
I was watching a Video by Alberto regarding the best way to model Header/Details Schema and how Star Schema is always the best option at least in PowerBI , even if you have never used PowerBI I think it is a great video to watch.
An interesting information I learned from the Video, although PowerBI columnar database is extremely fast in joins, still when the join column has a massive number of distinct values, performance will degrade, in his case, one of the fact has 1.4 B rows and 94 million distinct values on the join !!!, the solution was basically to flatten the two fact Tables.
ok, what this has to do with BigQuery !! for some reason, an idea occurred to me, this scenario will be a perfect scenario for Nested Data, but as I never used nested data before, in this blog, I am just messing around and see how it goes !!!
The Dataset
As usual, I will use the Australia electricity market as an example, it has 72 Million records with a size of 10 GB uncompressed, here is a sample f the Data, the dataset is public using this adreess
“test-187010.ReportingDataset.UNITARCHIVE”

As you can see the same attribute is repeated for every 5 minutes, what change is the date and the production in Mw
let’s see how it looks as a nested format
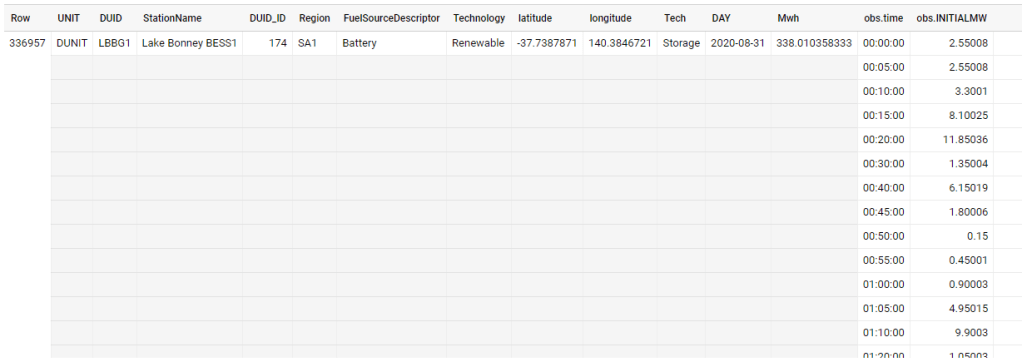
in a pure denormalized form they are two tables in reality, the dimension which contains the generator attribute and the production every 5 minutes

How to Nest data in BigQuery
I literally copied from this blog by Lak, just go and read it, I will just show the SQL Query here
drop table if exists XXXXX.nested.UNITARCHIVE_nested;
CREATE OR REPLACE TABLE
XXXXX.nested.UNITARCHIVE_nested
PARTITION BY
RANGE_BUCKET(DUID_ID, GENERATE_ARRAY(1,4000, 1))
CLUSTER BY StationName,DAY
AS
SELECT
UNIT,
tt.DUID,
StationName,
DUID_ID,
Region,
FuelSourceDescriptor,
Technology,
latitude,
longitude,
Tech,
DAY,
cast(SUM(mwh) as numeric) AS Mwh,
ARRAY_AGG(STRUCT( time,
INITIALMW)
ORDER BY
time ASC) AS obs
FROM
test-187010.ReportingDataset.UNITARCHIVE tt
left join (select DUID,row_number() over() as DUID_ID
FROM
test-187010.ReportingDataset.UNITARCHIVE
group by 1 ) as xx
on tt.DUID=XX.duid
WHERE
unit="DUNIT"
GROUP BY
1,
2,
3,
4,
5,
6,
7,
8,
9,
10,
11
Compare Performance
For the same level of details, the size went from 10.1 GB to 1.13 GB !!! the cost of storage is rather insignificant, but if you use Query on demand, you pay by size scanned, the less the better.

Let’s check the total sum of Mwh , the same Query went from 1.1 GB to 5.1 MB !!! that nearly 100 X Cheaper ( in BigQuery you pay a minimum of 10 MB)

let’s check the 5 top days by production, same went from 1.6 GB to 7.7 MB that’s 160 X Cheaper , and faster too from 0.9 Second to 0.6 Second, it is funny both return subsecond results and it is not cached 🙂

What’s the catch !!!
There is a catch though, when you Query inside the Nested Data, the performance is nearly the same, went from 1.6 GB to 1.1 GB still it is a saving of 0.5 GB, but what surprised me, unnesting is a bit faster than reading from flat data, I was expecting the opposite

Visualise the Results in your Favorite BI Tools
I am using PowerBI to show the final results, using Direct Query Mode, the Dimensions are Imported to improve the slicer performance, Obviously it works with any BI tools that support SQL.
Looker has a nice support for nested data, unfortunately there is no free version to test it.
As of this Writing BI Engine does not support Unnest Data,Hopefully they fix the issue very soon., Nice, it is supported under BI Engine SQL Interface !!!!

And a sample report using nested data (5 minute Dimension)

Take Away
let’s say you have a Header and details tables, there are some options
- Join at run time in the BI tools, can be slow for high cardinality joins
- Merge the two Fact at the ETL Stage, very fast but potentially generate multiple grains and you need to using distinct count to remove duplicates
- Nested Data seems to be very elegant solution, no joins and you keep the granularity and it is cheaper to Query

One thought on “Model Header/Details Schema using Nested Data in BigQuery”