Alright using the term “idempotent” was just a clickbait 🙂 it simply means avoiding the processing of the same file multiple times ( ok for a formal definition wikipedia has a nice article). in this case the script will process only new files added to the source system, assuming the filenames are unique.
Although this is easily accomplished using Python API , achieving the same result using DuckDB SQL was a bit tricky until the introduction of SQL variables in the developpement branch a couple of weeks ago, particularly Variables can now be referenced within read files operation.
in summary this is what the SQL script is doing.
- Creation of a Hive table in the file section of onelake, it is very important step, if you query an empty folder you will get an error, , as DuckDB does not support external table, we will just add a dummy parquet file with empty rows, it is filtered out in the next step.
COPY (
SELECT
'' AS filename,
NULL AS year ) TO "/lakehouse/default/Files/scada" (FORMAT PARQUET,
PARTITION_BY (year),
OVERWRITE_OR_IGNORE ) ;- Listing of CSV files for ingestion from the source system.
- Removal of already ingested files
SET
VARIABLE list_of_files = (
SELECT
list(file)
FROM
glob("/lakehouse/default/Files/Daily_Reports/*.CSV")
WHERE
parse_filename(file) NOT IN (
SELECT
filename
FROM
read_parquet("/lakehouse/default/Files/scada/*/*.parquet")))- Generate list of new files and pass it to DuckDB for processing.
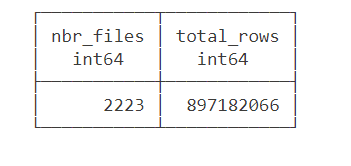
just a preview of the query plan for this step

- Saving as partitioned Hive parquet folders
Note : I am using Fabric notebook as an example, but obviously you can run it anywhere, actually I did it run in my laptop and as far as I can tell, Onelake throughput is competitive with my ssd disk 🙂
COPY (
SELECT
'' AS filename,
NULL AS year ) TO "/lakehouse/default/Files/scada" (FORMAT PARQUET,
PARTITION_BY (year),
OVERWRITE_OR_IGNORE ) ;
SET
VARIABLE list_of_files = (
SELECT
list(file)
FROM
glob("/lakehouse/default/Files/Daily_Reports/*.CSV")
WHERE
parse_filename(file) NOT IN (
SELECT
filename
FROM
read_parquet("/lakehouse/default/Files/scada/*/*.parquet"))) ;
CREATE OR REPLACE VIEW
raw AS (
SELECT
*
FROM
read_csv(getvariable('list_of_files'),
Skip=1,
header =0,
all_varchar=1,
COLUMNS={ 'I': 'VARCHAR',
'UNIT': 'VARCHAR',
'XX': 'VARCHAR',
'VERSION': 'VARCHAR',
'SETTLEMENTDATE': 'VARCHAR',
'RUNNO': 'VARCHAR',
'DUID': 'VARCHAR',
'INTERVENTION': 'VARCHAR',
'DISPATCHMODE': 'VARCHAR',
'AGCSTATUS': 'VARCHAR',
'INITIALMW': 'VARCHAR',
'TOTALCLEARED': 'VARCHAR',
'RAMPDOWNRATE': 'VARCHAR',
'RAMPUPRATE': 'VARCHAR',
'LOWER5MIN': 'VARCHAR',
'LOWER60SEC': 'VARCHAR',
'LOWER6SEC': 'VARCHAR',
'RAISE5MIN': 'VARCHAR',
'RAISE60SEC': 'VARCHAR',
'RAISE6SEC': 'VARCHAR',
'MARGINAL5MINVALUE': 'VARCHAR',
'MARGINAL60SECVALUE': 'VARCHAR',
'MARGINAL6SECVALUE': 'VARCHAR',
'MARGINALVALUE': 'VARCHAR',
'VIOLATION5MINDEGREE': 'VARCHAR',
'VIOLATION60SECDEGREE': 'VARCHAR',
'VIOLATION6SECDEGREE': 'VARCHAR',
'VIOLATIONDEGREE': 'VARCHAR',
'LOWERREG': 'VARCHAR',
'RAISEREG': 'VARCHAR',
'AVAILABILITY': 'VARCHAR',
'RAISE6SECFLAGS': 'VARCHAR',
'RAISE60SECFLAGS': 'VARCHAR',
'RAISE5MINFLAGS': 'VARCHAR',
'RAISEREGFLAGS': 'VARCHAR',
'LOWER6SECFLAGS': 'VARCHAR',
'LOWER60SECFLAGS': 'VARCHAR',
'LOWER5MINFLAGS': 'VARCHAR',
'LOWERREGFLAGS': 'VARCHAR',
'RAISEREGAVAILABILITY': 'VARCHAR',
'RAISEREGENABLEMENTMAX': 'VARCHAR',
'RAISEREGENABLEMENTMIN': 'VARCHAR',
'LOWERREGAVAILABILITY': 'VARCHAR',
'LOWERREGENABLEMENTMAX': 'VARCHAR',
'LOWERREGENABLEMENTMIN': 'VARCHAR',
'RAISE6SECACTUALAVAILABILITY': 'VARCHAR',
'RAISE60SECACTUALAVAILABILITY': 'VARCHAR',
'RAISE5MINACTUALAVAILABILITY': 'VARCHAR',
'RAISEREGACTUALAVAILABILITY': 'VARCHAR',
'LOWER6SECACTUALAVAILABILITY': 'VARCHAR',
'LOWER60SECACTUALAVAILABILITY': 'VARCHAR',
'LOWER5MINACTUALAVAILABILITY': 'VARCHAR',
'LOWERREGACTUALAVAILABILITY': 'VARCHAR' },
filename =1,
null_padding = TRUE,
ignore_errors=1,
auto_detect=FALSE)
WHERE
I='D'
AND UNIT ='DUNIT'
AND VERSION = '3' ) ; COPY (
SELECT
UNIT,
DUID,
parse_filename(filename) AS filename,
CAST(COLUMNS(*EXCLUDE(DUID,
UNIT,
SETTLEMENTDATE,
I,
XX,
filename)) AS double),
CAST (SETTLEMENTDATE AS TIMESTAMPTZ) AS SETTLEMENTDATE,
isoyear (CAST (SETTLEMENTDATE AS timestamp)) AS year
FROM
raw) TO "/lakehouse/default/Files/scada" (FORMAT PARQUET,
PARTITION_BY (year),
APPEND ) ;While the Python API in a notebook is IMHO the easiest approach for data transformation, it is nice to see that Pure SQL can support it.

However, the real game-changer will be when DuckDB introduces support for Delta write. for now, you need another step to load those Parquet files to Delta either using Deltalake Python package or Spark Delta writer.