Just sharing a notebook on how to load an iceberg table to ADLSGen2, I built it just for testing iceberg to delta conversion.
Unlike Delta, Iceberg requires a catalog in order to write data, there are a lot of options, from sqlite to full managed service like Snowflake Polaris, unfortunately pyiceberg has a bug when checking if a table exists in Polaris, the issue was fixed but it is not released yet.
SQLite is just local db, and I wanted to read and write those tables using my laptop and Fabric notebook, fortunately PostgreSQL is supported
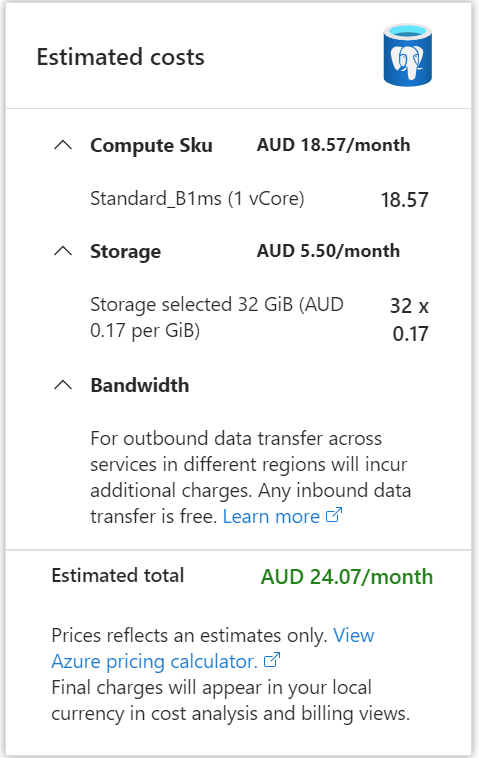
I spinned up a PostgreSQL DB in Azure, I used the cheapest option possible, notice here, iceberg catalog doesn’t store any data, just a pointer to the latest snapshot, the DB is used for consistency guarantee not data storage.
Anyway, 24 AU $/ Month is not too bad.
My initial plan was to use Daft for data preparation as it has a good integration with Iceberg catalog, unfortunately as of today, it does not support adding filename as a column in the table destination, so I endup using Duckdb for data preparation and Daft for reading from the catalog.
Daft added support for adding filename when reading from csv, so, it is used both for reading and writing.
The convenience of the catalog
what I really like about the catalog is the ease of use, you just need to initiate the catalog connection once.
def connect_catalog():
catalog = SqlCatalog(
"default",
**{
"uri" : postgresql_db,
"adlfs.account-name" : account_name ,
"adlfs.account-key" : AZURE_STORAGE_ACCOUNT_KEY,
"adlfs.tenant-id" : azure_storage_tenant_id,
"py-io-impl" : "pyiceberg.io.fsspec.FsspecFileIO",
"legacy-current-snapshot-id": True
},
)
return catalog The writing is just one line of code, you don’t need to configure storage again
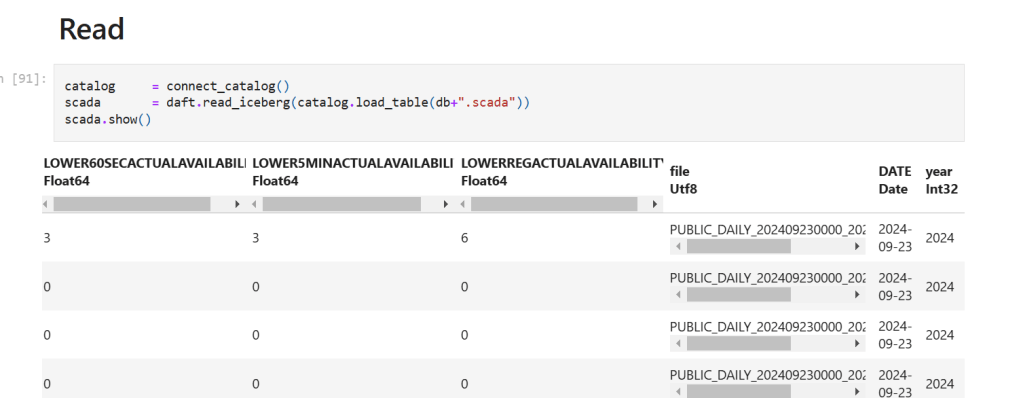
For writing , you just use something like this
catalog.create_table_if_not_exists('tbl', schema=df.schema, location=table_location + f'/{db}/{tbl}')
catalog.load_table(f'{db}.{tbl}').append(df)