TL;DR : using Fabric Python Notebook to Sort and Save Parquet files up to 100 GB shows that DuckDB is very competitive compared to Spark even when using Only half the resources available in a compute pool.
Introduction :
In Fabric the minimum Spark compute that you can provision is 2 nodes, 1 Driver and 1 Executor, my understanding, and I am not an expert by any means is : Driver Plan the Work and Executor do the actual Works, but if you run any no Spark code, it will run in the driver, basically DuckDB use only the driver, the executor is just sitting there and you pay for it.
The experiment is basically : generate the Table Lineitem from the TPCH dataset as a folder of parquet files and sort it on a date field then save it. Pre-sorting the data on a field used for filtering is a very well known technique.
Create a Workspace
When doing POC, it is always better to start in a new workspace, at the end you can delete it and it will remove all the artifacts inside it. Use any name you want.
Create a Lakehouse
Click New then Lakehouse, choose any name

You will get an empty lakehouse (it is a just a storage bucket with two folders, Files and Table)
Load the Python Code
The Notebook is straightforward, Install DuckDB , create the data files if they don’t exist already, sort and save in a delta table using both DuckDB and Spark

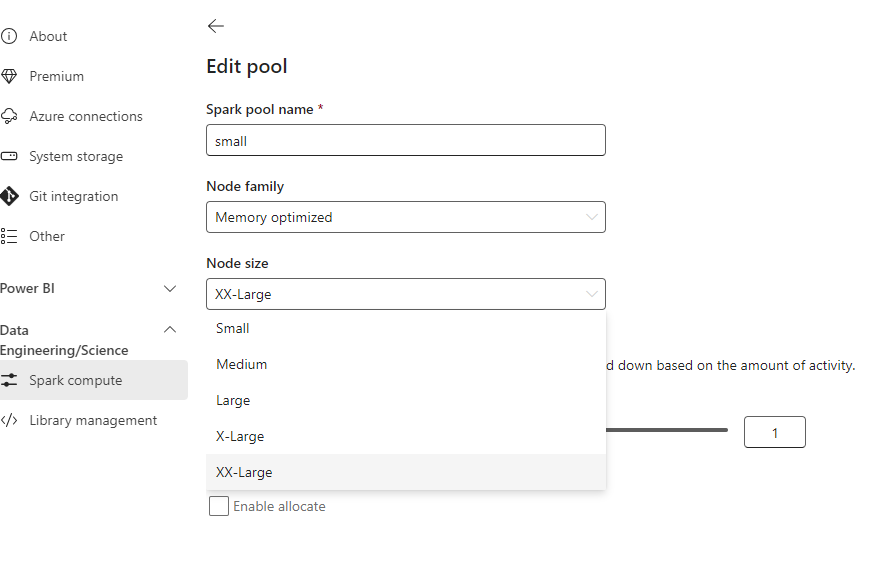
Define Spark Pool Size
By default the notebook came with a starter pool that are warm and ready to be used, the startup is in my experience is always less than 10 second, but it is a managed service and I can’t control the number of nodes, instead we will use custom pool where you can choose the size of the compute and the number of nodes in our case 1 driver and 1 executor, the startup is not bad at all, it is consistently less than 3 minute.
Schedule the Notebook
I don’t not know, how to pass a parameter to change the initial value in the pipeline, so I run it using a random number generator`, I am sure there is a better way, but anyway, it does works, and every insert the results

The Results
The Charts show the resource usage by data size, CPU(s) = Duration * Number of cores * 2.

Up to 300 Million rows, DuckDB is more efficient even when it is using only half the resources.
To make it clearer , I build another chart that show the Engine combination with less resource utilization by Lintem size

From 360 Million rows, Spark became more economical ( with the caveat that DuckDB is just using half the resources) or maybe DuckDB is not using the whole 32 cores ?
Let’s filter only DuckDB
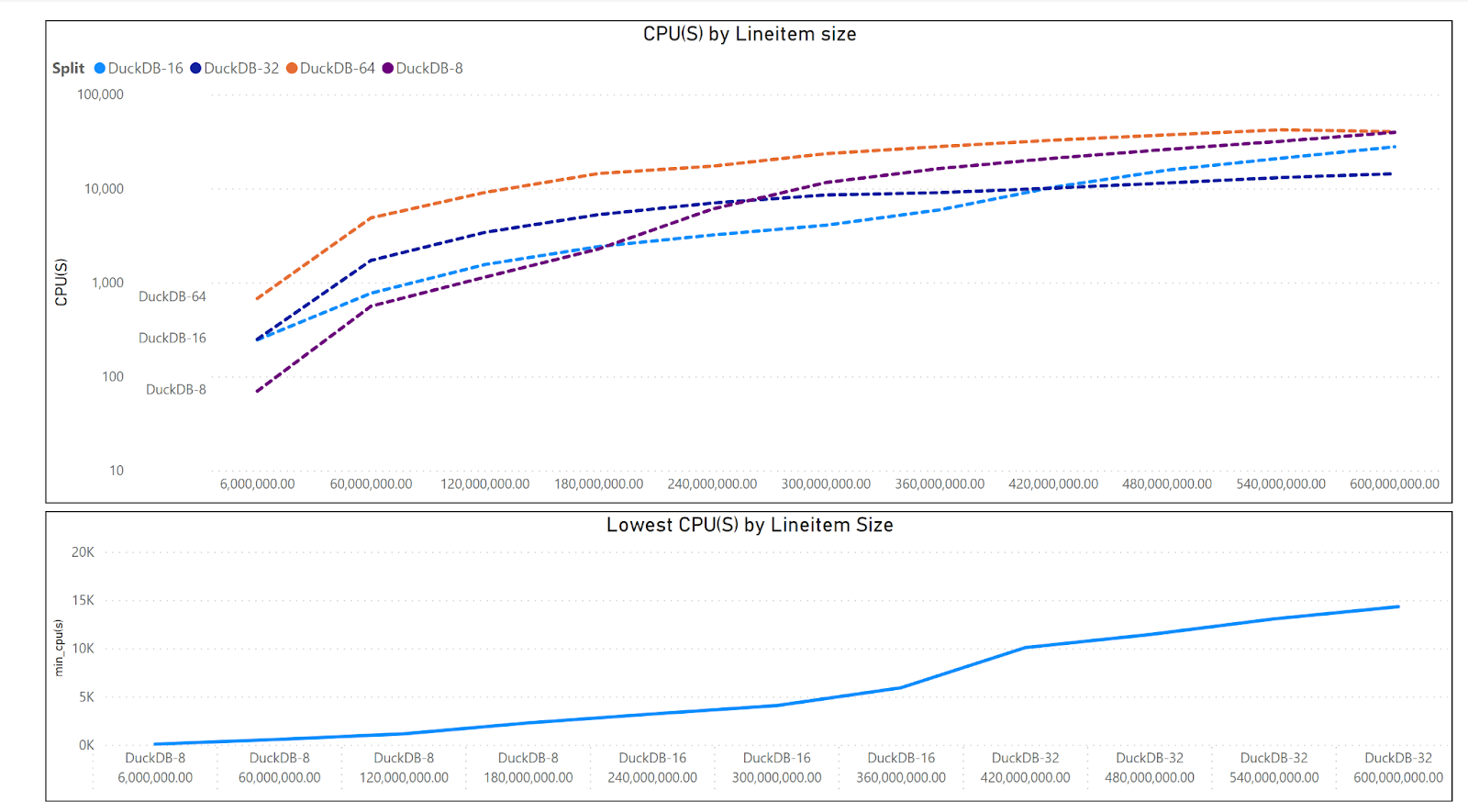
DuckDB using 64 cores is not very efficient for the size of this Data.
Partying Thoughts
- Adding more resources to a problem does not make it necessarily an optimal solution, you get faster duration but it costs way more.
- DuckDB Performance even using half the compute is very intriguing !!!
- Fabric Custom pools are a very fine solution, waiting around 2 minutes is worth it.
- I am no Spark expert, but it will be handy to be able to configure at runtime a smaller Executor compute, in that case, DuckDB will be cheaper option for all sizes up to 100 GB and maybe more.
 The reality is the Lakehouse in Fabric is totally open and there is no consistency guaranty at all even for a single table, all you need is to have the proper access to the workspace which give you access to the storage layer, then you can simply delete the folder and mess with any Delta table, that’s not a bad thing, it give you a maximum freedom to do stuff like Writing Data using different Engines or just upload directly to the “managed” Table area.
The reality is the Lakehouse in Fabric is totally open and there is no consistency guaranty at all even for a single table, all you need is to have the proper access to the workspace which give you access to the storage layer, then you can simply delete the folder and mess with any Delta table, that’s not a bad thing, it give you a maximum freedom to do stuff like Writing Data using different Engines or just upload directly to the “managed” Table area.

 and it seems Table stats are created too at ingestion time, but you pay for the DWH usage. Don’t forget the Data is still in the Delta Table Format, so it can be read by Any compatible Engine ( when reading directly from the storage)
and it seems Table stats are created too at ingestion time, but you pay for the DWH usage. Don’t forget the Data is still in the Delta Table Format, so it can be read by Any compatible Engine ( when reading directly from the storage)