Was chatting with David Eldersveld and he suggested that he wants to run a competition using the famous New York Taxi Dataset with Datamart, long story short, I did endup publishing my attempt before he had the time to start the competition, my sincere apology.
The report is using my personal PPU instance, the data is located here , personally I wanted to exclusively use tools available in PowerBI out of the box, no Synapse nor Azure stuff or BigQuery, Just pure self service tools.
Initially I didn’t really believed that PowerQuery can download such a big volume of data, my first set back , PowerQuery can not read parquet files available in public url, but as usual Chris Webb has an excellent blog explaining the reason, and gave a workaround.
I added the code here, it does work with any PowerQuery in Dataflow, Datamart and PowerBI desktop, unfortunately Excel is not supported yet, when prompted for authentication use anonymous
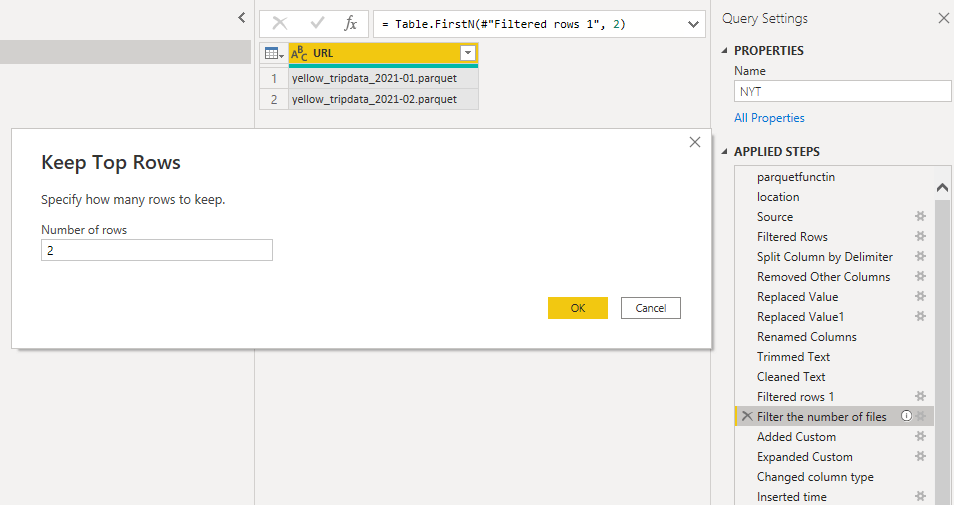
The only section of the code that you should pay attention to is selecting the number of files to download by default it is 2, but you can increase it
Only when I was writing this blog, I noticed the files for 2022 are using a slightly different URL, will update the code later. Code Updated.
To reduce the database size, I had to split Datetime to date and time, low cardinality is good for performance too.
Loading into Datamart
I don’t know how much it took datamart to load the data, currently Query refresh history is broken, but I think it is more than 6 hours, I maybe wrong, but Datamart take a bit of time to generate the tables with Clustered Columnstore Index
Initially I loaded only 2 then 30 files just to see how Datamart behave and finally I went for 100 files, and it did work again to my surprise.
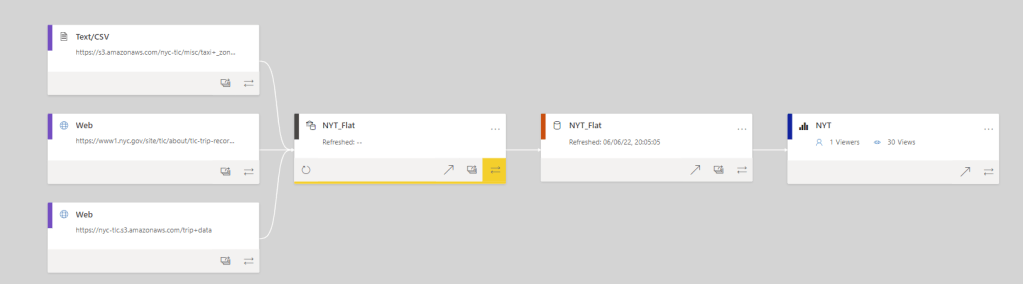
and the Lineage View of the report
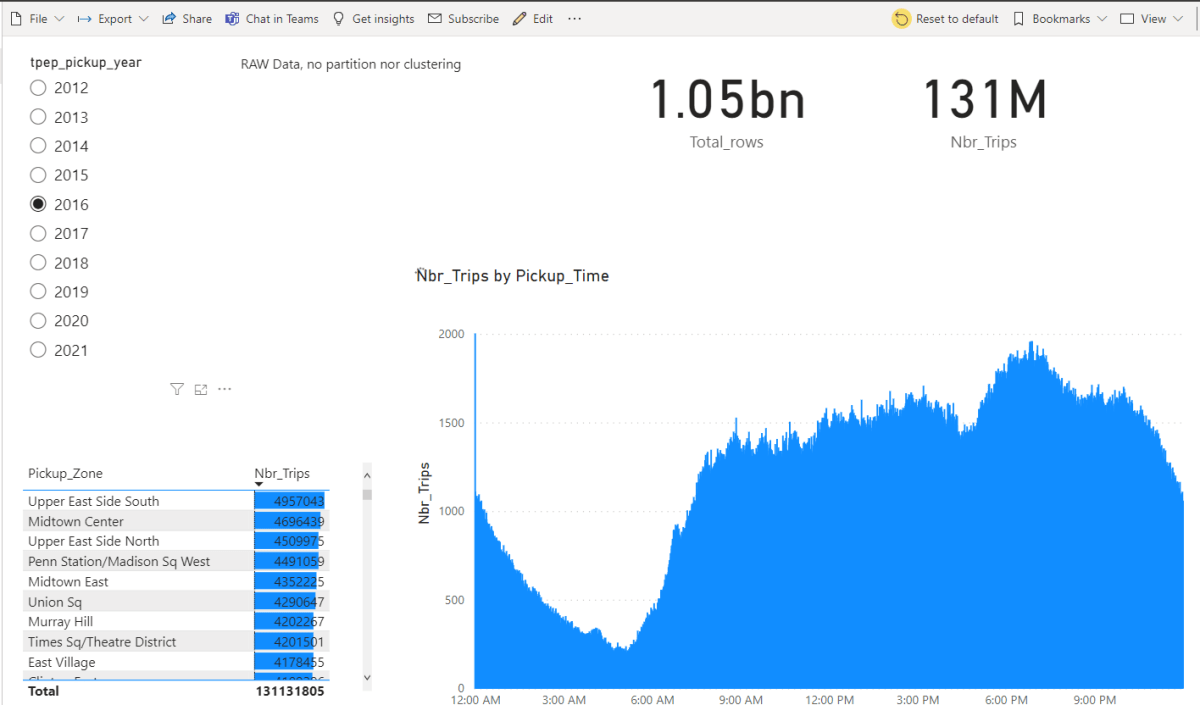
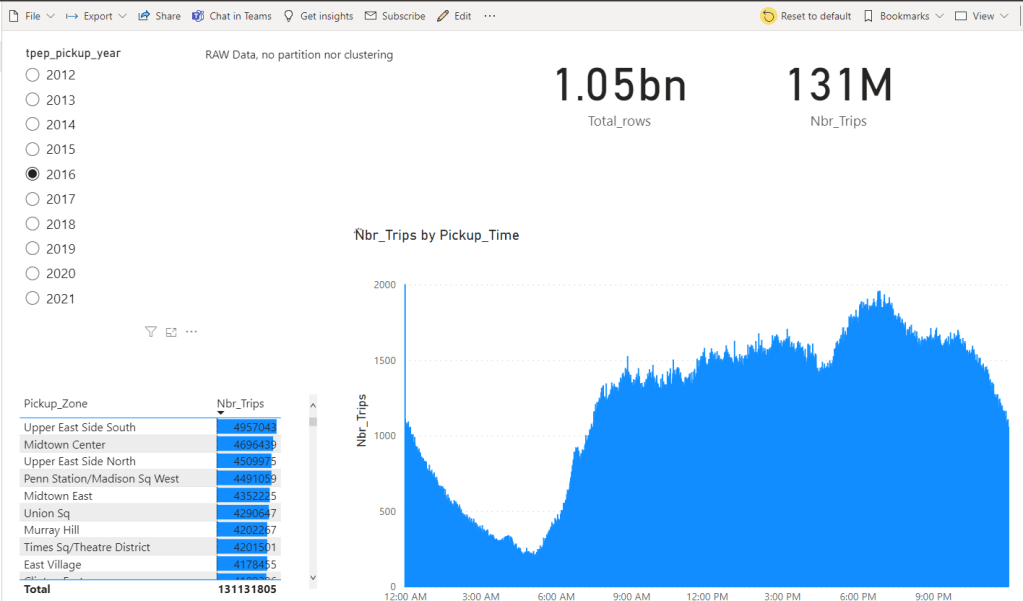
Performance
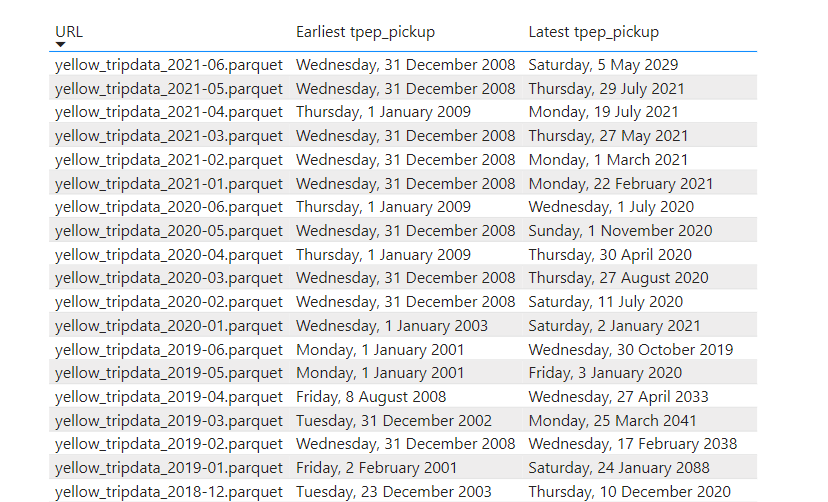
The Performance is not bad at all considering, the data was loaded as it is and it not sorted, although the parquet files are organized by month, unfortunately there are some outlier in every file see for example, so you get overlapping segments.
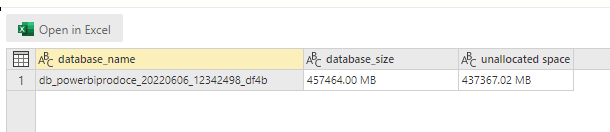
You can check the database size on disk by running this Query
EXEC sp_spaceused
Optimisation
Pretty much the only optimisation you can do in Datamart is to pre sort the data before loading it, but when you have 1 billion rows saved in parquet files, sorting is a very expensive operation, but there are options I think.
Create another Datamart and load it from the “raw” Datamart and define incremental refresh which will create partitions, yes partitions should improve the performance.
Hybrid table in PowerBI Dataset where only the recent data is cached in Vertipaq and the history kept in Datamart as a Direct Query Mode.
Final thoughts
The Publish to web report is here, a very big missing piece is the option to append data to an existing Datamart, this will make adding new data without a full refresh extremely trivial, I know about incremental refresh, and I am sure a hack like this may work, but we want the real deal, Dataflow people hurry up 🙂
I notice something interesting because the price of PPU is fixed, I felt I can experiment without the fear of getting a massive bill, maybe reserved pricing is not a bad thing after all.
My first reaction when I saw datamart was, that it will be a big validation for PowerQuery, and it is, as Alex said, PowerQuery everything !!!

Congrats for this effort. Si there a way that you could share the results of the performance analyzer? So, we can see hoy well performs datamarts
LikeLike