TLDR
A simple script that load some data from Azure Storage into a disk cache, run complex Queries using DuckDB and save the results into a destination Bucket using a cheap Azure ML Notebook, The resulting bucket can be consumed in Synapse serverless/ PowerBI/ Notebook etc
Introduction
Last year, Azure Synapse team published an excellent article on how to build a lakehouse architecture using Azure synapse, what I really liked is this diagram, it is very simple and to the point.
Notice, I am more interested in the overall Azure ecosystem, so it is vendor neutral.
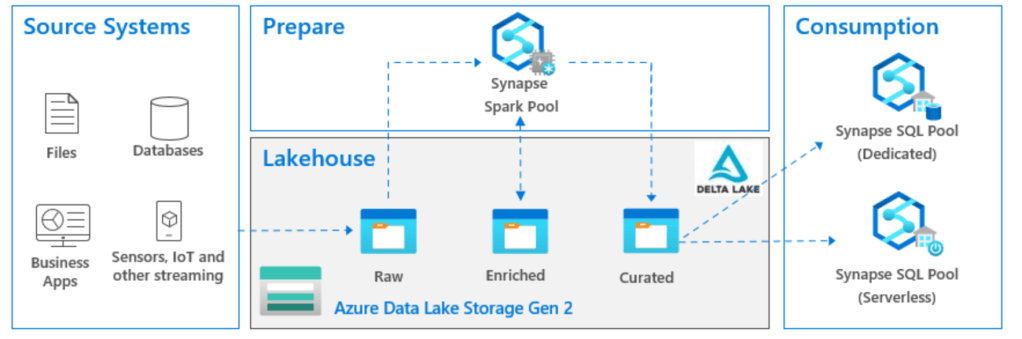
In practical term, Lakehouse here means the storage system with an open Table Format, now if you ask three different people about this diagram, probably they will give you 4 different answers.
- An Old school Dedicated pool professional will argue this is an over complicated system, and all you need is Source system —> Data integration tool —> Dedicated Pool
- As I have a soft spot for Serverless, ideally, I would say, add Write capabilities to Serverless and call it a day
- A Snowflake or Databricks Person will argue, One Engine should do everything; prepare and serve.
- My colleague who is an Azure data engineer will say the whole thing does not make any sense, ADF and SQL Server is all you need 🙂
What if you don’t have big Data ?
The Previous Diagram assume a big data workload, as Spark has a massive overhead in compute usage and cost and does not make much sense for a smaller data.
What if you have a smaller data size, can we keep this overall architecture and keep the lower cost, maybe we can, I will argue, it maybe even be useful very soon 🙂

Why you are keeping the serverless Pool
I think it maybe the obvious question, DuckDB is an awesome Execution Engine, but it is not a client server DB, you can’t have a SQL Endpoint that you just use to run Queries from PowerBI etc.
There are projects to do that but it is not ready yet, and even if you find some hacks, trying to implement governance and access controls will be non-trivial.
Obviously you can use Azure ML notebook just to do exploratory analysis, but that’s not something that make sense for Business intelligence People 🙂
PowerBI
The theory is because the data is prepared and cleaned at the Storage level, PowerBI can just import the Parquet files, a SQL Endpoint is not strictly needed
Ok sweet, so where do you run this Duck thing?
Honestly that was the hardest Part, using synapse Compute fail the purpose as it is designed for Spark, the minimum is three VM, turn out Azure has an Amazing machine learning service, that we can just use for data engineering, you can run VM as low as 1 Core (8 cents/hour), auto shutdown is available, so you pay only for what you use, and you can schedule jobs, yes it is supposed to be for ML but it does work just fine for Data engineering Jobs.
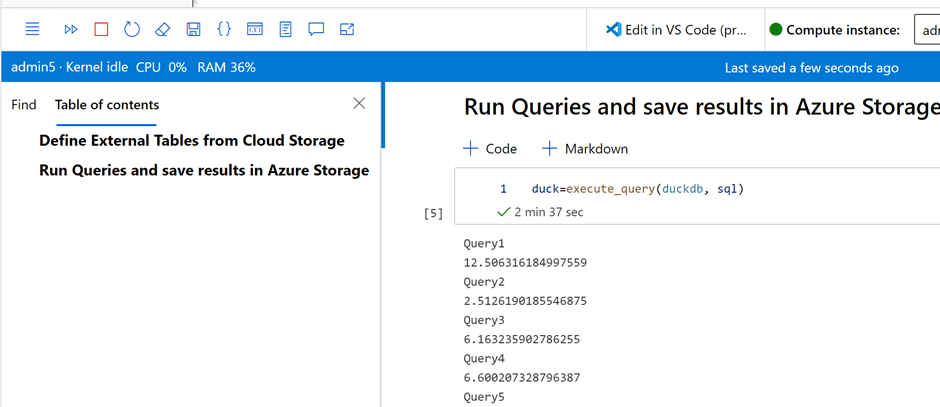
Show me an Example
The Pipeline is very simple
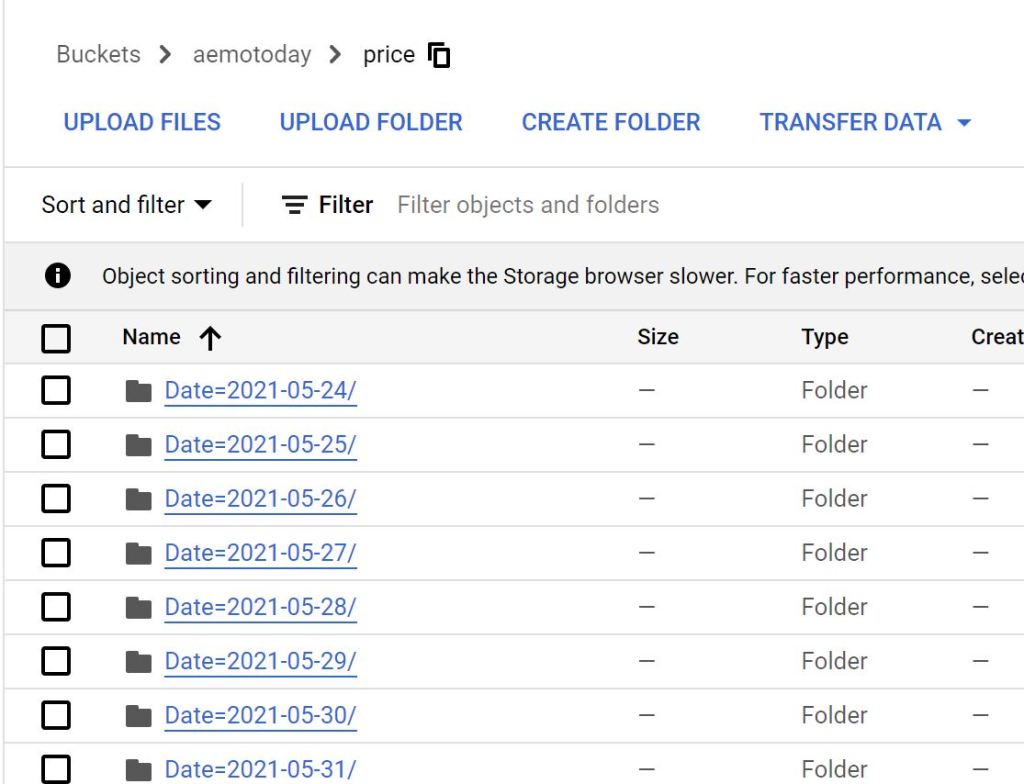
-Read Data from Azure Storage bucket
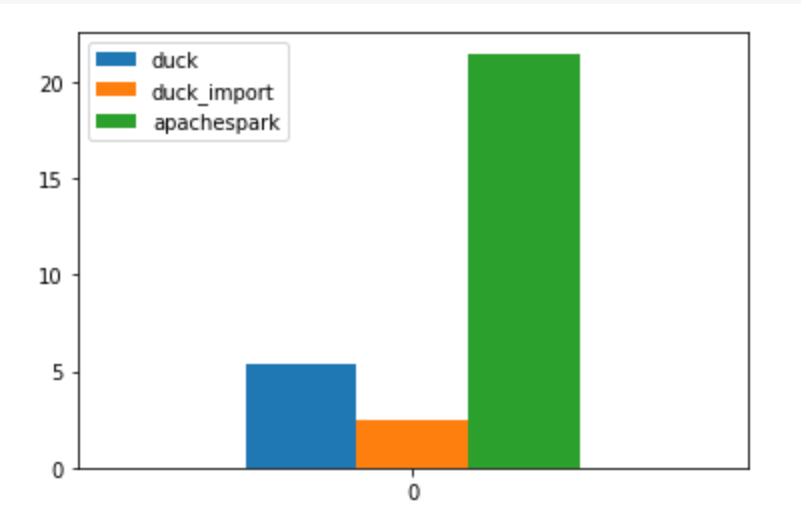
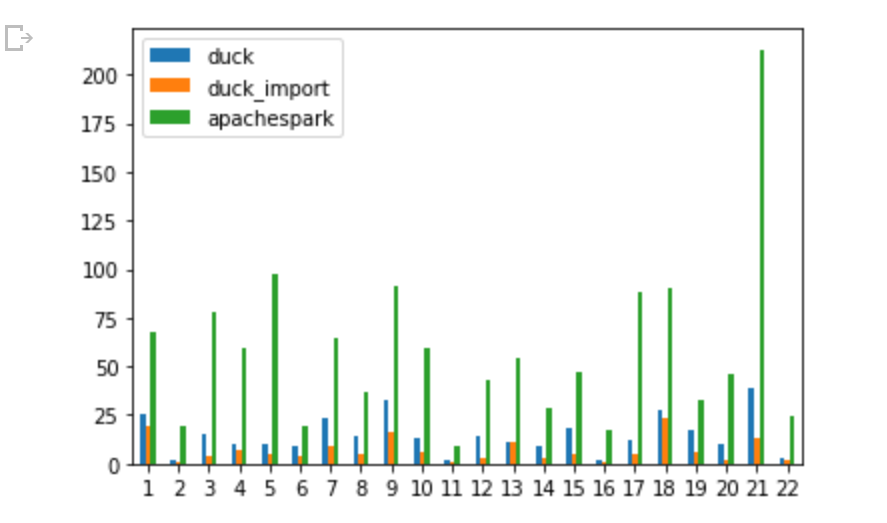
-Run Some Complex Queries (22 Queries)
-Save the results in a Bucket
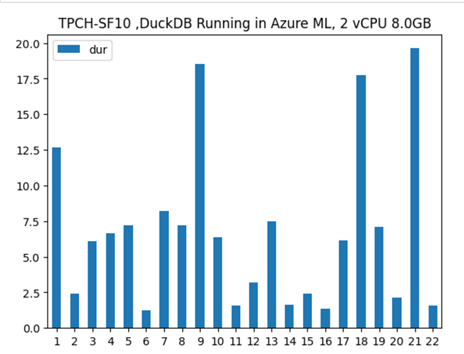
The Compute used is an Azure ML VM that cost 14 cents/Hour, the Raw Data is around 3 GB, main table 60 million rows, the overall pipeline took 2 minutes and 37 second, I think this is the most cost-effective way to run this workload on Azure. ( synapse serverless would have being perfect with the pay by scan model but write capabilities is rudimentary, basically you can’t overwrite a folder, but that may change anytime)

And The results
I Appreciate TPCH is not a benchmark for heavy write, but I used something easily accessible, and I can compare to other systems.
Thanks to Koen Vossen for showing how to use the disk cache with fsspec
What’s the catch?
As of this writing, Python support for open Table format (Iceberg, Delta ) is very limited, personally I found that Arrow dataset is the most mature offering today, but it support only Hive tables and only append or Overwrite.
if you need a merge or update directly on a remote storage, your only option is to do those operation in DuckDB using the native file format and overwrite the files in the remote storage, it works well for small data but it will not scale.
Note : my experience with Python Delta table (Not Spark) was mainly with GCP, turn out Azure has a better support ( can read, write, show history, vacuum) still as of today, I still think Arrow Dataset is more stable.
Final Thoughts
Regardless of what you use, I think it is important to ask your vendor, what’s your solution for smaller data? are you to paying a premium for a big data solution and is it justified by your workload ?