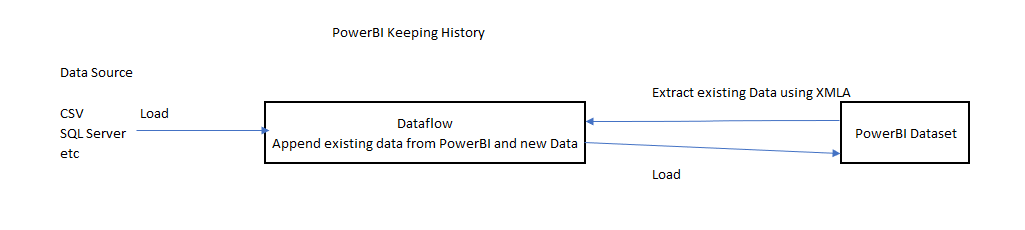
I have a bit of an obsession with Modeling language, I am referring to semantic model language like PowerBI tabular Model , Looker LookML and the new alpha release of dbt metrics and Google Malloy
For some reason, TML the modeling language of thoughtspot is not getting enough attention, although IMO, it is one of the most mature offering right now in the so called “Modern” Data Stack.
This is not a review, I spend some time in the weekend playing with the free trial, (no credit card required , and you don’t need to talk to a sales department) and I thought it is worth sharing some notes.
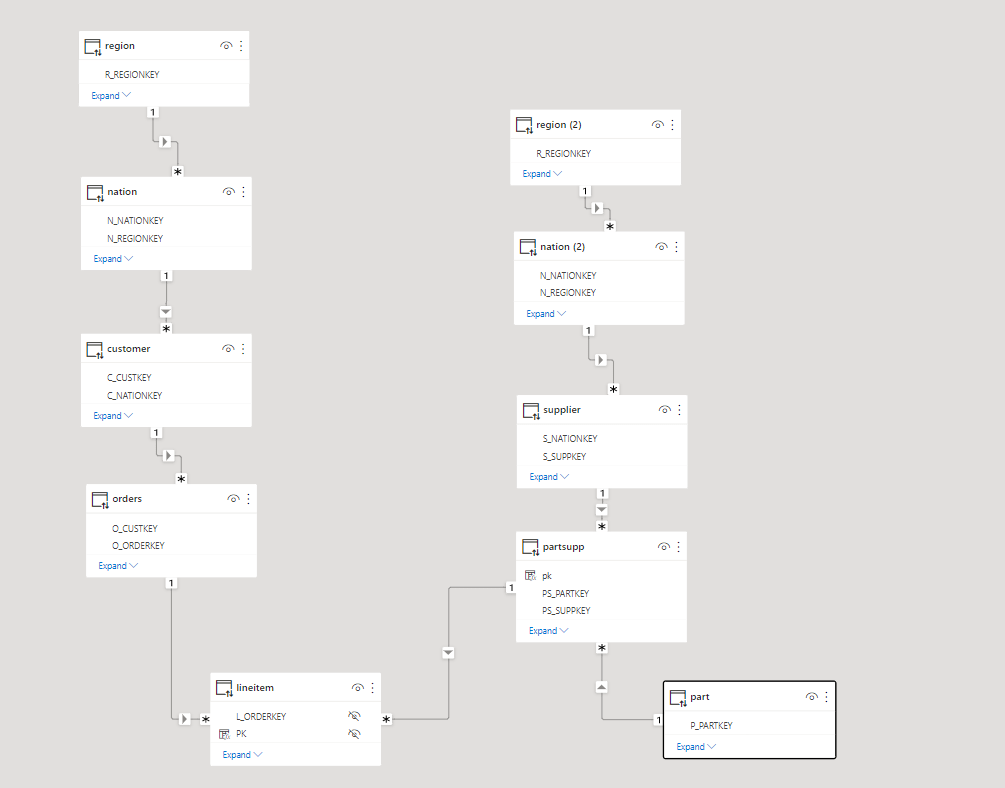
For Any test, I always start with the same Model, 3 facts tables with different granularity and a couple of common dimensions, because this is the kind of Model I use at Work with PowerBI.
My Data is loaded into BigQuery, connecting to the database in Live Mode and selecting the Tables was very straightforward, adding the relationship between Tables was very easy too, using a simple GUI.
Here we go, a Multi facts ( AKA Galaxy Schema ) is supported out of the box, in other BI tool Like Tableau for example, you can have only 1 Base Table, here like PowerBI it is not an issue.
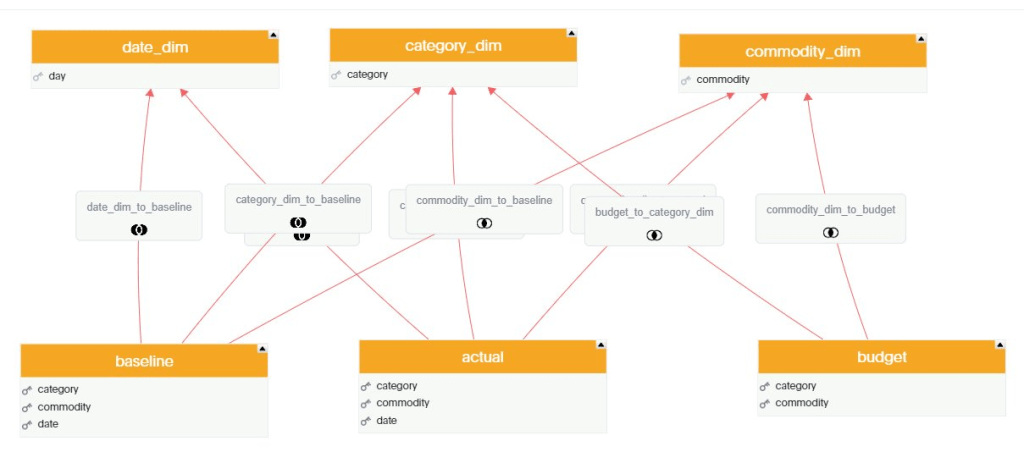
The Join between Tables are Progressive, only the joins need between the selected columns in the visual will be used.
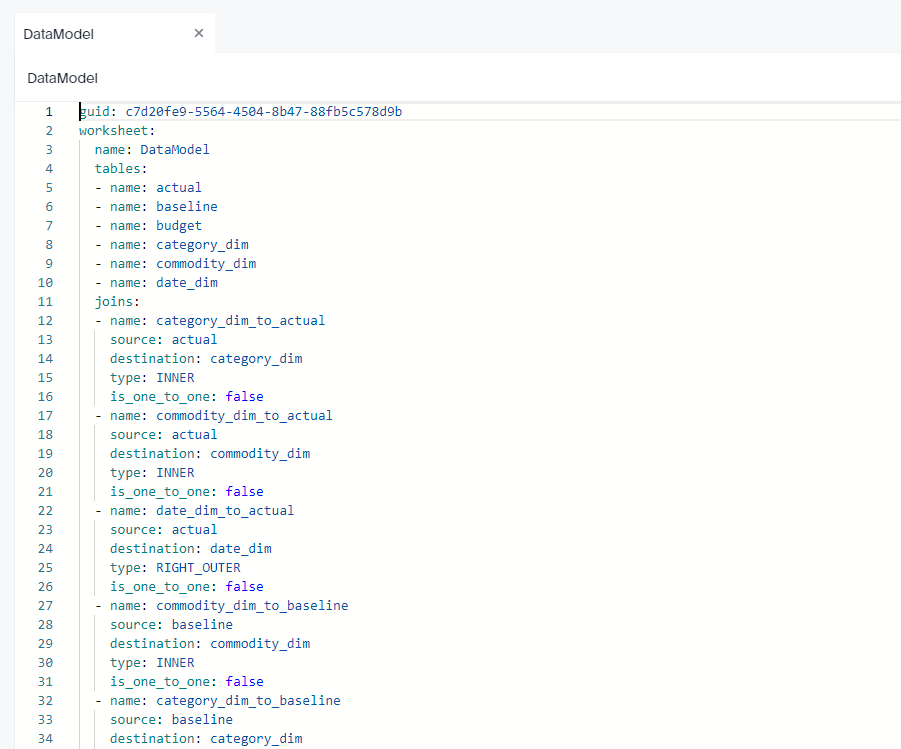
Although I build the Model using GUI, the code is written behind the scene, you can build it by hand or edit it, or simply import it.
Complex Measures
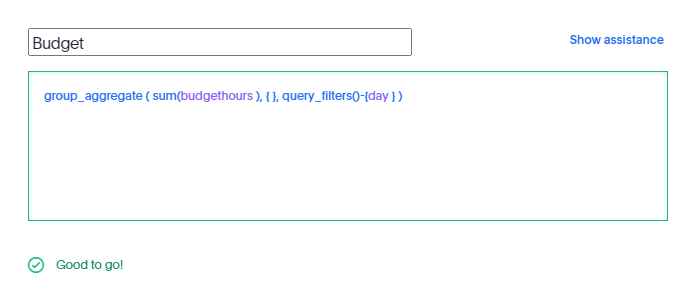
in this Model the table Budget don’t have a date dimension ( 1 Km of Electric cable is the same independent of time), to model that, I need to tell TML that the measure budget should ignore the date dimension
Calculating cumulative sum is straightforward,
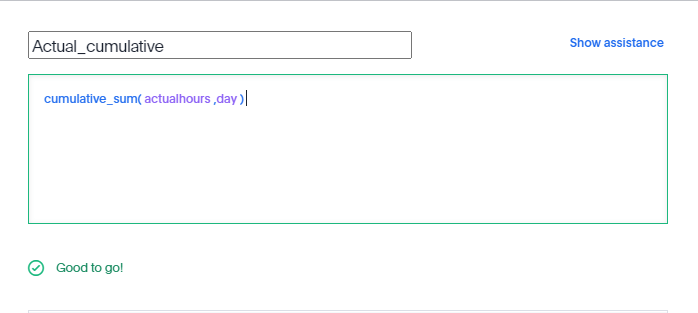
All sort of level of details calculation are supported, including measures from different tables.
All SQL
As far as I can tell and based on the SQL Generated by Thoughtspot , there no Post processing for the calculation, Like PowerBI Formula Engine and Looker Merge results, all the calculations are done at the Source Database level, there is even a very nice visual Query Planner

And here is an example of the Query generated, I think it use the concept of Drill across
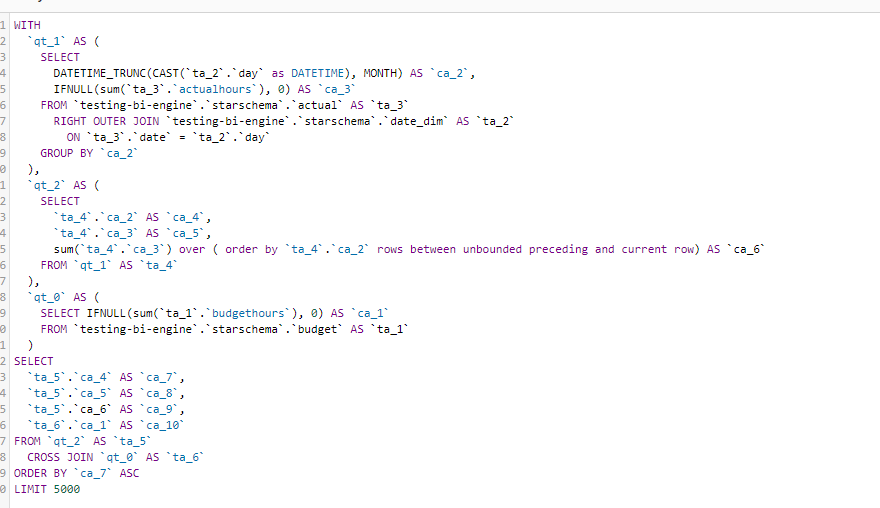
You can see how sum cumulative was translated to SQL sum () over (order by)
Take Away
There is a lot of discussion nowadays about the need for a pure logical metric layer, where all the calculations are done by the DWH, unfortunately most of the proposals are either immature or sometimes are just magical thinking, TML is a damn solid language and a Query generator, and the guys building it knows what they are talking about.
I think if thoughtspot somehow decide to release TML as an open source Project with the Query generator it will change the current market dynamic, The Cloud Data Warehouse are getting really Fast and they deserve a decent Semantic Layer.