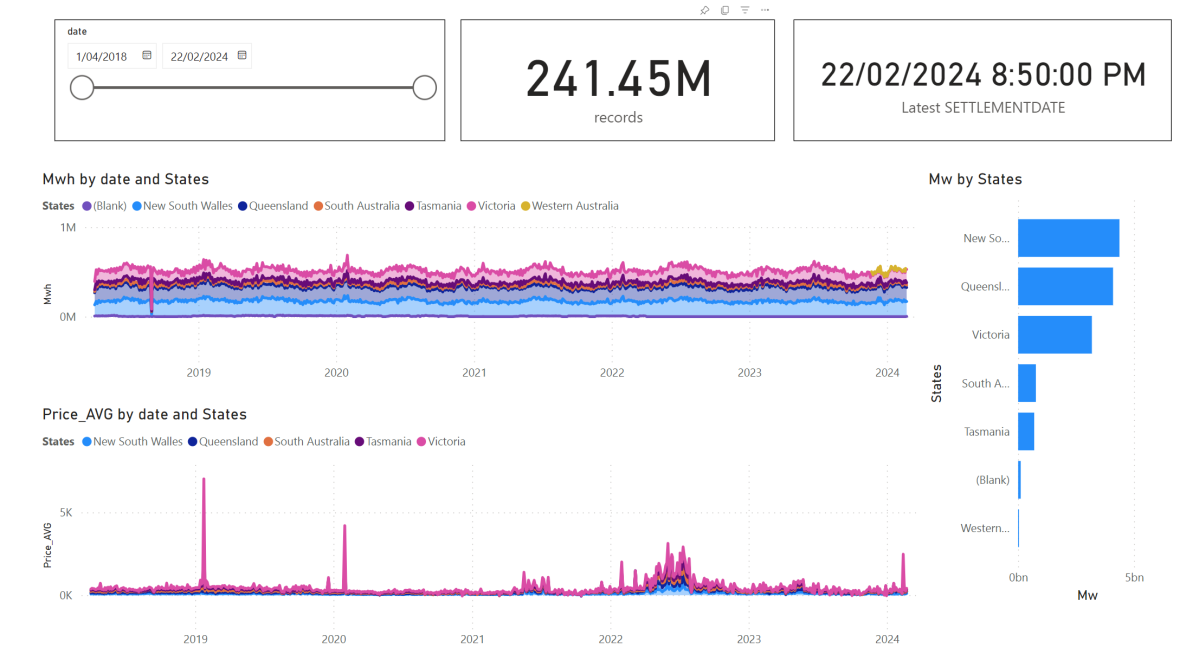
I have being playing with Electricity Market Data recently and now I have a #Fabric solution that I think is easy enough to use but more importantly cost effective that it works just fine using F2 SKU, which cost $156 /Month
https://github.com/djouallah/aemo_fabric
Howto
0- Create a Fabric Workspace
1- Create a lakehouse
2-Download the notebooks from Github and import it to Fabric Workspace
3-Open a notebook, attached it to the Lakehouse
4-Run the notebook in sequence just to have the initial load
5-Build your semantic Model either using Direct Lake for better “latency” , or use the attached template for import mode if you are happy with 8 refreshes per day( for people with a pro license), all you need is to input the Lakehouse SQL Endpoint, my initial plan was to read Delta Table directly from OneLake but currently filter pushdown works only at the partition level ( but apparently further stuff are coming)
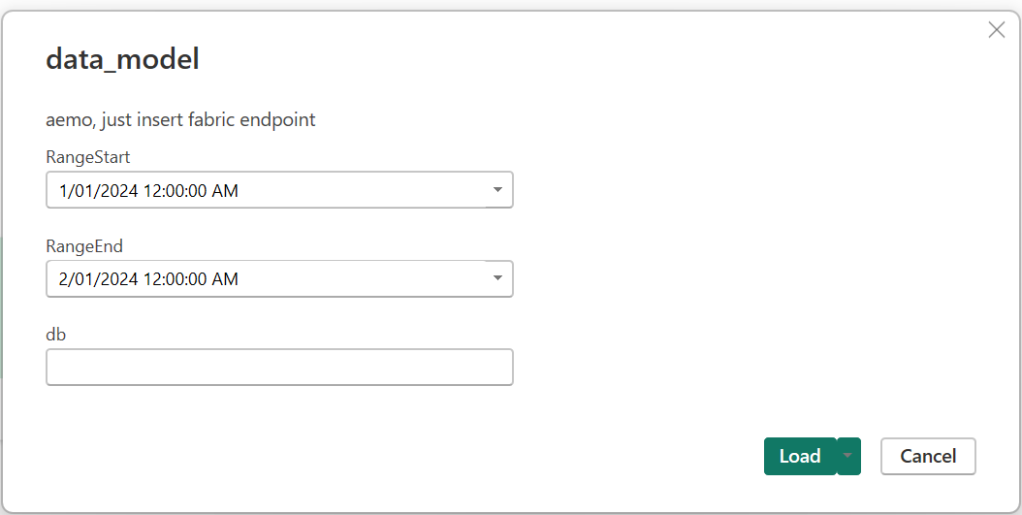
6- Use a scheduler to run the jobs, 5 minutes and 24 Hours
Show me the Money
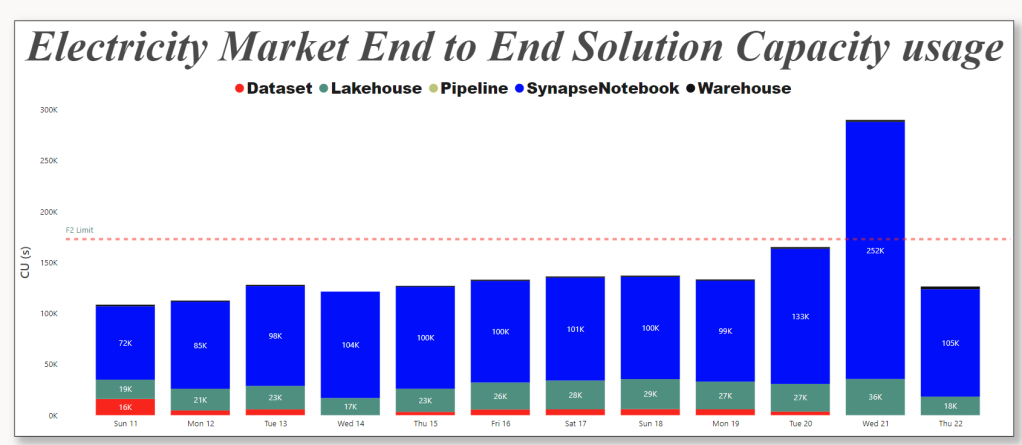
For developpement use Starter Pool, but for scheduling use Small Single Node, it is good enough, medium is faster but will consume more capacity Unit, still within F2 limits.
This is the actual usage of capacity unit for this scenario, yesterday I was messing around trying to further optimize which end up consuming more 🙂
Spark Dataframe API is amazing
When reading the csv files, I need to convert a lot of columns to double, using SQL you have to manually type all the fields names, in Spark , you can just do it in a loop, that was the exact moment, I *understood* why people like Spark API !!!
df_cols = list(set(df.columns) -{'SETTLEMENTDATE','DUID','file','UNIT','transactionId','PRIORITY'})
for col_name in df_cols:
df = df.withColumn(col_name, f.col(col_name).cast('double'))Source Data around 1 Billion of dirty csv, data added every 5 minutes and backfilled every 24 hours, all data is saved in OneLake using Spark Delta Table.
not everything is csv though, there is some data in Json and Excel of course 🙂
Although the main code is using PySpark , I used Pandas and DuckDB too, no philosophical reasons, basically I use whatever Stackoverflow give me first 🙂 and then I just copy the result to a Spark dataframe and save it as Delta Tables, you don’t want to miss on VOrder
For example this is the code to generate a calendar Table using DuckDB SQL, the unnest syntax is very elegant !!!
df=duckdb.sql(""" SELECT cast(unnest(generate_series(cast ('2018-04-01' as date), cast('2024-12-31' as date), interval 1 day)) as date) as date,
EXTRACT(year from date) as year,
EXTRACT(month from date) as month
""").df()
x=spark.createDataFrame(df)
x.write.mode("overwrite").format("delta").saveAsTable("Calendar")The Semantic Model
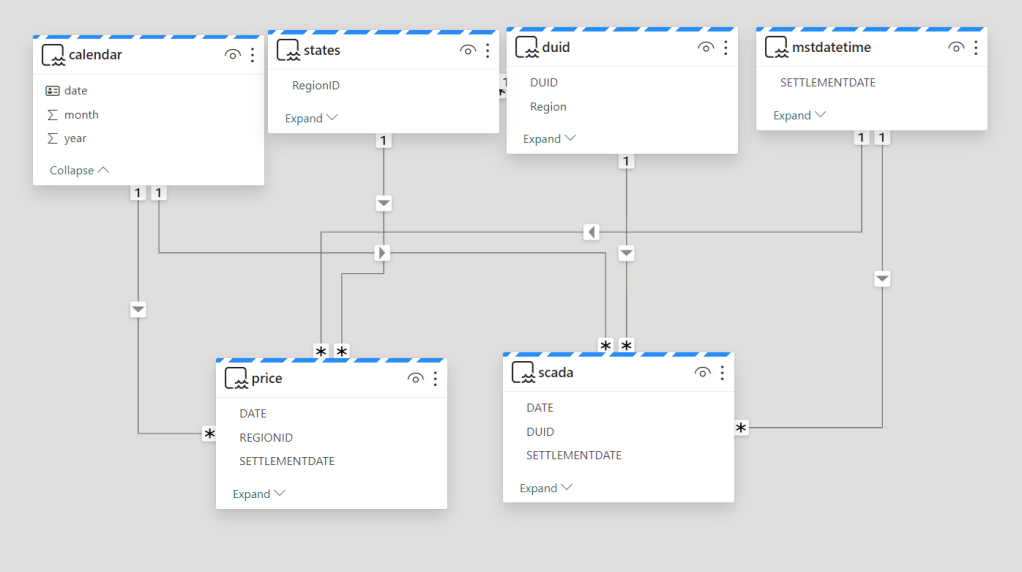
The Model is not too complex but not trivial, 2 facts tables, 4 dimensions, biggest table 240 M rows.
Stuff that needs improvements
1- have an option to download the semantic Model from the service using pbit, it has to be one file for ease of distribution.
2- More options for the scheduler, something like run this job only between 8 AM to 6 PM every 5 minutes.
Parting Thoughts
Notebook + OneLake + Direct Lake is emerging as a very Powerful Pattern , specially when the data is big and freshness is important, but somehow users needs to learn how to write Python code, I am afraid that’s not obvious at all for the average data analyst, maybe this AI thing can do something about ? that’s the big question.
Does it mean, Notebook is the best solution for all use cases ? I don’t know, and I don’t think there is such a thing as a universal best practice in ETL, as far as I am concerned, there is only one hard rule.
Save raw data when the source system is volatile.
anything else is a matter of taste 🙂
