The first time I used Direct Lake I was blown away by the performance, it was just too good to be true,import performance with nearly instant refresh time, a month later, I have better understanding, the first impression is still valid but it is more nuanced, there is always a tradeoff
Import Mode
Let’s take a simple analytical pipeline using PowerBI service, reading a csv file from a web site, you will have something like this
Ingestion :
- Download the csv
- Sort it, and Compress it and save it into PowerBI Proprietary columnar file format in Azure Storage
Query :
- When a Query arrive in the service load the columns from PowerBI file in Azure Storage to the Server RAM
When people use import mode they usually means those two stages (Ingestion and Query), refresh in import mode means ingest new data and load it to RAM
Direct Lake Mode
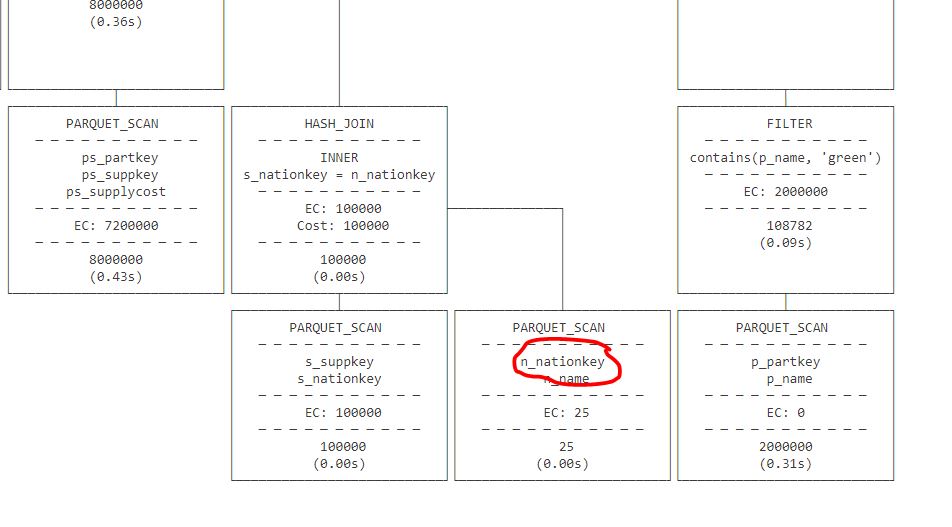
In Direct Lake mode, more or less the Query stage is the same, that’s a great technical achievement from the Vertipaq team, instead of scanning PowerBI storage file, you do the same for Parquet
But here is the catch: refresh is nearly instantaneous because it is not doing much, the ingestion of new data did not magically disappear but has to be done elsewhere.
Who does the Ingestion then ?
You can use Spark, Dataflow Gen2 , Fabric DWH etc to create and update the Parquet files, or if you are lucky and your system produce Delta lake tables with the right file size etc, you hit the jackpot
Why you may not want to use Direct Lake
- It is a Fabric only feature.( edit : you can use shortcut to an existing Azure storage bucket , but you still need OneLake running, Hopefully one day, we can run Queries directly from an object store using PowerBI Desktop)
- You use calculated column, calculated table
- If your users interact with the data using only PowerBI reports then it is not worth the added complexity.
- It does not work with PowerBI desktop, my understanding, it will fall back to Fabric SQL Engine.
- Storing all the tables and metadata in one file is a very powerful concept and works very well in the desktop, which is still the main development environment for users.
- Not specific to PowerBI but usually for pure performance , proprietary Storage files are faster for the simple reason, they are super optimized to the Query Engine and have no compatibility requirement.
Why you may want to use Direct Lake
- If you have a use case where import mode was painful or literally did not work.
- Somehow you have a system that produces Delta Lake Tables with the right file size and row groups.
- Because ingestion is done outside PowerBI, you may get less memory pressure which is still the biggest bottleneck in PowerBI.
- You want to share Data to non PowerBI users.
What will be really nice.
Today Both import and Direct Lake don’t push down filters to the storage file, I think there is an expectation that BI Query Engine should support data that don’t fit in memory.
It will be nice too if Direct Lake support more table format like Hive and Iceberg