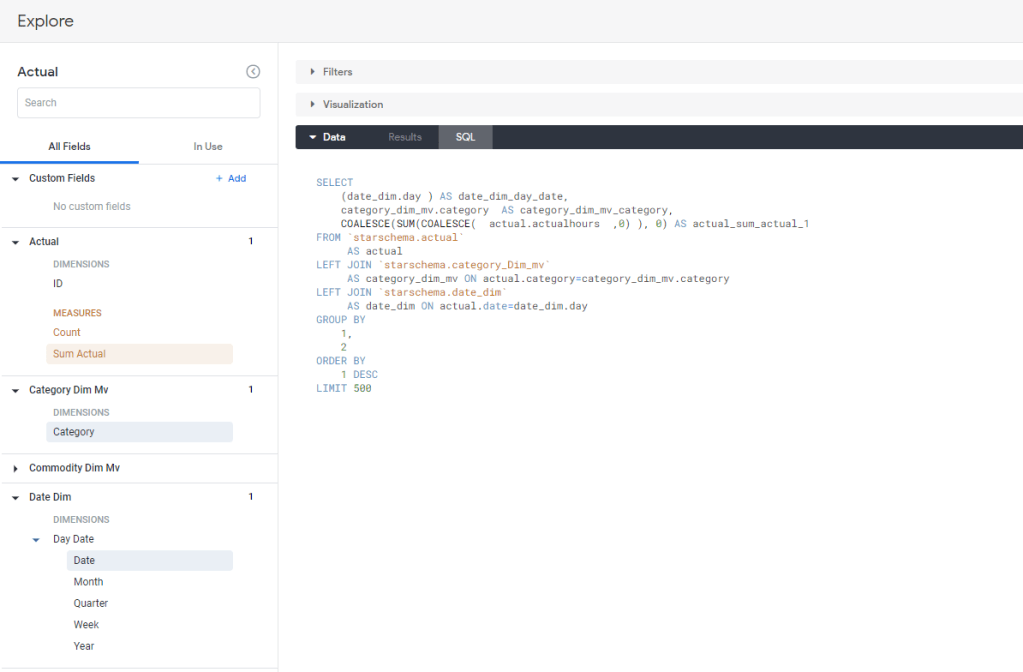
Once the Model is completed you can start exploration using “Explore”, I guess this is the core Concept of Looker , every time you add a metric and dimension, Looker automatically generate the Correct SQL, and because the Model are defined Enterprise wide , the metric definitions and dimensions are consistent regardless of the users.
Notice here, the first thing you get is the data in a tabular Form, then you define the Visual, there is a saying that PowerBI is 80 % Data and 20 % Viz, I would say Looker is 99 % Data and 1 % Viz :), OK I am a bit exaggerating but don’t expect a Tableau Level Customization
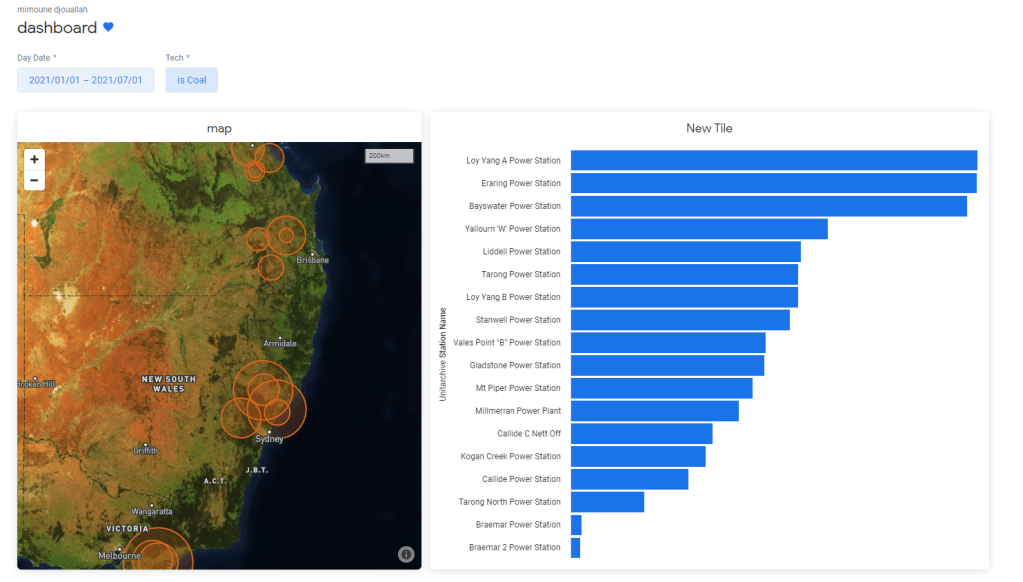
When you are happy with your explore you can save it as a Look which is basically an individual Chart which you can pin to a Dashboard like this one
Another very nice functionality is Roles, in PowerBI you can customize what a user can do , build new content, sharing etc, But in Looker it is very granular, you can customize any option , you can even authorize who can and can’t download data !!
Sharing is very trivial, you can share with external users with different email address, even users with gmail and hotmail.
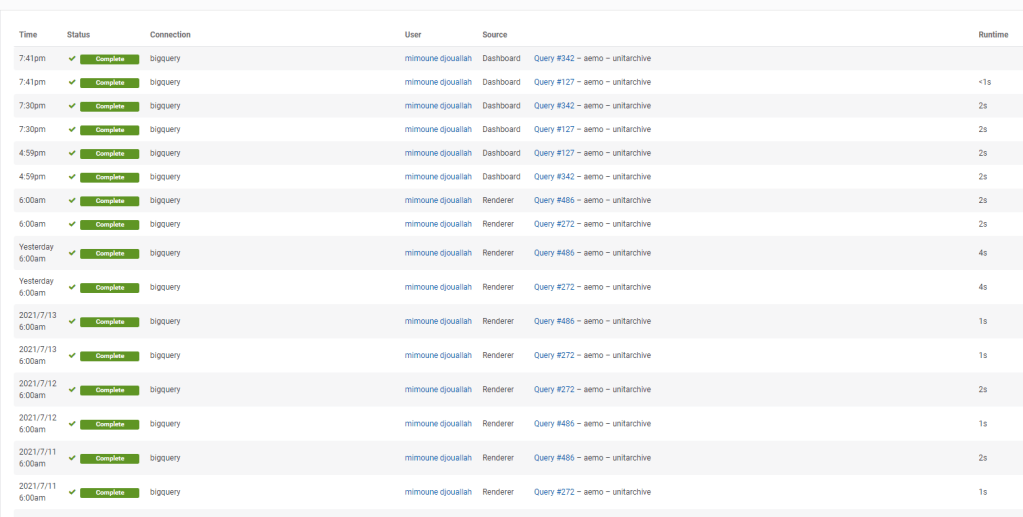
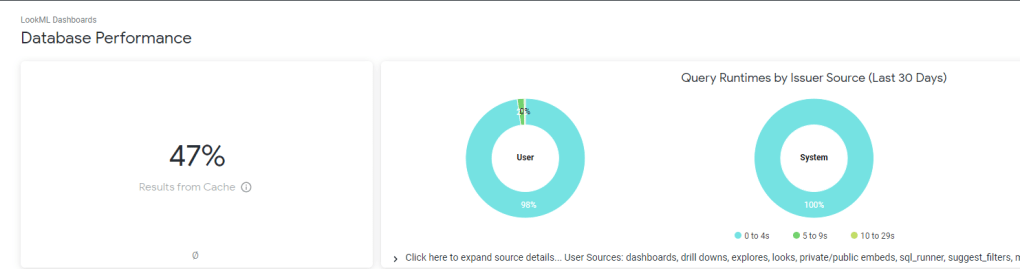
Tracking performance is simple, you can see the history of all SQL Queries and identify any issues
and a nice overall Performance of your Instance
Regarding Performance, I think Looker will perform Better compared to PowerBI in Direct Query mode , simply because there is less moving parts, in PowerBI, the viz generate a DAX Query against the Model which call the engine which call PowerQuery that convert to SQL, Looker Just Generate SQL Queries based on the Data Model that’s all
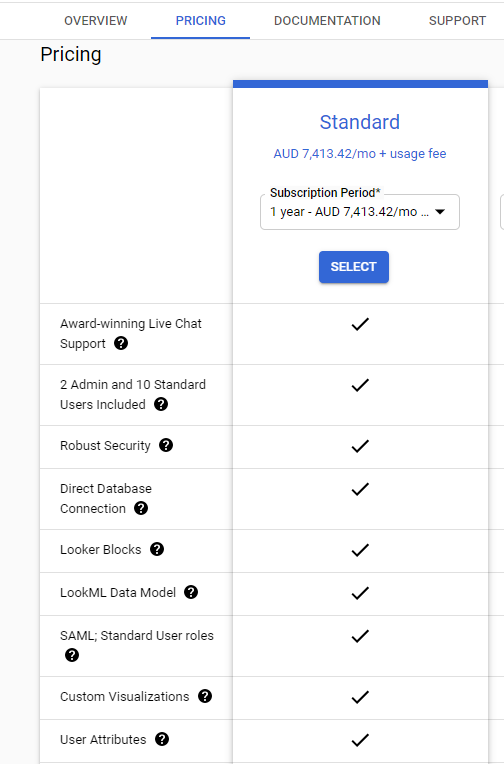
You can’t really Talk about Looker without talking pricing, here is a screenshot from Google Cloud Pricing
yes, there is no typo, 5000 $/Month get you 12 users and you need to pay 30 $/Month for any extra user !!!
apparently Looker is very popular with High scale embedded scenarios but it require some JavaScript skills which is out of my scope.
Take Away
as Far as I can see the target Market of Looker is Large Enterprises with Mature Data infrastructure and deep pockets, I can see the attraction of code based solutions with version control and centralized Semantic Models, no wonder BI professional with Software engineering background love it.
Apparently in the short term a lot of Data is moving to the cloud and Cloud Data warehouse are getting really Fast and cheap ( See BigQuery BI Engine), the concept of Live connection using a centralized Semantic Model is very attractive and according to some industry commentators it is the next big thing in Business intelligence.
Personally I am not sold, I think every Business users should be able to build his own analysis without waiting on a central BI team( not all reports are equals, some are strategic which require governance other less ), on the bright side LookML is not as hard as I thought at least for simple Models, but with the current Pricing, it is fair to say it is not a threat to PowerBI at least for smaller Installation
edit : got a feedback that a self service user can add custom measures and dimension that did not exist in the original Model , see documentation , but still if you want to use new data, it has to be imported first in the Source Database.
edit : Google shut down my trial instance after three weeks, unfortunately I can’t write any more about Looker, if someone from google is reading this , you’re not helping yourself.
Google Data Studio added recently support for BigQuery Geography field, which is a fantastic development and open all kind of new scenarios for creating free to share Maps.
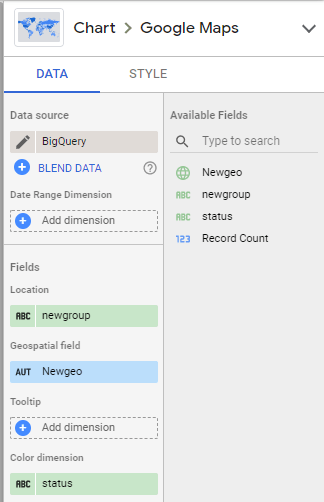
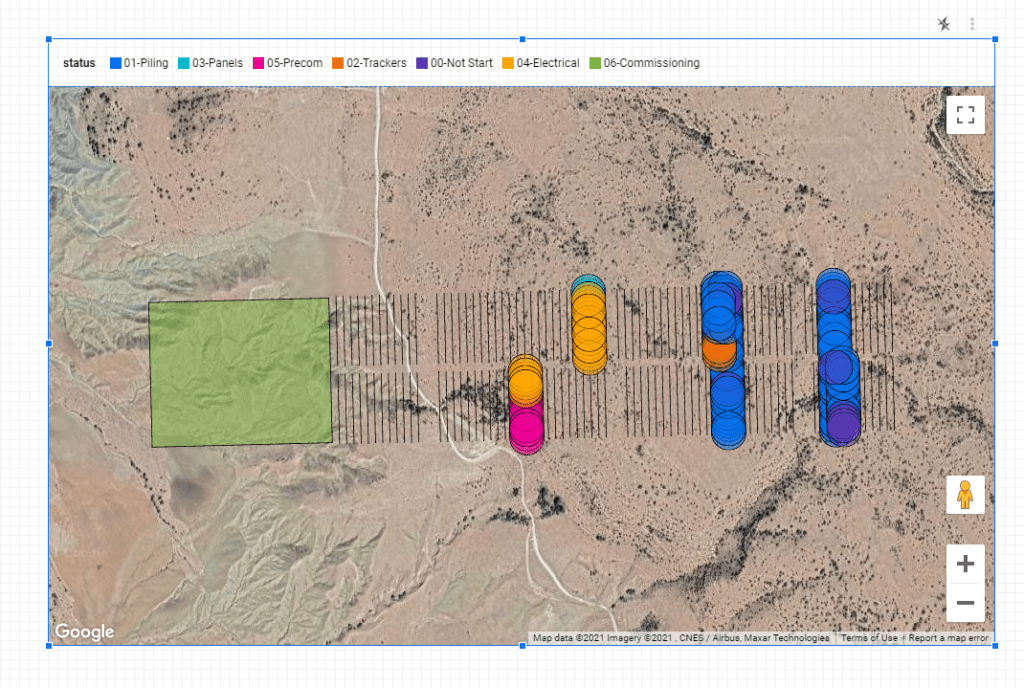
It is straightforward, you just add a geography field and it just render, for example I have this dataset that contains polygons, lines and points
and here is the result
Some Observations
It seems the initial focus of the dev team was on polygons which are fully supported
You can’t fill color for lines yet
Although points support color coding, I could not make them smaller ( The Piles in a Solar Farm are obviously much smaller)
BI Engine to the rescue
Now the confusing part, BI Engine for Data Studio does not accelerate GEOGRAPHY yet , so you will incur BigQuery Cost, but if you connect the new BI Engine SQL interface, the Query will be accelerated, according to the devs, the BI Engine used in Data Studio is to be considered Version 1 , SQL Interface as the next version and they will be merged together eventually. ( This should be in the Documentation)
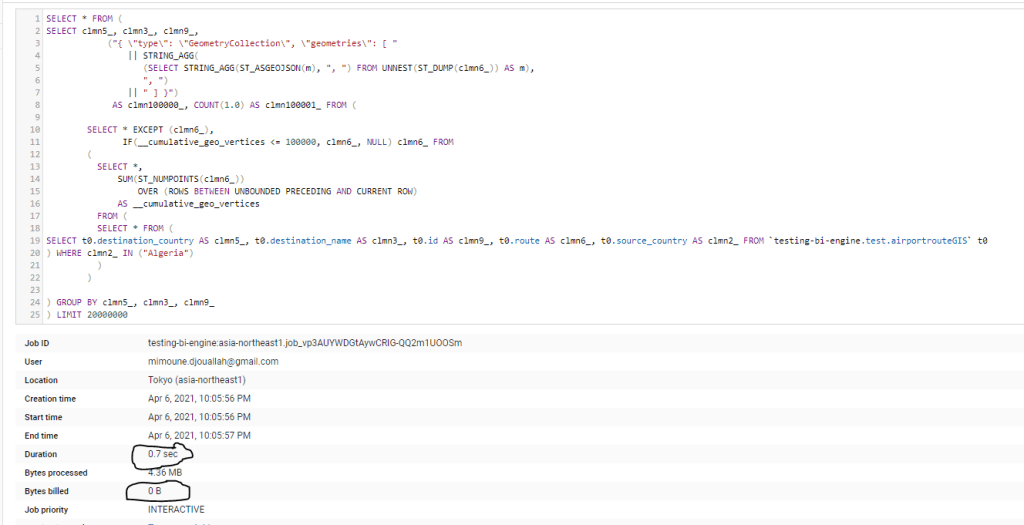
here is an example of a Query generated by Data Studio, I would say it is very complex SQL Query with analytical functions, UNNEST, you name it, and the New BI Engine support it just fine ( I really like Bytes billed 0 B)
A more interesting use case
I came across this excellent dataset https://openflights.org/data.html, and thought let’s try it with Data Studio, first I imported the two tables airports.dat and routes.dat then using this SQL Query to generate the routes, which is a line between Source coordinates and Destination Coordinates
WITH
xxxx AS (
SELECT
yy.Name AS source_name,
yy.City AS source_city,
yy.Country AS source_country,
zz.Name AS destination_name,
zz.City AS destination_city,
zz.Country AS destination_country,
DestinationairportID,
SourceairportID,
ST_MAKELINE(st_geogpoint(yy.Longitude,
yy.Latitude),
st_geogpoint(zz.Longitude,
zz.Latitude)) AS route
FROM
`testing-bi-engine.test.airportroute` xx
LEFT JOIN
`testing-bi-engine.test.airport` yy
ON
SourceairportID= AirportID
LEFT JOIN
`testing-bi-engine.test.airport` zz
ON
DestinationairportID = zz.AirportID),
ttt AS (
SELECT
source_name,
source_city,
source_country,
destination_name,
destination_city,
destination_country,
DestinationairportID,
SourceairportID,
ST_ASTEXT(route) AS route_wkt
FROM
xxxx
GROUP BY
1,
2,
3,
4,
5,
6,
6,
7,
8,
9)
SELECT
*,
ST_GEOGFROMTEXT(route_wkt) AS route,
ROW_NUMBER() OVER() AS id
FROM
ttt
I save the Query in a table, then plotted using Data Studio
and here is the Result, which i share it in Reddit 🙂
I think it is fair to say, people love maps, and a lot of users appreciate that you can download the data straight from Data Studio , you can play with the report here
Google made BigQuery BI engine available in a public preview , you need to enroll first here, for the last two years it was available only for Google Data Studio, and I had use it extensively for this Project, so I was really curious how it will work with PowerBI.
I don’t think I know enough to even try to reproduce a benchmark, Instead I am interested in only one Question, how much value I can get using the lowest tier of BI Engine and can PowerBI works smooth enough t make Direct Query a realistic option.
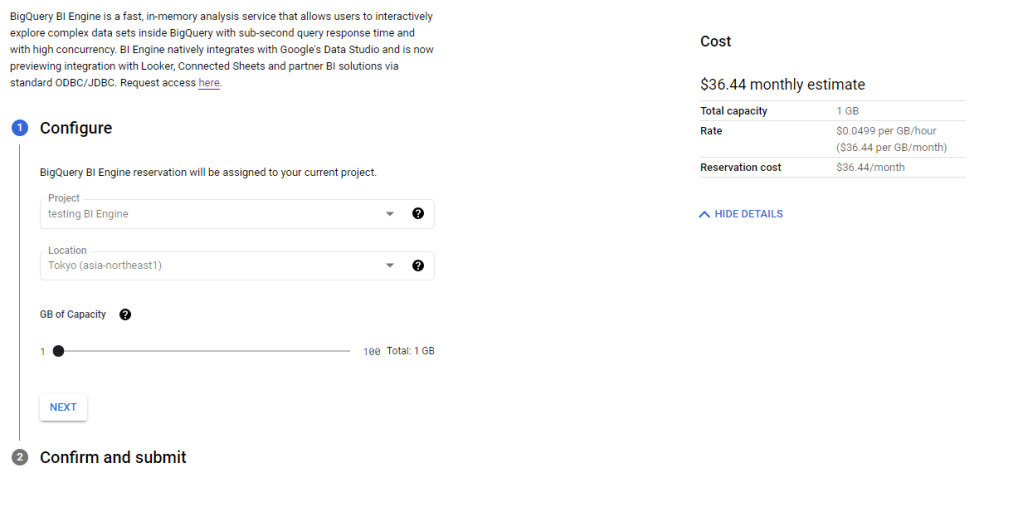
BigQuery team was nice enough for the preview period to have 100 GB reservation free of charge, just to keep it realistic, I kept reservation to 1 GB with a cost of $30 per month, I built a couple of reports in PowerBI and tried to observe how BI engine behave and observe the Query statistic , The report is located here, The Data is using Direct Query Mode, the Query statistics update every 1 hour.
How BI Engine Works
it is extremely easy to setup just select how much memory you want to reserve by Project, and that’s all, you pay by GB reserved per hour.
Keep in mind the Project used for reservation can Query any other projects as long as it is in the same region, in PowerBI, you can define which project you use for the Query
After you wait a couple of minutes for BI engine to start, this is more or less how it works
1-Query received by BigQuery, based on columns used in the Query, BI engine will load only those columns and partition into the Memory, the First Query will be always slower as it has to scan the data from BigQuery Storage and compress it in memory in my case usually between 1-2 second
2-Second Query arrive, the data is already in Memory, very Fast 100 ms to 500 ms
3- Same Query arrive as 2, BigQuery will just hit the cache, that’s the sweet spot, less than 100 ms
4- A new Query arrive that target different table, that’s the interesting part, BI Engine based on the size of the scanned column, and the available reservation, either evict the old table from memory or decide that there is not enough Reservation then it will fall back to the default BI Engine, where you pay how much data is scanned
5- A Query arrive that contains feature not supported by BI Engine , it will fall back to the default engine
6- Data appended to the Base table or Table changed, BI Engine will invalidate the cache , it will load the delta to memory or load everything again if the table was truncated
Obviously it is much more complex behind the scene, But I find it fascinating that BI engine in a fraction of a second decide what’s the best way to serve the Query ( cache, Memory or Storage)
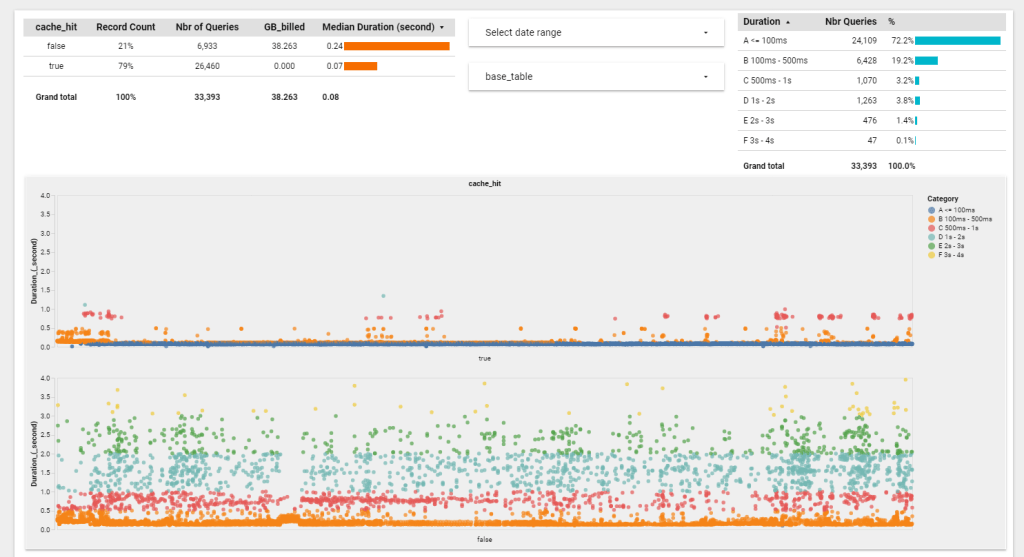
Personally I am very interested in Case 4, obviously if I reserve a Memory I want to minimize scanned storage to the lowest possible, here is the result for the last 10 days, I think that’s a great result, my ” Big Table is 6 GB, 50 Million rows” other tables are smaller , the dev team said they are working on improving even more how BI Engine algorithm deals with smaller tables, so far happy with that. ( it is fixed now, the memory consumption is extremely low now )
I appreciate other users with flat rate pricing would not care that much about file scanned , for user with usage based pricing, it is a very important factor
Query Performance
Again the results is based on my usage, the only way to know is to try it yourself, nearly 72 % of Queries render in less than 100 ms, I think it is fair to say, we are into a different kind of data warehouse architecture
PowerBI Performance
The Query Performance is only a portion of the whole story, you need to add network latency and PowerBI overhead ( DAX calculation, Viz rendering etc), my data is in Tokyo Region and PowerBI Service is located in Melbourne, a bit of distance I would say and using Publish to web add an extra latency.
The good thing, using Direct Query on a 51 Million Fact table with 5 dimensions is an achievement in itself, I feel I can use that in a Production, at the same time, using other report, it seems I am hitting a bug in the ODBC driver, and the performance is not good.
but to be totally Honest, it seems PowerBI driver for BigQuery is far from being optimized, it seems they are using SIMBA ODBC , other BI tools are using the native API and it is substantially faster, but I have reason to believe the PowerBI team will invest more in better Integration ( PowerBI parameter in SQL Query is coming for example)
I Think it is extremely interesting new development, specially if you have Big Fact tables or data that change very frequently, Direct Query mode have a lot of advantages, it is very simple to setup, the data is always fresh and there is no data movement. and BI Engine is fast, extremely Fast, and Cheap !!!, I am using a state of the art data warehouse for $30 per month !!!!, now it is up to The PowerBI Team to take advantage of that.