A quick post on a nice functionality in BigQuery, if you create a Materialized view based on Table X, and you run a Query on that Table, the Query Optimizer is smart enough to reroute the Query plan to use the materialized View instead of the base Table, it is faster and substantially cheaper.
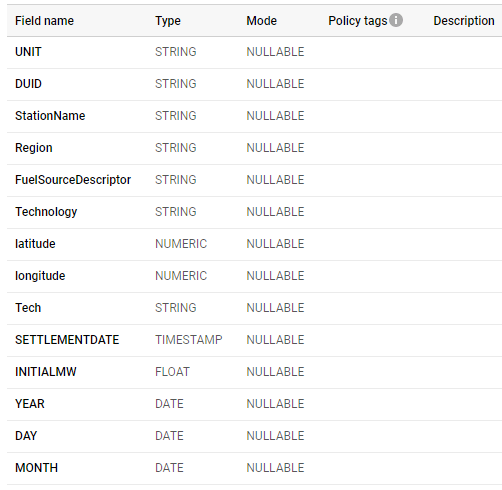
for example, let’s take this table which has a granularity of 5 minute ( 75 Million Records)
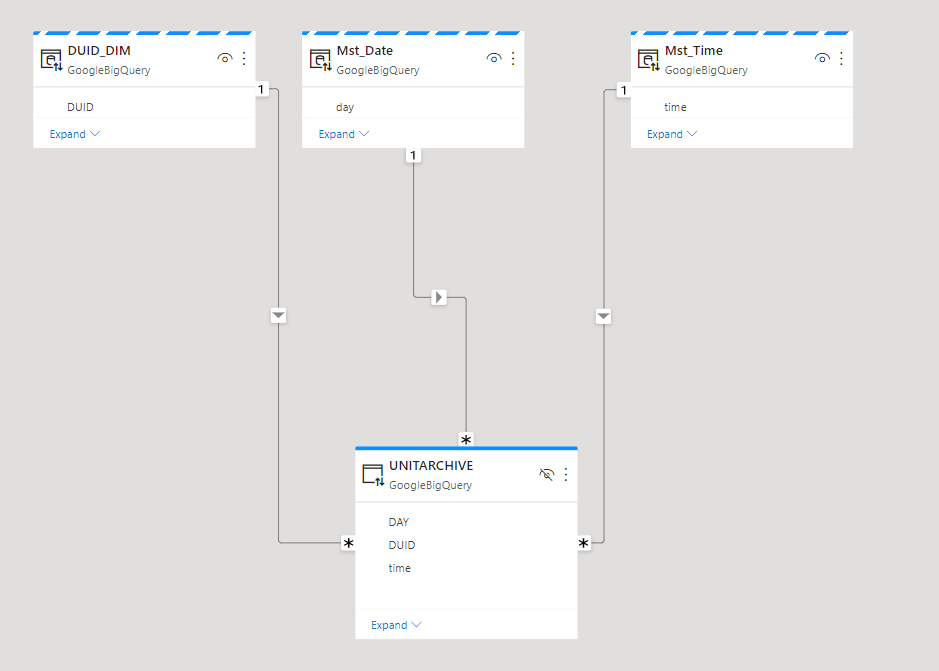
let’s create a Materialized view that aggregate at the day Level
CREATE MATERIALIZED VIEW
XXXXX.ReportingDataset.UNITARCHIVE_Summary AS
SELECT
StationName,
DUID,
DAY,
SUM(Mwh) AS Mwh
FROM
`XXXXXX.ReportingDataset.UNITARCHIVE`
GROUP BY
1,
2,
3
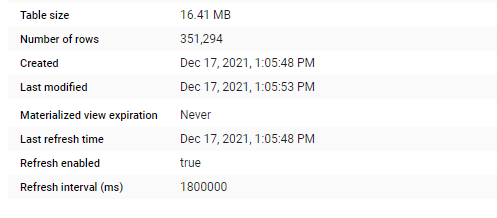
The resulting MV is 16 MB, and 350K rows , notice once you create a MV, you can forget about it, BigQuery make sure it is updated, and for whatever reason if the MV was not updated the Query planner will default back to the base Table, please see documentation for further details
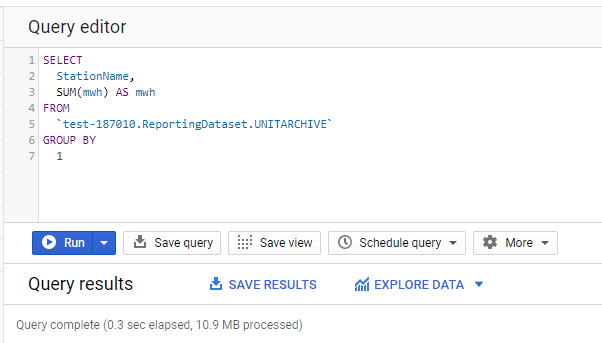
Now here is the interesting Part, let’s make a Query that target the Base Table
because the fields used in the Query exist already in the MV, the Query optimizer change the Query plan to use the MV, instead of scanning GB of data, it end up scanning 10 MB.
How About BI Engine
When Using BigQuery BI Engine performance wise both Queries either Base table or MV will return results in millisecond, but I suspect using Materialized view is beneficial as it uses less resources which means potential even more concurrency.
TL;DR : Random observations after using Snowflake for a couple of hours, there is a lot to likes but mixed feeling about the cost.
For no obvious reason, I felt an urge to try Snowflake, The setup was trivial, you get 30 days trial with $400, no Credit card required.
Snowflake is multi cloud product, first I had to choose the cloud provider and the region, My Personal PowerBI instance is in Melbourne, unfortunately as of this writing it is Only Available in Azure Sydney Region, it make sense to choose the same region for two reasons
Latency, inter region Transfer take more time
Egress Cost, Cloud Provider charge for Inter Region Transfer
For the record my personal data is in GCP Tokyo , but Snowflake is not available there.
User interface
The User interface is very neat and simplistic ( Good thing), I did not need to check any documentation
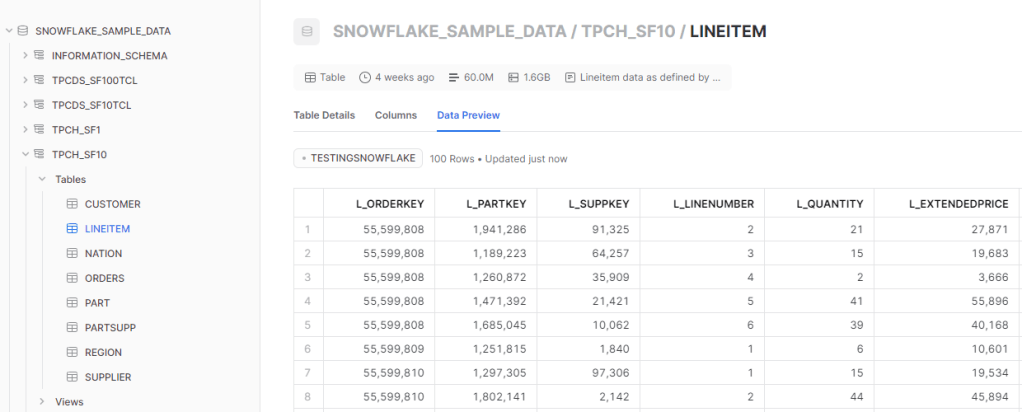
Snowflake provide free sample data by default
and Obviously, you can browser all kind of data from the Marketplace , it is very well integrated and seems trivial to use, as you have noticed already, Snowflake like BigQuery has a total separation between Storage and Compute, so far so good.
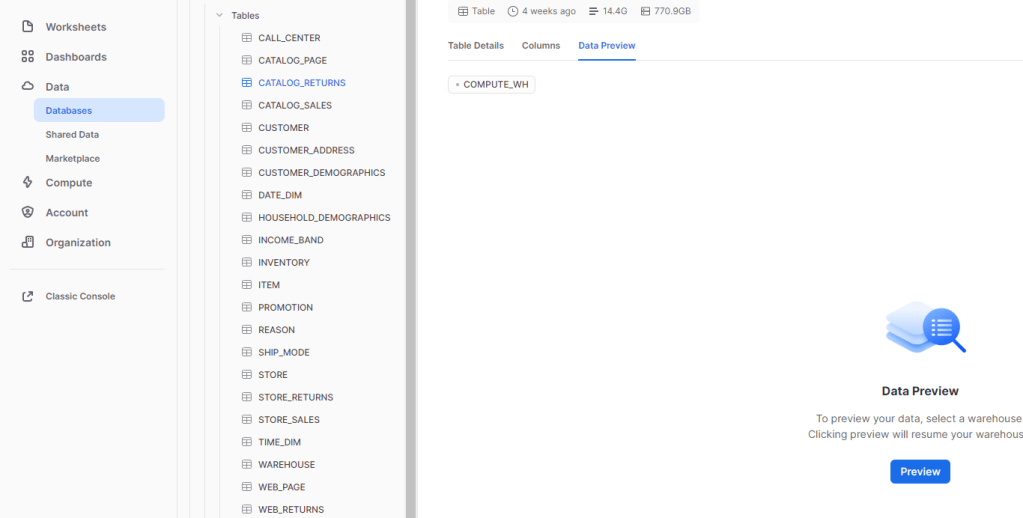
Preview Data
I click on Data Preview, and I got this message
Yes Unlike BigQuery, Data Preview is a paid operation and require a Cluster running.
Create a new Cluster
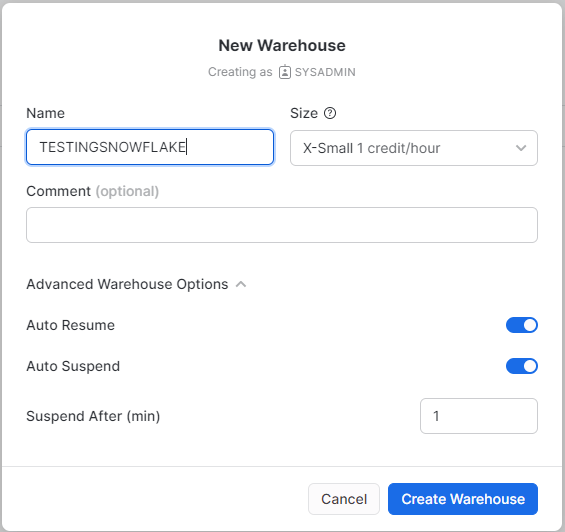
This is the core feature of Snowflake, creating a new cluster is trivial, as a test, I create the smallest possible Cluster.
The Cluster was up and running in a couple of seconds, very Impressive, and the way it works is very simple.
if there is no Query Running, it will shut down after 1 minute ( or whatever you choose), When a new Query showed up for example from a BI tool, the Engine very quickly wake up !!!!
The Minimum Cluster, I could setup was X-Small and it cost 1 credit/Hour ( 2,75 $/Hour), but you pay per second with a 1 minute minimum , I am using Standard Edition, Enterprise edition cost more.
Note : As a BigQuery enthusiast, I hope Google release the auto flex slot
Notice here, Snowflake is not simply a cluster to Run some Queries, but it does have a Service Layer which do a lot of operations behind the scene, personally I am mainly interested in free Results cache, which is freaking fast , as low as a 50 ms !!!!
Query History Log
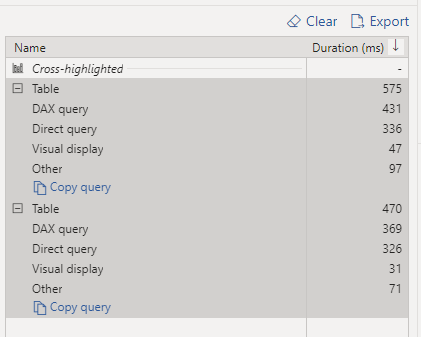
A nice Query history log, I really liked the Client Driver, you can easily tell, if the Queries are coming from an external BI tools or Query from the Console, one very very annoying thing, if you change that view and you came back, you lose the selection and you have to select the columns again, I wish Snowflake could save the customization of the columns.
Query Console
it was not very obvious, but to select columns name, you need first to click on a table which open a panel then Click on those three little dot, (it is obvious once you know it) , there is no multi tab support, new Query open a new Window, but honestly seeing the new BigQuery UI, maybe it is not a bad idea after all 🙂
Performance
My initial plan was to use a copy a SQL Script from BigQuery that uses Loops, but turn out Snowflake don’t support DO while ( it is coming for SQL ), there is a workaround using javascript which I may use later, but instead, and just to have a first impression, I used a PowerBI report in DirectQuery mode and see how it goes.
Snowflake Driver for PowerBI is amazing, I never saw a sub second Direct Query in PowerBI before, even when returning 1 row from cache, ( BigQuery Driver for PowerBI is not optimized, I don’t really knows who to blame, Google or Microsoft or probably both, turn out it is Google responsability)
I am using TPCH_SF10 dataset, the main fact Table contains 60 Million records
And here is the Snowflake data Model ( pun intended) in PowerBI using DirectQuery.
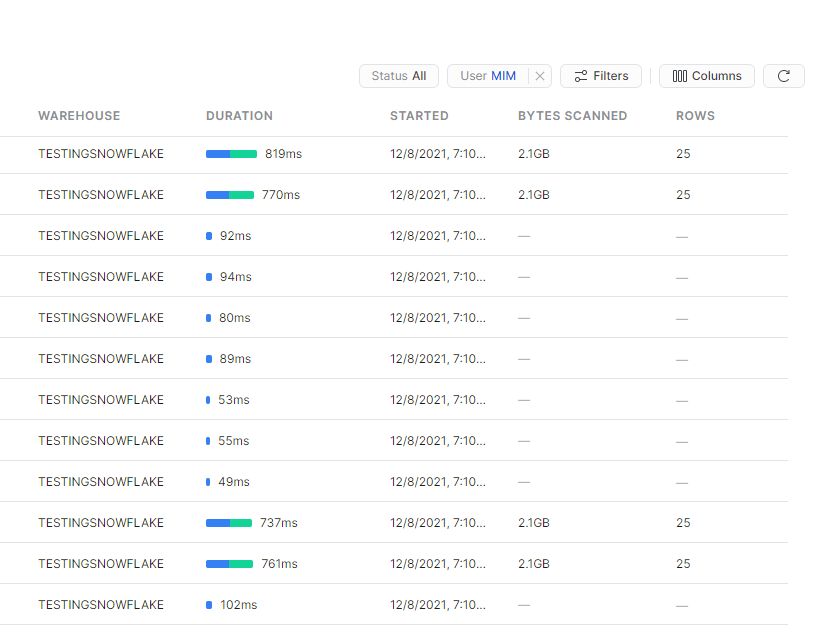
Some results a really intriguing, The ones that don’t have Bytes scanned are cached, but look at this Query that scanned 2.1 GB and returned in 770ms, that’s a BigQuery BI Engine territory right there !!!
The Reason, the Query is in the subsecond, is again because of another type of cache, Snwoflake cache the raw data in the local SSD drive of the cluster, hence it make sense for better performance to keep the Cluster running for a bit longer, if you suspend a Cluster, there is no guarantee that Snowflake will resume the same one.
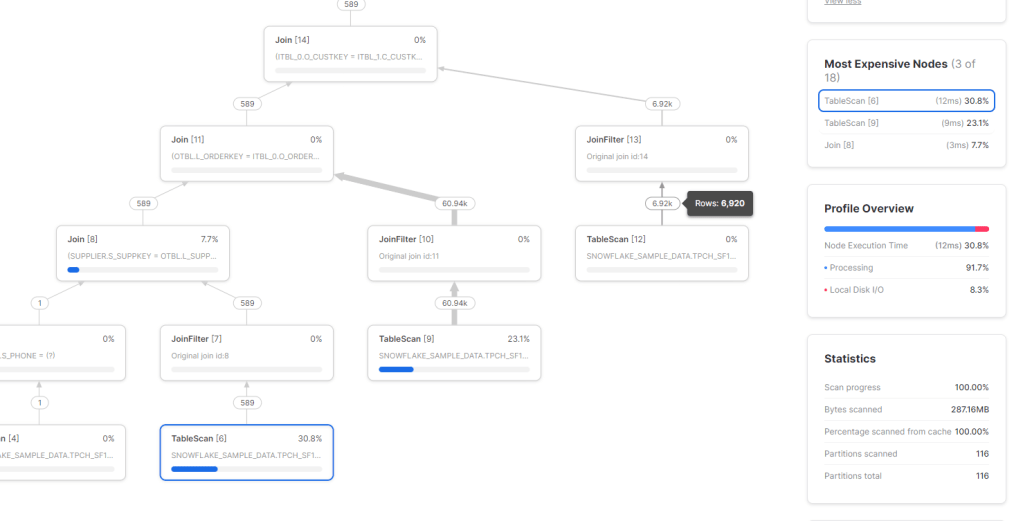
Btw, the Query plan visual is very detailed and explain every step, very nice.
Takeaway
The Quick Auto suspend and resume of Clusters, Global Query result cache and the fact it is a Multi Cloud offering are the key strength of Snowflake.
I was really surprised by the experience of using Snowflake Direct Query with PowerBI, and the data marketplace was a very polished experience.
I will show my bias here , for 2.75 $/Hour I can reserved a BigQuery BI Engine instance with 50 GB in-memory RAM, it will be interesting to compare the performance and concurrency of Both Engine.
Note : if you are using flat price, nothing to see here 🙂
TL; DR : This blog is about a particular use case, assume a customer is using on demand pricing for BigQuery ( 5 $/ TB scanned) and bought some BI Engine reservation (1 $/1 GB compressed/Day), Currently under heavy load, BI Engine fallback to BigQuery, I think it is a problematic behavior and the customer should have the option.
Add the Queries to a Queue, slower but an order of magnitude cheaper
At least have an option to define the behavior.
The Use Case
Let’s say you have a relatively small table and you expect around 20 concurrent users Querying it, using a Live connection from Tableau or Data Studio.
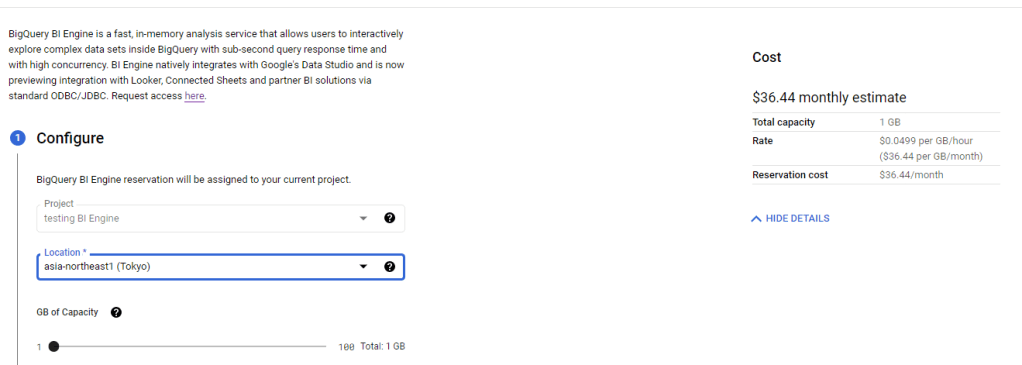
First let’s create 1 GB reservation. ( 36.44 $/Month)
Simulate Query Load
In a previous blog, I got complains that my benchmark is not reproducible, this time, I am using a different Approach, although it is the same base Table ( 74 Million records with new data every 5 minutes) , I am using a SQL Script that run 100 time, every time it generate 5 sequential Queries, and to avoid any cache the date filter is random, something like this
SELECT
StationName,
DAY as date,
sum( Mwh ) AS Mwh
FROM
`test-187010.ReportingDataset.Nem_View`
where DAY >= date_add(DATE "2016-12-25",INTERVAL cast(floor(rand()*100)+1 as INT64) DAY)
GROUP BY
1,
2
ORDER BY
date ASC
Limit 1000
The data is public you can test it yourself, notice it is saved in Tokyo Region, BI Engine should be in the same Region.
The test Load is simple, run the first script and then slowly increasing the number of script running in parallel, the idea is to simulate an increase in concurrency
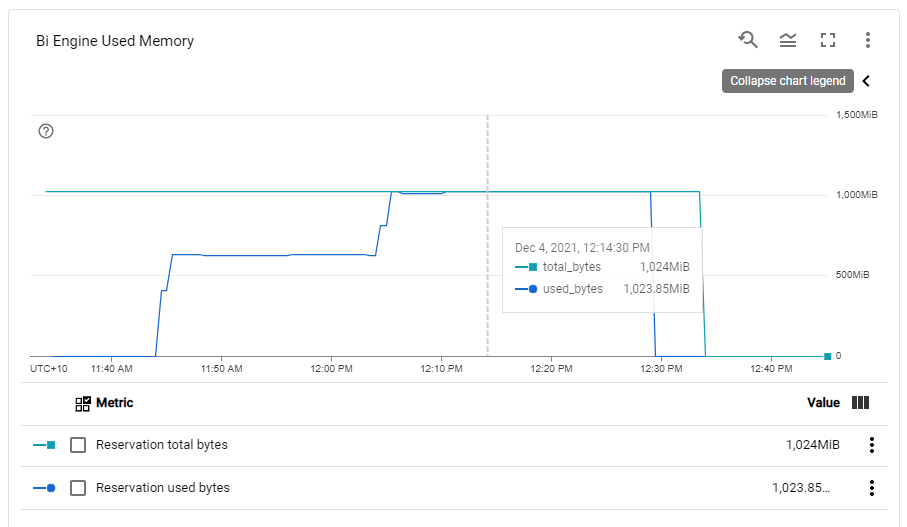
BI Engine consume more memory when the load increase, Very Nice 🙂
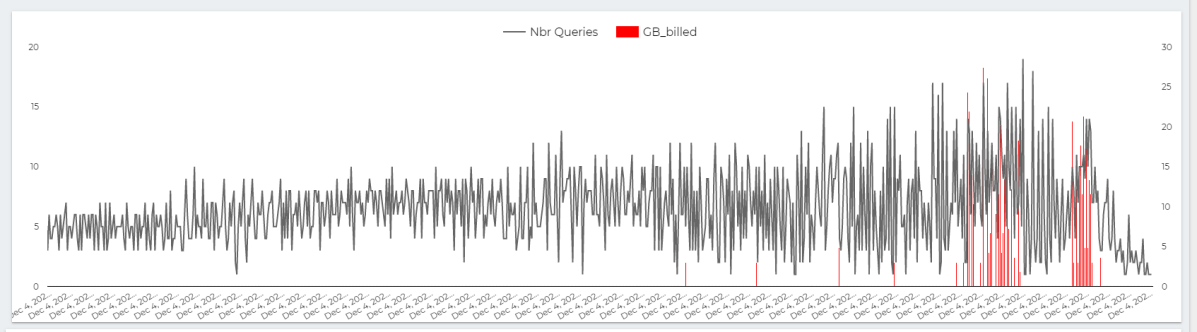
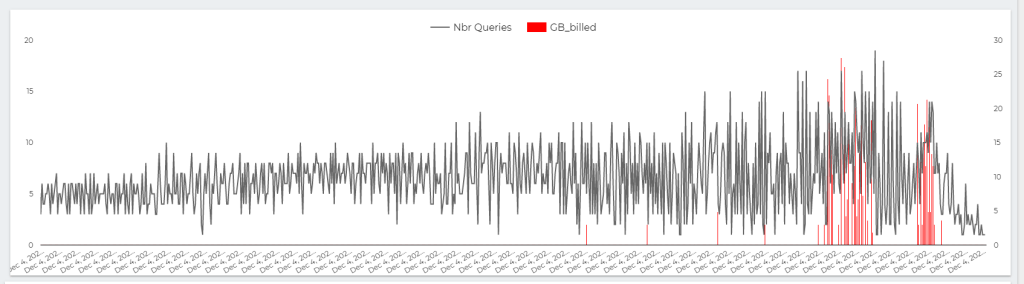
This chart show the number of Queries per second , The Red Line is GB Billed, The red Line is something that worry me a lot.
The whole value proposition of BI engine is the cost, yes it is fast and all but as far as I am concerned, it make Interactive Live BI workload very cost effective, on demanding Pricing is useful for ETL workload, not serving Queries.
Note : you can’t use BI Engine for transformation, saving Query results to a permanent table is not supported.
Here is The Workload Breakdown.
let’s admit the obvious here, BI Engine scanned 22 TB of data in less than an Hour for the cost of 5 cents, it handled the load gracefully, till we start getting 17 concurrent Queries ( your mileage will vary based on the query complexity, volume of data etc etc )
but when BI Engine got overloaded with Queries, it fall back to BigQuery on demanding pricing which in no time consumed the daily Quota ( 500 GB) for a cost of 2.5 $. ( always set up a quota per day)
The Math is very simple, 22 TB for 5 cents versus 0.5 TB for 2.5 $
What‘s the solution
I really would like that BigQuery behavior change, if BI engine is overload, just added the Queries to a Queue to slow down things, or at least make this behavior optional, let the customer decide, if we need more concurrency we can by more memory, but don’t make the decision on our behalf.
PowerBI Vertipaq, which is in the same tech category, handle it differently, if you reach a limit, the Engine will simply throttle the Queries, I think BI Engine should behave the same 🙂
Takeway
For the Previous workload, and to support high level concurrency, and keep a Low cost, the Reserved memory Should be 2 GB, The Good news, the Product Team is working on Auto Scaling, No ETA though.
Disclaimer : this is not a scientific reproducible benchmark.
Edit : TL;DR, don’t use Synapse Serverless with Direct Query mode in PowerBI, it is an extremely bad idea.
One aspect that bother me about technical blogs nowadays, it seems cost is rarely considered, when the subject is about a fixed cost Product like PowerBI Pro license ( 1/user/10$/Month) then it is fine, we know what to expect, but when we talk about usage based Pricing, the cost structure is extremely important, a solution may be great for certain usage load, but it became just exorbitant when the load increases.
One particular architecture that some people start promoting as some kind of magical solution is the use of Synapse Serverless as a logical Data-warehouse, and somehow it can be used too as a live Query layer to PowerBI, I will argue in this blog that this setup is simple too expensive.
Testing Synapse Serverless Indirectly
My thinking is very simple, I was not very excited by the prospect of paying 200 dollars just to test Synapse Serverless, Instead I will test it indirectly, BigQuery BI Engine has a nice functionality that show how much data was scanned, it is for information only, we don’t pay by data scanned but instead in-memory reserved ( 1$/GB compressed/Day, minimum 1 hour).
The approach here is to get the volume of Data scanned and multiply it by 5$/TB (Synapse serverless Pricing) , I appreciate it is not 100 % accurate, but I hope will show a general pattern.
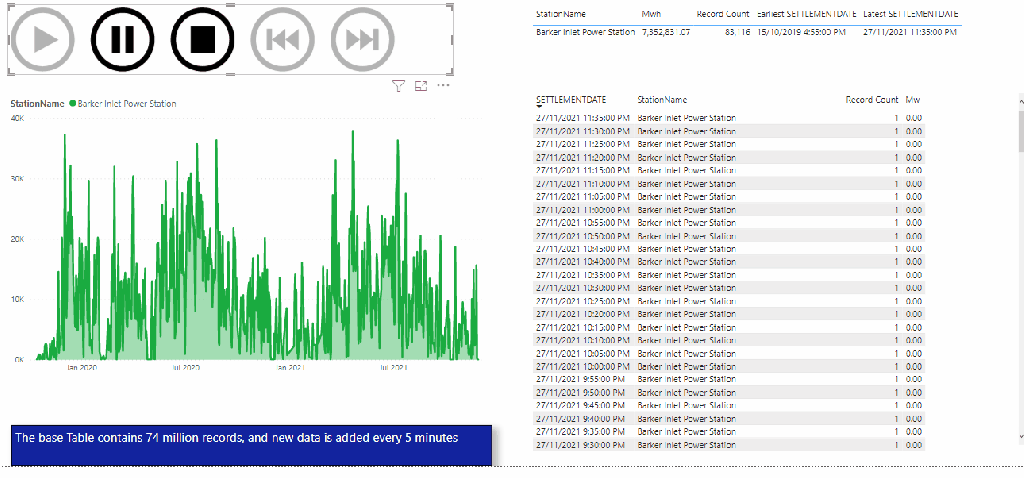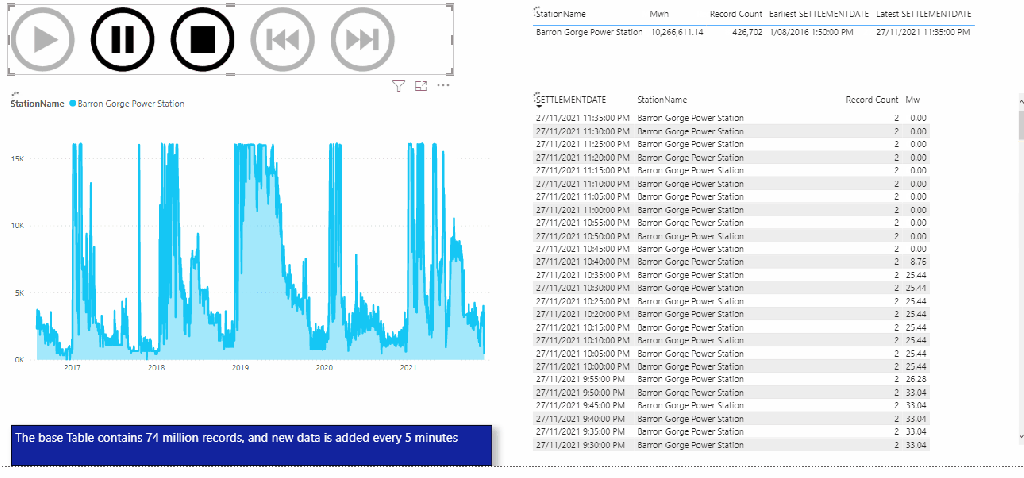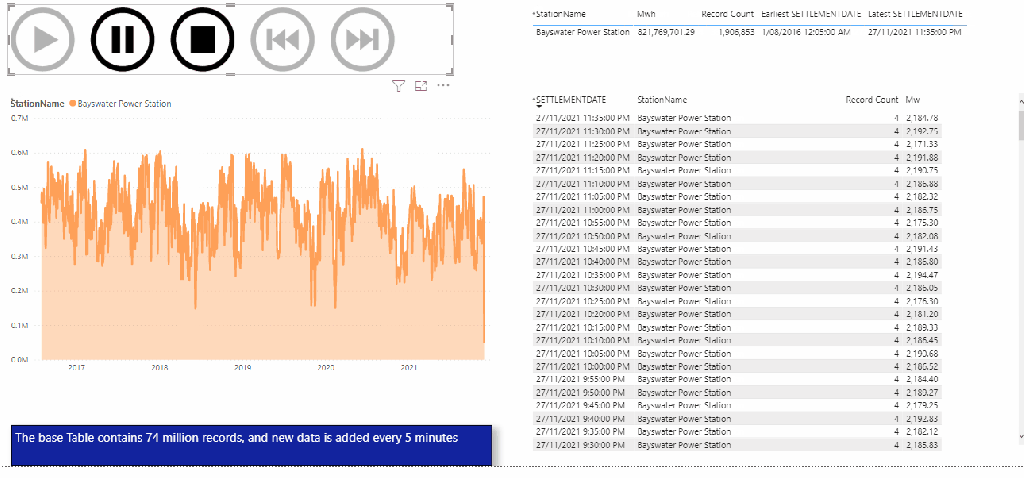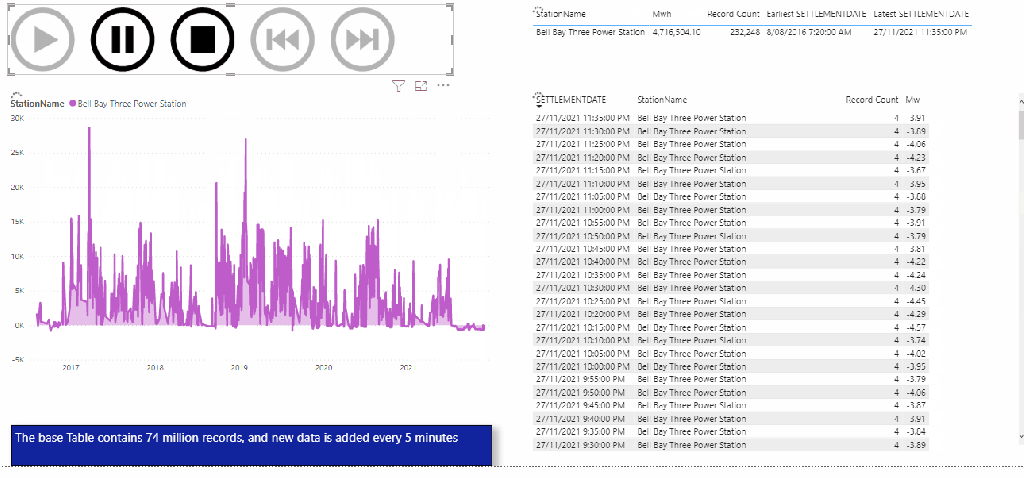
Load test using a PowerBI report
The Fact table is 12 GB, 72 Millions rows that get data add every 5 minutes, the Model is a simple Star Schema, I am using dual mode for the dimension Tables
The test consist of using play Axis to loop on some dimension values every 5 second, I launched multiple copy of the same reports to generate more SQL Queries.
The Results
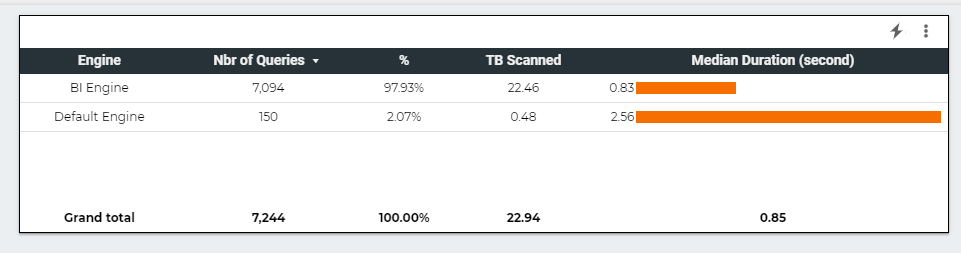
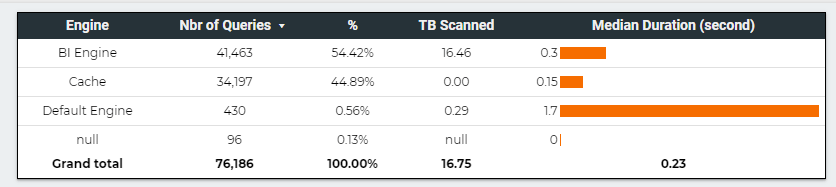
This table summarize the test results , more details in the report , please keep the filter between 22 Nov and 27 Nov 2021, as testing was done in that period.
BigQuery BI engine is very fast, but that’s not the subject of the current blog, what’s interesting here is the volume of data scanned 16,75 TB, that’s a lot of data, which does not count for the cache.
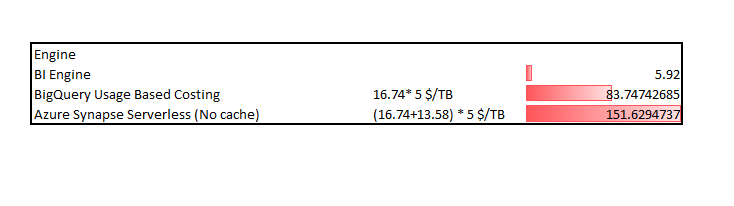
For simplification purpose we estimate the cache to be the same ratio as scanned TB (16.46 * 44.89 %/54.42 %) = 13.58 TB
Synapse Serverless is 25 X more expensive than BigQuery BI Engine, and even if they add the result set cache it will be still 14 X more expensive ( Same as BigQuery without reservation)
Key findings
Interactive BI reports generate a massive number of SQL Queries, in our example, it was 76K Queries, which simply make SQL Engine that are cost based on data scanned too Much expensive.( Synapase Serverless and BigQuery default mode)
This scenario will be better served by a dedicated capacity, but as of this writing Synapse does not support auto suspense and auto resume which make it too expensive , and in any case, Synapse dedicated pool does not scale down well for small data ( hopefully Gen3 will fix that)
BigQuery BI Engine make Direct Query on PowerBI a viable solution, which is a great achievement and still with very competitive pricing.
Synapse Serverless is an interesting SQL Query Engine, but it not designed for heavy interactive BI load, I just hope people stop suggesting otherwise.
I think next year the battle for 100 GB interactive sub second BI workload will be an interesting space to watch, let’s see what Dedicated Pool Gen 3 , Databricks, Snowflake and Firebolt will bring to the table 🙂